 Campus
Campus
Diagrama de temas
-
-
En esta sección, profundizaremos en el concepto de regresión, una de las técnicas más importantes en el aprendizaje automático supervisado. Si bien anteriormente introdujimos la regresión de manera superficial, en esta sección nos adentraremos en los diferentes tipos de regresión, cómo funcionan, y sus aplicaciones prácticas. Veremos en detalle las bases matemáticas de la regresión lineal, la regresión polinomial y la regresión logística, así como los escenarios ideales para aplicar cada una de estas técnicas.
Al final de esta sección, estarás capacitado para:
- Comprender cómo los diferentes métodos de regresión modelan relaciones entre variables.
- Aplicar algoritmos de regresión en diversos contextos.
- Evaluar y ajustar modelos de regresión para mejorar su rendimiento.
Las lecciones de esta sección son:
- ¿Qué es la regresión?
- Regresión lineal
- Regresión polinomial
- Regresión logística
-
La regresión es un método estadístico y una técnica clave en el aprendizaje automático supervisado que se utiliza para modelar y analizar la relación entre una variable dependiente (también conocida como variable objetivo o respuesta) y una o más variables independientes (también conocidas como variables predictoras o características). A diferencia de la clasificación, donde el objetivo es predecir categorías o clases discretas (como "spam" o "no spam"), la regresión se enfoca en predecir valores continuos. Este enfoque permite estimar la magnitud, intensidad o nivel de un determinado fenómeno, basándose en las características conocidas de los datos de entrada.
¿Por qué es importante la regresión?
La regresión es fundamental en diversos campos de aplicación, ya que ofrece una forma de comprender y cuantificar las relaciones entre variables. Por ejemplo:
- Economía: Para predecir el crecimiento económico basándose en variables como la tasa de interés, la inversión y el gasto público.
- Medicina: Para estimar la progresión de una enfermedad en función de factores como la edad, hábitos de vida y antecedentes médicos.
- Meteorología: Para pronosticar temperaturas, precipitaciones o niveles de contaminación atmosférica.
- Finanzas: Para proyectar el valor futuro de activos financieros, como acciones o bonos, utilizando datos históricos y factores económicos.
El poder de la regresión radica en su capacidad para encontrar la relación subyacente entre las variables y predecir resultados basados en patrones aprendidos de los datos.
Cómo funciona la regresión
En su forma más simple, la regresión busca modelar la relación entre la variable dependiente yyy y una o más variables independientes x1,x2,…,xn utilizando una función matemática. La relación se puede expresar como:
Aquí, f(x1,x2,…,xn) es la función que describe la relación entre las variables, y ϵ representa un término de error o ruido, que abarca las posibles variaciones no explicadas por las variables independientes.
Tipos comunes de regresión
La regresión se puede aplicar de varias formas, dependiendo de la naturaleza de la relación entre las variables y el tipo de problemas que se quiere resolver. Los tipos más comunes son:
- Regresión Lineal: La regresión lineal modela la relación entre las variables independientes y la variable dependiente como una línea recta.
- Regresión Polinomial: La regresión polinomial es una extensión de la regresión lineal que permite modelar relaciones no lineales entre las variables.
- Regresión Logística: Aunque su nombre puede ser confuso, la regresión logística se utiliza para problemas de clasificación, no para predecir valores continuos. La regresión logística se aplica para modelar la probabilidad de que un evento binario ocurra, por ejemplo, si un paciente tiene o no una enfermedad.
Cuándo usar cada tipo de regresión
- Regresión lineal: Cuando existe una relación lineal clara entre las variables. Por ejemplo, predecir el salario de una persona basado en sus años de experiencia.
- Regresión polinomial: Cuando los datos muestran una relación no lineal. Por ejemplo, modelar la trayectoria de un objeto lanzado, que sigue una curva parabólica.
- Regresión logística: Cuando se desea predecir la probabilidad de un evento binario. Por ejemplo, clasificar correos electrónicos como "spam" o "no spam".
Conclusiones
La regresión es una herramienta fundamental en el aprendizaje automático supervisado que permite modelar y cuantificar la relación entre variables para predecir valores numéricos. Existen varios tipos de regresión, cada uno adecuado para distintos tipos de problemas. La regresión lineal es útil para relaciones sencillas, la regresión polinomial para relaciones más complejas y curvas, mientras que la regresión logística se especializa en problemas de clasificación binaria. Comprender estos tipos de regresión y cuándo aplicarlos es clave para abordar una amplia variedad de problemas en inteligencia artificial y análisis de datos. -
La regresión lineal es uno de los métodos más básicos y ampliamente utilizados en estadística y aprendizaje automático para modelar la relación entre una variable dependiente yyy y una o más variables independientes x1,x2,…,xnx_1, x_2, \dots, x_nx1,x2,…,xn. Su simplicidad y claridad para interpretar las relaciones hacen que sea una de las primeras técnicas que se aprenden al abordar problemas de predicción continua.
Fundamentos de la Regresión Lineal
La forma más simple de la regresión lineal es la regresión lineal simple, donde se modela la relación entre una variable dependiente yyy y una única variable independiente xxx mediante una línea recta. La ecuación general para la regresión lineal simple es:
Donde:
- y es la variable dependiente o respuesta, el valor que se quiere predecir.
- x es la variable independiente o predictor.
- b0 es la intersección con el eje y (es decir, el valor de y cuando x es cero).
- b1 es la pendiente de la línea, que indica el cambio en y por cada unidad de cambio en x.
- ϵ es el término de error o ruido, que representa las variaciones en y no explicadas por x.
En el caso de regresión lineal múltiple, se incluyen múltiples variables independientes x1,x2,…,xn:
Aquí, cada bi representa el impacto de la correspondiente variable independiente xi en la variable dependiente y, manteniendo constante el efecto de las demás variables.
Cómo Funciona la Regresión Lineal
El objetivo de la regresión lineal es encontrar la línea (en el caso simple) o el hiperplano (en el caso múltiple) que mejor se ajuste a los datos. Este "mejor ajuste" se determina minimizando una función de error, comúnmente el Error Cuadrático Medio (MSE), que se define como:
Donde:
- n es el número de observaciones.
- yi es el valor real de la variable dependiente para la observación iii.
- y^i-i es el valor predicho por el modelo para la observación iii.
Minimizando el MSE, el algoritmo de regresión lineal ajusta los coeficientes b0,b1,…,bn para que la línea o hiperplano calculado se acerque lo más posible a los puntos de datos.
Cálculo de los Coeficientes
El proceso de ajuste de los coeficientes en la regresión lineal se puede resolver mediante un enfoque algebraico, utilizando la fórmula de mínimos cuadrados. Para la regresión lineal simple, los coeficientes b0 y b1 se calculan como:
Donde xˉ y yˉ son las medias de las variables independientes y dependientes, respectivamente.
En la regresión lineal múltiple, los coeficientes se obtienen mediante métodos de optimización o álgebra lineal, resolviendo un sistema de ecuaciones que minimiza el error cuadrático total.
Supuestos de la Regresión Lineal
Para que la regresión lineal produzca resultados fiables y significativos, deben cumplirse ciertos supuestos fundamentales:
- Linealidad: Existe una relación lineal entre las variables independientes y la variable dependiente.
- Independencia: Las observaciones son independientes entre sí. No debe haber correlación entre los errores.
- Homocedasticidad: La varianza de los errores debe ser constante a lo largo de los valores de las variables independientes.
- Normalidad: Los errores deben estar distribuidos de manera aproximadamente normal.
Si estos supuestos se violan, los resultados de la regresión lineal pueden no ser fiables, y podría ser necesario aplicar otras técnicas o transformaciones de datos.
Aplicaciones de la Regresión Lineal
La simplicidad y claridad interpretativa de la regresión lineal la hacen aplicable a una amplia variedad de problemas del mundo real:
- Predicción de precios: Utilizada en bienes raíces para estimar el precio de una vivienda basándose en características como su tamaño, ubicación y número de habitaciones.
- Análisis de ventas: Ayuda a predecir las ventas futuras de un producto en función de factores como el precio, la publicidad y la época del año.
- Estudio de tendencias: En economía, para analizar la relación entre el consumo y factores como el ingreso y la tasa de interés.
- Ingeniería: Para modelar el desgaste de materiales o el rendimiento de sistemas en función de variables de entrada.
Ventajas y Limitaciones de la Regresión Lineal
Ventajas:
- Simplicidad: Fácil de entender e interpretar, lo que la hace adecuada como punto de partida para problemas de predicción.
- Eficiencia computacional: El algoritmo es computacionalmente eficiente, incluso para grandes conjuntos de datos.
- Aplicabilidad: Funciona bien cuando hay una relación lineal clara entre las variables, lo que es común en muchas aplicaciones prácticas.
Limitaciones:
- Relaciones no lineales: La regresión lineal no puede capturar relaciones complejas o no lineales entre las variables. En tales casos, se deben utilizar técnicas más avanzadas, como la regresión polinomial o modelos basados en árboles de decisión.
- Sensibilidad a valores atípicos: La regresión lineal puede verse muy afectada por valores atípicos en los datos, que pueden distorsionar la línea de mejor ajuste.
- Supuestos estrictos: Requiere que se cumplan ciertos supuestos (linealidad, independencia, homocedasticidad, normalidad) para que los resultados sean interpretables y fiables.
Variantes de la Regresión Lineal
Existen algunas variantes y extensiones de la regresión lineal que permiten superar ciertas limitaciones:
- Regresión lineal múltiple: Incluye múltiples variables independientes, permitiendo modelar relaciones más complejas.
- Regularización (Ridge y Lasso): Métodos de regresión lineal que añaden un término de penalización para evitar el sobreajuste y manejar problemas de multicolinealidad entre las variables independientes.
Conclusiones
La regresión lineal es una herramienta fundamental en el aprendizaje automático y la estadística, conocida por su simplicidad y eficacia en modelar relaciones lineales entre variables.
- Es ideal para problemas donde se busca predecir un valor continuo basado en uno o más factores y cuando se asume que la relación es aproximadamente lineal.
- Aunque su alcance está limitado por su incapacidad para capturar relaciones no lineales y su sensibilidad a valores atípicos, su claridad interpretativa y su eficiencia la convierten en un excelente punto de partida para el análisis de datos y la construcción de modelos predictivos.
Con una comprensión sólida de la regresión lineal, se está bien preparado para avanzar hacia técnicas más complejas, como la regresión polinomial o el uso de algoritmos más sofisticados en problemas de predicción.
-
La regresión polinomial es una extensión de la regresión lineal que permite modelar relaciones más complejas y no lineales entre la variable dependiente y las variables independientes. Mientras que la regresión lineal asume una relación lineal entre las variables, la regresión polinomial puede capturar tendencias que cambian de dirección o curvatura, haciendo que se ajuste mejor a ciertos conjuntos de datos.
Fundamentos de la Regresión Polinomial
La regresión polinomial se basa en la inclusión de términos polinómicos adicionales en la ecuación de la regresión lineal. La forma general de una regresión polinomial de grado n es:
Donde:
- y es la variable dependiente o respuesta.
- x es la variable independiente o predictor.
- b0,b1,b2,…,bn son los coeficientes del modelo que indican la contribución de cada término polinómico.
- n es el grado del polinomio, que determina la complejidad del modelo y la forma de la curva que se ajusta a los datos.
- ϵ es el término de error o ruido, que representa las variaciones en y no explicadas por los predictores.
En este modelo, los términos x2,x3,…,xn permiten capturar la curvatura y complejidad de la relación entre x e y. Por ejemplo, un polinomio de segundo grado (n=2) puede modelar una curva parabólica, mientras que un polinomio de tercer grado (n=3) puede representar cambios más complejos en la dirección de los datos.
¿Cuándo usar Regresión Polinomial?
La regresión polinomial es útil en situaciones donde los datos muestran una tendencia no lineal que no puede ser capturada adecuadamente por una línea recta. Algunos ejemplos comunes incluyen:
- Crecimiento o disminución acelerada: Modelar fenómenos como la trayectoria de un proyectil, donde la relación entre tiempo y posición es cuadrática.
- Evolución de precios: Predecir la evolución de precios de bienes o activos que muestran cambios en la dirección de la tendencia, como picos y valles.
- Curvas de aprendizaje: Analizar cómo la mejora en el rendimiento depende del tiempo de práctica, donde la tasa de mejora puede disminuir con el tiempo.
Cómo Funciona la Regresión Polinomial
Aunque la regresión polinomial incluye términos no lineales (como x2,x3,…,xn), sigue siendo una forma de regresión lineal desde el punto de vista matemático. Esto se debe a que el modelo es lineal en los coeficientes b0,b1,…,bn. Para entrenar el modelo, el proceso sigue los mismos pasos que la regresión lineal:
- Transformación de los datos: Se crea un conjunto de datos expandido que incluye los términos polinómicos. Por ejemplo, para un polinomio de grado 3, se generan las columnas x,x2,x3.
- Ajuste del modelo: Al igual que en la regresión lineal, el algoritmo minimiza una función de error, generalmente el Error Cuadrático Medio (MSE), para encontrar los coeficientes b0,b1,…,bn que mejor se ajusten a los datos.
- Predicción: El modelo utiliza la ecuación polinómica ajustada para predecir el valor de la variable dependiente para nuevos valores de x.
Elección del Grado del Polinomio
La clave en la regresión polinomial es elegir un grado nnn adecuado. El grado del polinomio determina la complejidad de la curva ajustada a los datos:
- Grado bajo (n = 1 o 2): El modelo es relativamente simple, lo que reduce el riesgo de sobreajuste pero puede no capturar patrones complejos en los datos.
- Grado intermedio (n = 3 o 4): Permite modelar relaciones más complejas con cambios en la dirección, adecuado cuando los datos muestran una tendencia curvada.
- Grado alto (n \geq 5): Puede capturar variaciones intrincadas en los datos. Sin embargo, aumenta el riesgo de sobreajuste, lo que significa que el modelo se ajusta demasiado al conjunto de entrenamiento y falla al generalizar en nuevos datos.
Sobreajuste y Regularización
Uno de los desafíos más importantes de la regresión polinomial es el riesgo de sobreajuste. A medida que se incrementa el grado del polinomio, el modelo puede adaptarse excesivamente a las peculiaridades del conjunto de datos de entrenamiento, incluyendo ruido o valores atípicos, lo que reduce su capacidad para predecir correctamente nuevos datos.
Para mitigar este problema, se pueden aplicar técnicas de regularización, como la regresión de cresta (Ridge) o la regresión Lasso, que penalizan la magnitud de los coeficientes para reducir la complejidad del modelo.
Ejemplo Práctico: Aplicación de la Regresión Polinomial
Supongamos que se desea predecir el rendimiento de un automóvil (consumo de combustible) en función de su velocidad. Al graficar los datos, se observa una curva en forma de "U", indicando que el rendimiento es óptimo a ciertas velocidades y disminuye a velocidades muy bajas o muy altas. Un modelo de regresión lineal simple no capturaría adecuadamente esta relación.
En este caso, la regresión polinomial de grado 2 o 3 puede ajustar una curva que represente mejor esta relación, permitiendo predicciones más precisas del rendimiento a distintas velocidades.
Ventajas y Desafíos de la Regresión Polinomial
Ventajas:
- Captura relaciones complejas: Puede modelar relaciones no lineales que una regresión lineal simple no puede.
- Flexibilidad: Permite ajustar una amplia variedad de curvas a los datos, lo que puede mejorar la precisión de las predicciones en escenarios con patrones complejos.
Desafíos:
- Elección del grado del polinomio: Elegir un grado demasiado bajo puede resultar en un modelo incapaz de capturar la complejidad de los datos (subajuste), mientras que un grado demasiado alto puede conducir al sobreajuste, donde el modelo se ajusta demasiado al ruido en los datos.
- Interpretabilidad: A medida que el grado del polinomio aumenta, la interpretación de los coeficientes se vuelve menos intuitiva, dificultando la explicación del modelo.
- Sensibilidad a valores atípicos: Al igual que la regresión lineal, la regresión polinomial es sensible a valores atípicos que pueden influir desproporcionadamente en la forma de la curva ajustada.
Aplicaciones Comunes de la Regresión Polinomial
- Economía: Para modelar la relación entre oferta y demanda, precios y producción, o curvas de costo que no siguen un patrón lineal.
- Ingeniería: En la predicción del rendimiento de sistemas mecánicos o electrónicos, donde el comportamiento puede variar de manera no lineal con respecto a las condiciones de operación.
- Ciencias naturales: Para analizar fenómenos físicos, como la caída libre de objetos o la propagación de ondas, donde las relaciones no son lineales.
Conclusiones
La regresión polinomial es una poderosa extensión de la regresión lineal que permite capturar relaciones no lineales entre variables. Es especialmente útil en situaciones donde una relación más compleja es evidente, y un modelo lineal no logra un ajuste adecuado. Sin embargo, la elección del grado del polinomio es fundamental para encontrar el equilibrio entre un modelo que sea lo suficientemente flexible para capturar las tendencias de los datos y uno que generalice bien a nuevos conjuntos de datos. La gestión cuidadosa del riesgo de sobreajuste y el uso de técnicas de regularización cuando sea necesario son claves para el uso efectivo de la regresión polinomial en la práctica.
-
Aunque su nombre incluya el término "regresión", la regresión logística se utiliza principalmente para problemas de clasificación binaria, no para predicciones de valores continuos como en la regresión lineal o polinomial. Su objetivo es modelar la probabilidad de que una instancia pertenezca a una de dos categorías posibles. Es especialmente útil cuando queremos predecir la presencia o ausencia de una característica o evento, como si un cliente hará una compra ("sí" o "no") o si una persona padece una enfermedad ("positivo" o "negativo").
Por este motivo, explicaremos regresión logística en la próxima sección.
-
Vamos a realizar una experiencia práctica para predecir el precio de un automóvil utilizando regresión.
-
Link a la experiencia: https://microsoftlearning.github.io/AI-900-AIFundamentals/instructions/02a-create-regression-model.html
-
-
-
-
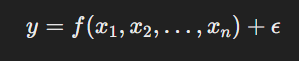
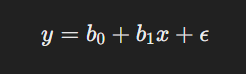

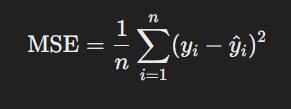
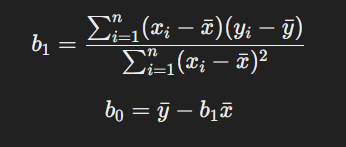
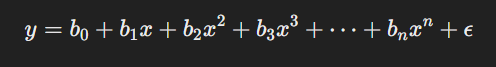
 Campus
Campus
