 Campus
Campus
Diagrama de temas
-
-
En esta sección, profundizaremos en una de las tareas más esenciales y versátiles del aprendizaje automático: la clasificación. La clasificación es el proceso de categorizar datos en clases específicas, basándose en una serie de características o atributos. Este enfoque es fundamental para resolver problemas en diversas áreas, como la detección de fraudes, diagnósticos médicos, reconocimiento de voz, clasificación de imágenes, análisis de sentimientos, entre otros.
A lo largo de esta sección, exploraremos los fundamentos de la clasificación y analizaremos los algoritmos más destacados para abordarla, como los Árboles de Decisión, k-Vecinos más Cercanos (k-NN), Regresión Logística, Máquinas de Vectores de Soporte (SVM) y Redes Neuronales Artificiales. Cada lección incluirá una explicación detallada de los métodos, sus aplicaciones prácticas y las ventajas y limitaciones de cada técnica. Al final de esta sección, contarás con un conjunto sólido de herramientas para abordar problemas de clasificación en diversos contextos.
En esta sección, veremos los siguientes temas:
- Repaso: ¿Qué es la clasificación?
- Árboles de Decisión
- k-Vecinos más Cercanos
- Regresión Logística (más orientada a la clasificación binaria)
- Máquinas de Vectores de Soporte (SVM)
- Redes Neuronales Artificiales
-
La clasificación es una tarea del aprendizaje automático supervisado que consiste en asignar una etiqueta o categoría a una entrada basada en sus características. A diferencia de la regresión, que predice valores continuos, la clasificación trabaja con clases discretas. El objetivo es encontrar un límite o conjunto de reglas que separe los datos en diferentes grupos.
Por ejemplo, en un problema de detección de correo no deseado, el modelo de clasificación toma un correo electrónico como entrada y lo clasifica como "spam" o "no spam". Otros ejemplos incluyen el diagnóstico médico ("enfermo" o "sano"), la detección de objetos en imágenes ("gato", "perro", "persona"), y la identificación de transacciones fraudulentas ("fraude" o "legítimo").
Tipos de Clasificación:
- Clasificación Binaria: Involucra solo dos categorías posibles, como "aprobado" o "reprobado".
- Clasificación Multiclase: Incluye tres o más categorías, como clasificar las especies de flores en "setosa," "versicolor," o "virginica."
- Clasificación Multietiqueta: Una instancia puede pertenecer simultáneamente a múltiples categorías. Por ejemplo, un artículo de noticias puede clasificarse tanto en "economía" como en "tecnología."
Cómo Funciona la Clasificación
En un problema de clasificación, el modelo se entrena utilizando un conjunto de datos etiquetados, es decir, ejemplos que ya han sido clasificados correctamente. Durante el proceso de entrenamiento, el modelo aprende a reconocer patrones y relaciones en los datos que le permitan predecir la etiqueta correcta para nuevas instancias no vistas.
Los algoritmos de clasificación difieren en la forma en que encuentran estos patrones y los aplican para hacer predicciones. Algunos métodos, como los Árboles de Decisión, crean reglas explícitas basadas en los valores de las características. Otros, como las Redes Neuronales, utilizan modelos matemáticos complejos para aprender representaciones internas de los datos.
Métricas de Evaluación en Clasificación
Una parte esencial de trabajar con problemas de clasificación es evaluar la precisión y el rendimiento del modelo. Algunas de las métricas más comunes son:
- Exactitud (Accuracy): La proporción de predicciones correctas entre el total de predicciones.
- Precisión (Precision): La proporción de verdaderos positivos entre todas las instancias predichas como positivas.
- Exhaustividad (Recall): La proporción de verdaderos positivos entre todas las instancias que son realmente positivas.
- Puntuación F1: La media armónica de la precisión y la exhaustividad, que proporciona un balance entre ambas.
- Matriz de Confusión: Una tabla que muestra la cantidad de verdaderos positivos, falsos positivos, verdaderos negativos y falsos negativos.
Conclusiones
La clasificación es una tarea central en el aprendizaje automático con aplicaciones en una amplia variedad de campos. Entender cómo funciona la clasificación y qué algoritmos utilizar en cada situación es crucial para abordar problemas complejos de categorización de datos. Al elegir el algoritmo y las métricas de evaluación adecuadas, podemos construir modelos efectivos para realizar predicciones precisas.
-
Los Árboles de Decisión son un algoritmo de clasificación que utiliza un modelo de estructura jerárquica en forma de árbol para tomar decisiones. En cada nodo del árbol, se evalúa una condición o regla basada en una característica de los datos, y se bifurca en ramas hasta llegar a un nodo final que representa la clase o categoría.
Cómo Funciona un Árbol de Decisión
Un árbol de decisión divide el conjunto de datos en subconjuntos más pequeños mediante reglas basadas en las características más importantes. El proceso comienza en la raíz del árbol y, en cada nodo, selecciona la característica que mejor separa las clases. Este proceso se repite hasta que todas las ramas terminan en nodos hoja, que representan las categorías finales.
La métrica más común para decidir qué característica dividir en un nodo es la ganancia de información o el índice Gini, que mide la pureza de los subconjuntos resultantes. La característica que maximiza la ganancia de información o minimiza la impureza es seleccionada para dividir el nodo.
Ventajas y Desventajas
Ventajas:
- Interpretabilidad: Las reglas generadas son claras y fáciles de entender.
- Versatilidad: Puede manejar tanto datos categóricos como numéricos.
- No requiere escalamiento de datos: A diferencia de otros métodos, los árboles de decisión no necesitan normalizar o escalar las características.
Desventajas:
- Propenso al sobreajuste: Un árbol demasiado profundo puede ajustarse demasiado a los datos de entrenamiento, afectando la capacidad de generalizar.
- Inestabilidad: Pequeños cambios en los datos pueden resultar en cambios significativos en la estructura del árbol.
Conclusiones
Los árboles de decisión son una herramienta poderosa y fácil de interpretar para la clasificación. Son especialmente útiles cuando se necesita una representación clara de cómo se toman las decisiones. Sin embargo, para evitar problemas como el sobreajuste, se deben aplicar técnicas de poda o utilizar variantes más avanzadas, como los bosques aleatorios.
-
El algoritmo de k-Vecinos más Cercanos es un método sencillo y efectivo para tareas de clasificación. En lugar de construir un modelo explícito durante la fase de entrenamiento, k-NN almacena el conjunto de datos de entrenamiento completo y toma decisiones en función de los ejemplos más cercanos en el espacio de características.
Cómo Funciona k-NN
Para clasificar una nueva instancia, k-NN busca los k ejemplos más cercanos en el conjunto de datos de entrenamiento utilizando una métrica de distancia, como la distancia euclidiana. La clase más común entre estos vecinos determina la categoría asignada a la nueva instancia. El valor de k es un hiperparámetro que debe ajustarse de acuerdo con el problema.
Ventajas y Desventajas
Ventajas:
- Simplicidad: Fácil de entender e implementar.
- Flexibilidad: No asume una forma particular de la relación entre características y clases.
Desventajas:
- Costoso computacionalmente: La predicción requiere calcular la distancia entre la nueva instancia y todos los ejemplos de entrenamiento.
- Sensibilidad al ruido: Los datos atípicos pueden influir en la clasificación.
Conclusiones
El algoritmo k-NN es útil para problemas donde la relación entre las características y las clases no es lineal ni fácil de modelar. Sin embargo, su eficacia depende del valor adecuado de k y de la elección de la métrica de distancia, y puede ser ineficiente con conjuntos de datos muy grandes. -
Aunque su nombre incluya el término "regresión", la regresión logística se utiliza principalmente para problemas de clasificación binaria, no para predicciones de valores continuos como en la regresión lineal o polinomial. Su objetivo es modelar la probabilidad de que una instancia pertenezca a una de dos categorías posibles. Es especialmente útil cuando queremos predecir la presencia o ausencia de una característica o evento, como si un cliente hará una compra ("sí" o "no") o si una persona padece una enfermedad ("positivo" o "negativo").
Fundamentos de la Regresión Logística
La regresión logística calcula la probabilidad de que la variable dependiente yyy sea igual a 1 (es decir, que el evento ocurra) dadas ciertas variables independientes. La fórmula principal utilizada en la regresión logística es:
Donde:
- p es la probabilidad de que la variable dependiente sea 1 (por ejemplo, "sí", "positivo", "compra realizada").
- e es la base del logaritmo natural, aproximadamente igual a 2.718.
- b0 y b1 son los coeficientes del modelo, ajustados durante el proceso de entrenamiento.
- x es la variable independiente o el conjunto de variables independientes que afectan la probabilidad de ocurrencia.
La función utilizada en la regresión logística se denomina función sigmoide o función logística. Esta función transforma cualquier valor de entrada (que puede ir de −∞ a +∞) en una salida que siempre se encuentra en el rango de 0 a 1, lo que permite interpretarla como una probabilidad.
Cómo Funciona la Regresión Logística
- Modelado Lineal: Al igual que la regresión lineal, la regresión logística comienza con un modelo lineal de la forma b0+b1x. Sin embargo, este valor puede ser cualquier número real, lo cual no es adecuado cuando necesitamos una probabilidad que esté entre 0 y 1.
- Transformación No Lineal: Para convertir el valor lineal en una probabilidad, se utiliza la función sigmoide:
Esta función comprime el rango de valores posibles a un intervalo entre 0 y 1, lo que permite interpretar la salida como la probabilidad de pertenencia a una clase específica (por ejemplo, "positivo").
3. Clasificación: Para tomar una decisión final sobre a qué clase pertenece una instancia, se establece un umbral. El valor predeterminado es generalmente 0.5. Si la probabilidad calculada es mayor o igual a 0.5, el resultado se clasifica como 1 (el evento ocurre). Si es menor, se clasifica como 0 (el evento no ocurre). Este umbral puede ajustarse según la naturaleza del problema y los costos asociados a los errores de clasificación.
Interpretación de los Coeficientes
Los coeficientes b0,b1,…,bn en la regresión logística se interpretan en términos de probabilidades y odds ratios:
- Odds: Representa la razón de la probabilidad de que ocurra el evento frente a la probabilidad de que no ocurra.
- Odds ratio: El coeficiente bib_ibi indica cómo cambia el logaritmo de las odds cuando la variable independiente xi aumenta en una unidad, manteniendo las otras variables constantes.
Por ejemplo, si el coeficiente b1 para una variable de ingreso en un modelo de predicción de compras es positivo, significa que un aumento en el ingreso se asocia con un incremento en la probabilidad de que ocurra la compra.
Función de Costo: La Entropía Cruzada
En la regresión logística, la función de costo que se utiliza no es el Error Cuadrático Medio (MSE) como en la regresión lineal, sino la entropía cruzada o log-loss. Esta función mide la diferencia entre las probabilidades predichas y las etiquetas reales, penalizando de forma más severa las predicciones incorrectas de alta confianza.
La función de costo se define como:
Donde:
- N es el número total de muestras.
- yi es la etiqueta real (0 o 1).
- pi es la probabilidad predicha para la muestra iii.
La minimización de esta función durante el entrenamiento ajusta los coeficientes b0,b1,…,bn para que el modelo sea lo más preciso posible.
Aplicaciones Comunes de la Regresión Logística
La regresión logística es ampliamente utilizada en una variedad de campos y problemas que involucran clasificaciones binarias, tales como:
- Detección de Fraudes: Determinar si una transacción es fraudulenta o legítima.
- Diagnósticos Médicos: Predecir si un paciente padece o no una enfermedad basada en sus características médicas (como síntomas o resultados de pruebas).
- Marketing: Predecir si un cliente potencial realizará una compra en función de su perfil demográfico y comportamiento previo.
- Análisis de Riesgo: Evaluar la probabilidad de que un prestatario incumpla un préstamo.
- Clasificación de Correos Electrónicos: Identificar si un correo es spam o no spam.
Ventajas y Limitaciones de la Regresión Logística
Ventajas:
- Simplicidad: Es relativamente fácil de implementar y entrenar, especialmente en problemas con un número limitado de características.
- Interpretabilidad: Los coeficientes pueden interpretarse en términos de la influencia de las variables independientes en la probabilidad de ocurrencia del evento.
- Probabilística: Ofrece no solo una predicción de clase, sino también una probabilidad, lo que permite evaluar el grado de certeza de cada predicción.
- Flexibilidad: Puede extenderse a problemas de clasificación multiclase mediante técnicas como la regresión logística multinomial o "softmax".
Limitaciones:
- Linealidad: Asume una relación lineal entre las variables independientes y el logaritmo de las odds, lo que puede no ser adecuado para problemas con relaciones más complejas.
- Clasificación Binaria: Está diseñada principalmente para clasificaciones binarias. Aunque se puede adaptar a problemas multiclase, hay métodos más específicos para esos casos.
- Sensibilidad a Valores Atípicos: Los valores atípicos extremos en las variables independientes pueden afectar los coeficientes y, por ende, las predicciones.
- No Modela Relaciones No Lineales Directamente: Aunque puede incluir variables transformadas (como cuadráticas o cúbicas) para modelar relaciones no lineales, esto se hace de forma indirecta y puede requerir ajustes adicionales.
Ejemplo Práctico: Aplicación de la Regresión Logística
Supongamos que estamos construyendo un modelo para predecir si un cliente realizará una compra en línea (1) o no (0). Las variables independientes incluyen el tiempo que pasa en el sitio web, la cantidad de artículos en el carrito, y si ha realizado compras previas. Al entrenar el modelo, la regresión logística asignará coeficientes a estas variables que reflejen su impacto en la probabilidad de compra. Por ejemplo, un tiempo mayor en el sitio web podría aumentar la probabilidad de realizar una compra.
Tras el entrenamiento, el modelo utilizará la función sigmoide para convertir las combinaciones lineales de estas características en una probabilidad. Si esta probabilidad es mayor al umbral establecido (por ejemplo, 0.5), se clasificará como "compra realizada".
Conclusiones
La regresión logística es una herramienta esencial para problemas de clasificación binaria, capaz de transformar valores continuos en probabilidades y, a su vez, clasificar datos en una de dos categorías posibles. Su simplicidad y flexibilidad la convierten en uno de los métodos más utilizados en tareas de predicción en diferentes campos. A través de la función sigmoide, puede manejar de forma efectiva relaciones entre variables independientes y la probabilidad de ocurrencia de un evento. Sin embargo, se debe tener en cuenta sus limitaciones, especialmente en casos donde las relaciones entre variables sean más complejas y no lineales. La regresión logística agrega una nueva dimensión al conjunto de herramientas de modelado predictivo, proporcionando una base sólida para el análisis y la clasificación de datos.
-
Las Máquinas de Vectores de Soporte (SVM) son algoritmos de clasificación que buscan encontrar el hiperplano óptimo que maximiza el margen entre las clases en el espacio de características. Las SVM son especialmente efectivas en problemas donde las clases son separables de forma lineal, pero también se pueden adaptar a problemas no lineales mediante el uso de núcleos (kernels).
Cómo Funciona una SVM
El objetivo de una SVM es encontrar un hiperplano que divida el espacio de características en dos regiones separadas por un margen lo más amplio posible. Las instancias más cercanas al hiperplano, llamadas vectores de soporte, determinan la posición y orientación del hiperplano.
Para problemas no lineales, SVM utiliza funciones de núcleo para transformar los datos a un espacio de mayor dimensión, donde se pueden separar linealmente.
Ejemplos de funciones de núcleo incluyen el polinomial, el radial de base gaussiana (RBF), y el sigmoide. Estas funciones permiten que las SVM encuentren un límite de decisión no lineal en el espacio original, lo que amplía significativamente su aplicabilidad a problemas complejos.
Ventajas y Desventajas
Ventajas:
- Eficacia en problemas de alta dimensionalidad: Las SVM funcionan bien incluso cuando el número de características es mayor que el número de muestras.
- Solución única: El problema de optimización que resuelve la SVM garantiza un mínimo global, lo que significa que hay menos riesgo de quedarse atrapado en mínimos locales.
- Flexibilidad con funciones de núcleo: Permite abordar problemas no lineales utilizando funciones de transformación del espacio de características.
Desventajas:
- Costoso computacionalmente: El entrenamiento de una SVM puede ser lento, especialmente con conjuntos de datos muy grandes.
- Difícil de interpretar: Aunque el modelo subyacente es matemáticamente sólido, puede ser menos intuitivo y más difícil de interpretar que otros métodos como los árboles de decisión.
- Elección del núcleo: La selección de la función de núcleo adecuada y sus parámetros puede ser compleja y requiere ajuste fino.
Aplicaciones
Las SVM son ampliamente utilizadas en problemas de clasificación binaria como:
- Detección de fraude: Clasificar transacciones como fraudulentas o legítimas.
- Reconocimiento de imágenes: Clasificar imágenes en categorías (por ejemplo, "gato" o "perro").
- Diagnóstico médico: Identificar la presencia o ausencia de enfermedades basadas en registros médicos.
Conclusiones
Las Máquinas de Vectores de Soporte son herramientas poderosas para la clasificación, especialmente en problemas de alta dimensionalidad o con fronteras de decisión complejas. Su flexibilidad para abordar problemas no lineales mediante funciones de núcleo las hace versátiles, pero su implementación requiere una cuidadosa selección de parámetros y funciones. A pesar de sus desafíos, las SVM siguen siendo una elección sólida para una variedad de problemas de clasificación, destacando por su precisión y robustez.
-
Las Redes Neuronales Artificiales (RNA) son un conjunto de algoritmos inspirados en la estructura y funcionamiento del cerebro humano. Están diseñadas para aprender patrones complejos a partir de los datos mediante capas de neuronas interconectadas que transforman las entradas en salidas. Las RNA son especialmente útiles en problemas de clasificación complejos donde las relaciones entre las características y las clases no son lineales ni obvias.
Estructura Básica de una Red Neuronal
Una red neuronal se compone de:
- Capa de entrada: Recibe las características del conjunto de datos.
- Capas ocultas: Procesan las entradas mediante neuronas que aplican funciones de activación no lineales. El número de capas ocultas y de neuronas en cada capa determina la capacidad de la red para aprender patrones complejos.
- Capa de salida: Genera la predicción final, que puede ser una probabilidad o una categoría.
Cada neurona toma una combinación lineal de las entradas y aplica una función de activación (como ReLU, sigmoide o softmax) para introducir no linealidades, lo que permite a la red aprender patrones complejos.
Entrenamiento de la Red Neuronal
El proceso de entrenamiento de una red neuronal implica ajustar los pesos de las conexiones entre las neuronas para minimizar la función de pérdida, que mide la diferencia entre las predicciones de la red y las etiquetas reales. Este ajuste se realiza mediante un proceso iterativo llamado retropropagación, combinado con algoritmos de optimización como el Gradiente Descendente.
Ventajas y Desventajas
Ventajas:
- Capacidad de modelar relaciones complejas: Las RNA son capaces de aprender patrones no lineales y complejos en los datos.
- Aplicación en múltiples dominios: Son aplicables a problemas de clasificación de imágenes, reconocimiento de voz, análisis de textos, y muchos más.
Desventajas:
- Requiere grandes cantidades de datos: Las RNA necesitan grandes volúmenes de datos para aprender de manera efectiva y evitar el sobreajuste.
- Costoso computacionalmente: El entrenamiento de redes neuronales profundas puede ser muy intensivo en términos de tiempo y recursos computacionales.
- Difícil de interpretar: Las RNA son a menudo consideradas como "cajas negras" debido a la complejidad de los patrones que aprenden, lo que dificulta la explicación de sus decisiones.
Aplicaciones
Las Redes Neuronales Artificiales son utilizadas en una amplia variedad de aplicaciones:
- Reconocimiento de imágenes: Clasificar imágenes en diferentes categorías (por ejemplo, "gato" o "perro").
- Análisis de sentimientos: Clasificar textos según su tono (positivo, negativo, neutral).
- Diagnóstico médico: Clasificar imágenes médicas (por ejemplo, para detectar tumores en radiografías).
Conclusiones
Las Redes Neuronales Artificiales son una poderosa herramienta para resolver problemas de clasificación complejos, especialmente cuando los patrones en los datos son no lineales y difíciles de modelar con otros algoritmos. A pesar de los desafíos asociados con su entrenamiento y la necesidad de grandes conjuntos de datos, las RNA han demostrado ser increíblemente efectivas en una variedad de aplicaciones del mundo real. Su capacidad para aprender representaciones complejas hace que sean una elección fundamental en el aprendizaje automático moderno.
-
Vamos a realizar una experiencia práctica para predecir la posibilidad de tener diabetes en base a resultados médicos, utilizando la regresión logística.
-
-
-
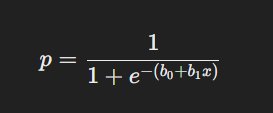
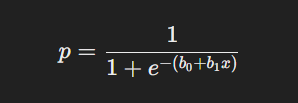
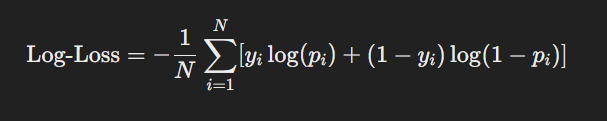
 Campus
Campus
