 Campus
Campus
Diagrama de temas
-
-
En esta sección, exploraremos los principales modelos de inteligencia artificial (IA), que son las herramientas fundamentales para abordar diversas tareas en el ámbito de la IA, desde la predicción y clasificación, hasta la generación de datos y el procesamiento del lenguaje. Cada uno de estos modelos tiene su propio enfoque, ventajas y aplicaciones específicas. Entenderemos cómo funcionan, en qué contextos se utilizan y cómo han sido clave para resolver problemas del mundo real en diferentes campos, como la medicina, el marketing y las ciencias sociales.
A lo largo de esta sección, analizaremos diferentes tipos de modelos de IA, como los de regresión, clasificación, agrupación en clústeres, generación de contenido y procesamiento de lenguaje natural. Cada uno de ellos desempeña un rol crucial en el aprendizaje automático y el desarrollo de sistemas inteligentes.
Temas a tratar en esta sección:
- Modelos de Regresión: Utilizados para predecir valores continuos y analizar la relación entre variables independientes y dependientes.
- Modelos de Clasificación: Empleados para asignar etiquetas o clases a observaciones basadas en sus características.
- Modelos de Agrupación en Clústeres: Técnicas de aprendizaje no supervisado que organizan datos en grupos o clústeres similares.
- Modelos Generativos y GANs: Enfocados en la generación de nuevos datos similares a los datos de entrenamiento, como imágenes o texto.
- Modelos de Lenguaje de Gran Escala (LLMs): Impulsados por la arquitectura de transformers, estos modelos, como GPT y BERT, están revolucionando el procesamiento del lenguaje natural.
Cada lección proporcionará una visión clara y práctica de cómo funcionan estos modelos y en qué situaciones se aplican, ayudando a los estudiantes a desarrollar una comprensión sólida y profunda del vasto mundo de la inteligencia artificial.
-
¿Qué es un modelo de regresión?
Un modelo de regresión es una técnica de aprendizaje automático utilizada para predecir un valor continuo o numérico a partir de una o más variables independientes (o características). Los modelos de regresión buscan encontrar la relación entre las variables de entrada (independientes) y la variable de salida (dependiente), lo que permite hacer predicciones basadas en nuevos datos.
Por ejemplo, si queremos predecir el precio de una vivienda basándonos en características como el tamaño, el número de habitaciones o la ubicación, podemos usar un modelo de regresión para encontrar esta relación.
Tipos comunes de regresión
Existen varios tipos de regresión, cada uno adecuado para diferentes tipos de problemas. A continuación, profundizaremos en tres de los modelos de regresión más comunes: la regresión lineal, la regresión polinomial, y la regresión logística.
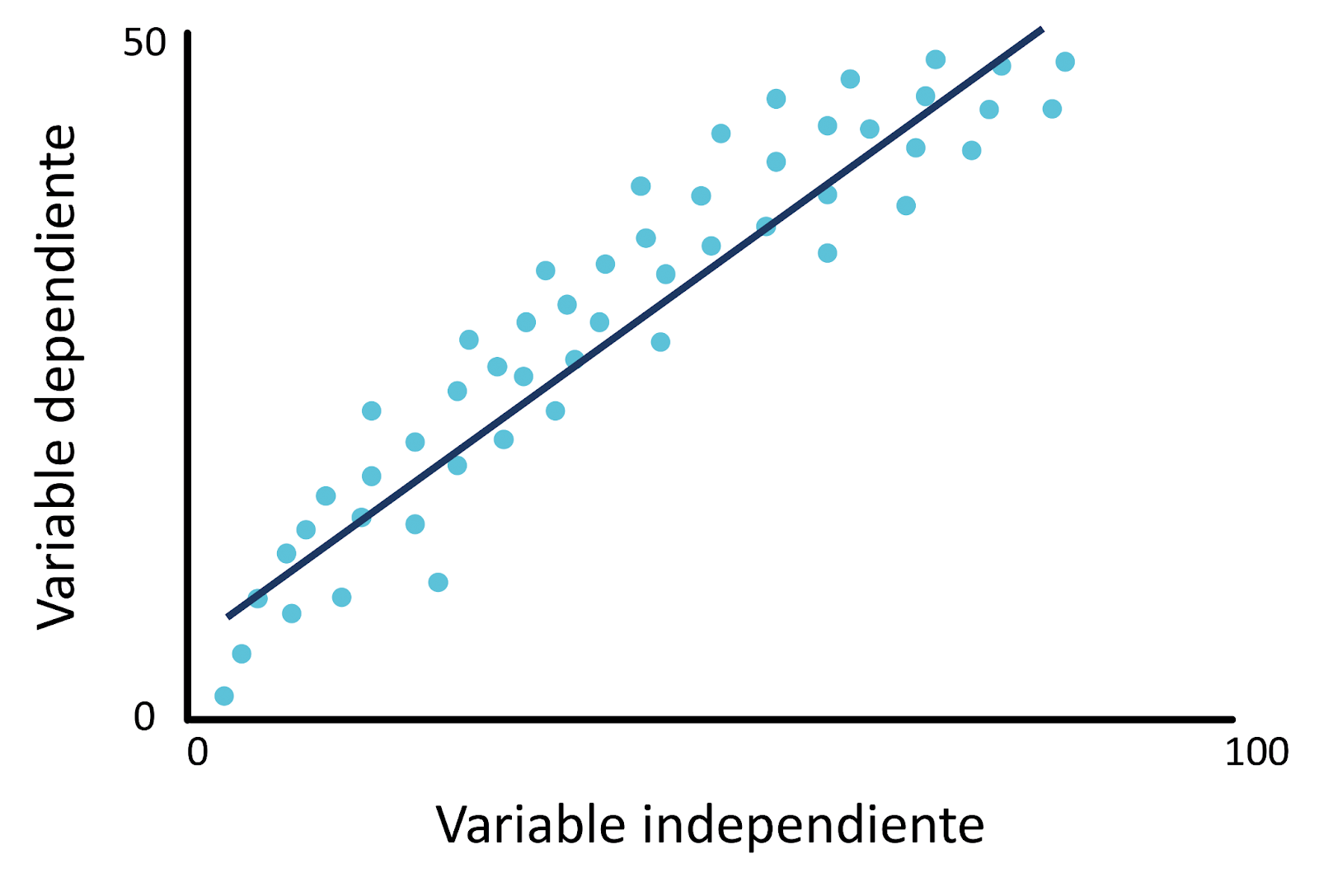
Regresión lineal
La regresión lineal es el modelo más básico y ampliamente utilizado en los problemas de predicción numérica. En su forma más simple, se utiliza cuando existe una relación lineal entre la variable independiente xxx y la variable dependiente yyy. Es decir, la variable de salida es una combinación lineal de las variables de entrada.
La ecuación de la regresión lineal simple (con una sola variable independiente) es:
Donde:
- yyy es la variable dependiente (lo que queremos predecir).
- xxx es la variable independiente (el predictor).
- β0\beta_0β0 es el término de intersección (valor de yyy cuando x=0x = 0x=0).
- β1\beta_1β1 es la pendiente de la línea (representa el cambio en yyy por cada unidad de cambio en xxx).
El objetivo de la regresión lineal es encontrar los valores óptimos de β0\beta_0β0 y β1\beta_1β1 que minimicen la diferencia (error) entre los valores predichos yyy y los valores reales. Este ajuste se realiza comúnmente minimizando el error cuadrático medio (MSE).
Aplicaciones comunes:
- Predicción de ventas basadas en variables como la inversión en marketing.
- Estimación del salario basado en los años de experiencia.
Ventajas:
- Fácil de interpretar y de implementar.
- Funciona bien cuando existe una relación lineal entre las variables.
Desventajas:
- No es adecuada para relaciones no lineales complejas entre las variables.
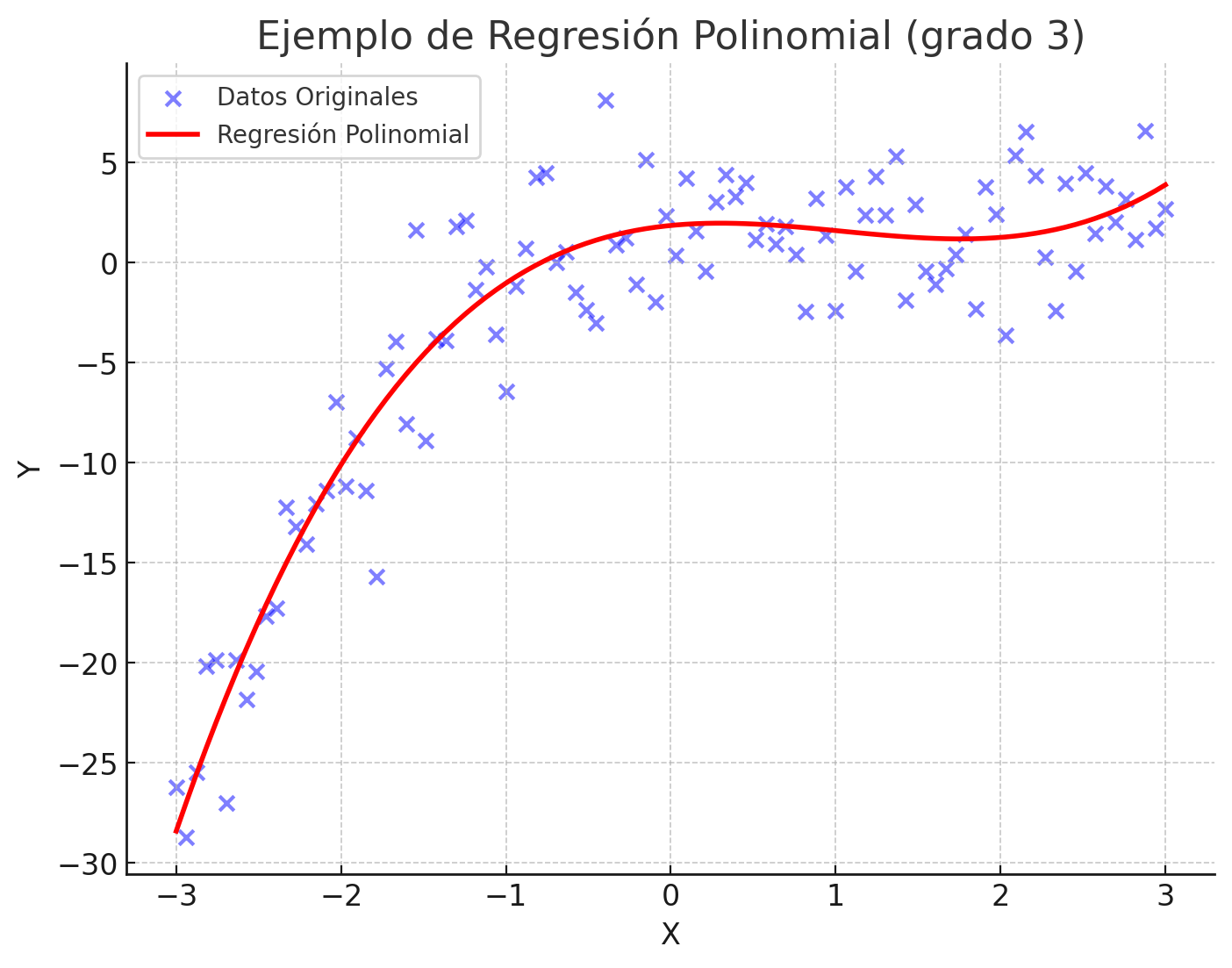
Regresión polinomial
La regresión polinomial es una extensión de la regresión lineal que permite modelar relaciones no lineales entre las variables. En lugar de ajustar una línea recta a los datos, la regresión polinomial ajusta una curva polinómica.
La ecuación de la regresión polinomial de segundo grado (que incluye un término cuadrático) es:
Este tipo de regresión es útil cuando la relación entre la variable independiente y la dependiente es curva, es decir, no puede ser representada adecuadamente con una línea recta. Al incluir términos cuadráticos, cúbicos o de mayor grado, se puede capturar la curvatura de la relación entre las variables.
Aplicaciones comunes:
- Modelar la relación entre la aceleración de un vehículo y la velocidad, donde la aceleración no crece de forma lineal.
- Predecir el crecimiento poblacional, que puede acelerar o desacelerar con el tiempo.
Ventajas:
- Captura relaciones más complejas que la regresión lineal.
- Es flexible al ajustarse a relaciones no lineales.
Desventajas:
- A medida que se agregan más términos, existe el riesgo de sobreajuste (overfitting), donde el modelo se ajusta demasiado a los datos de entrenamiento y no generaliza bien.
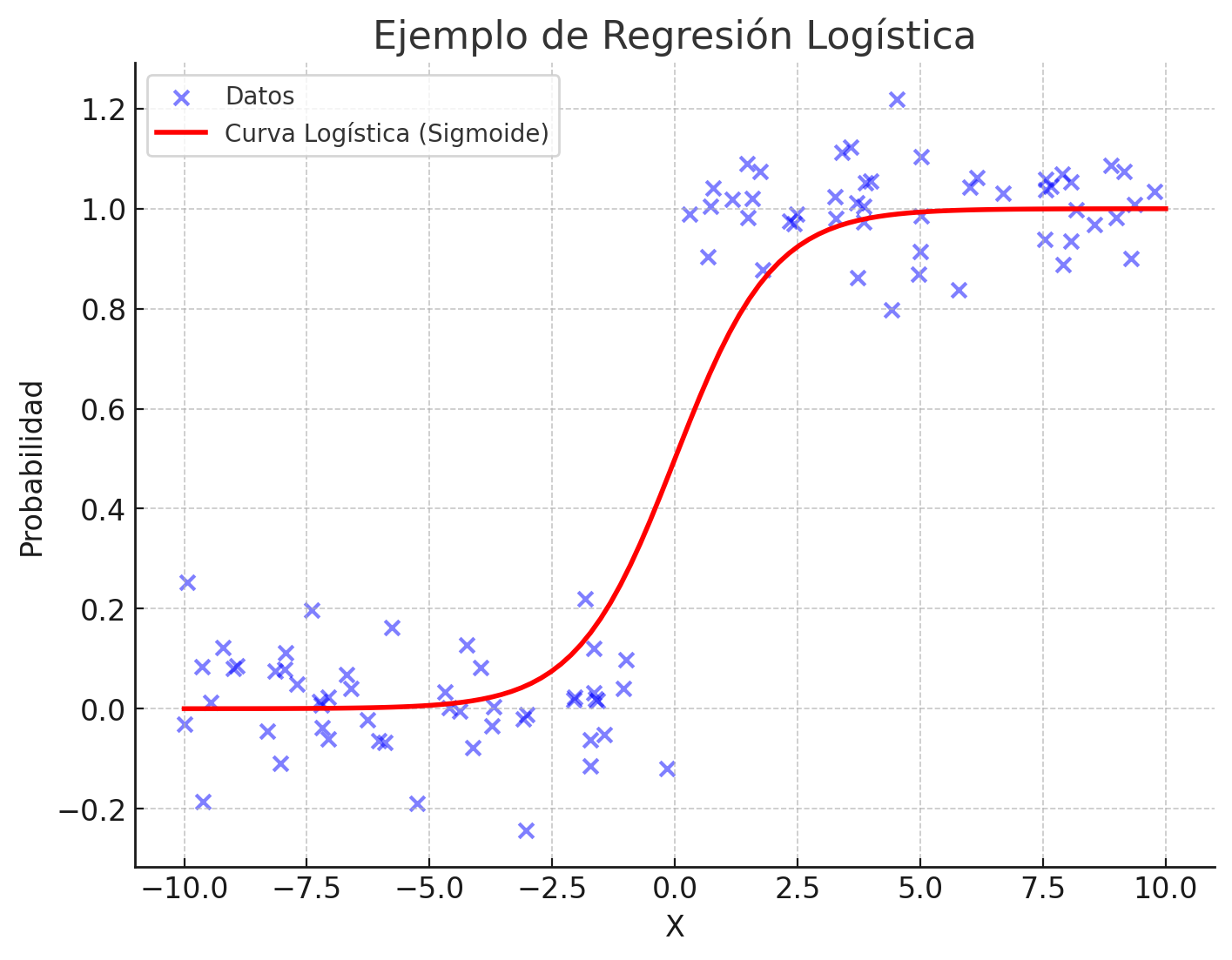
Regresión logística
La regresión logística es un tipo de regresión utilizado cuando la variable dependiente es categórica (es decir, toma valores discretos como "sí/no", "aprobado/reprobado", etc.). A pesar de su nombre, la regresión logística no se utiliza para predecir valores continuos, sino para predecir la probabilidad de que una instancia pertenezca a una de dos categorías.
A diferencia de la regresión lineal, en la regresión logística la salida es una probabilidad que se convierte en una categoría binaria mediante una función logística o sigmoide, cuya forma es:
Esta función sigmoide mapea cualquier valor en una probabilidad entre 0 y 1, lo que permite que la regresión logística sea adecuada para problemas de clasificación binaria.
Aplicaciones comunes:
- Predecir si un paciente tiene una enfermedad (sí/no) basándose en sus características médicas.
- Clasificación de correos electrónicos como spam o no spam.
Ventajas:
- Es adecuada para problemas de clasificación binaria.
- El resultado es una probabilidad, lo que facilita la interpretación.
Desventajas:
- No es adecuada para problemas de regresión continua.
- Solo funciona bien para problemas de clasificación binaria; para más clases, se necesita una extensión como la regresión logística multinomial.
Otros modelos de regresión
Además de los modelos de regresión más comunes (lineal, polinomial y logística), existen otros tipos de regresión que son útiles para casos más complejos:
- Regresión de Crestas (Ridge Regression): Es una técnica que introduce una penalización sobre los coeficientes del modelo lineal. Esta penalización se utiliza para evitar el sobreajuste (overfitting), especialmente en modelos con muchas variables. La regresión de crestas es útil cuando los datos tienen colinealidad, es decir, cuando varias variables independientes están correlacionadas.
- Regresión LASSO (Least Absolute Shrinkage and Selection Operator): Similar a la regresión de crestas, pero en lugar de reducir los coeficientes, puede forzar que algunos de ellos sean exactamente cero. Esto hace que LASSO sea útil para la selección de características, ya que elimina variables menos importantes.
- Regresión de Mínimos Cuadrados Ordinarios (OLS): Este es el método clásico para ajustar un modelo de regresión lineal, minimizando la suma de los errores al cuadrado. Aunque simple, sigue siendo útil en muchos contextos donde la relación entre las variables es lineal.
- Regresión de Soporte Vectorial (SVR): Este modelo utiliza los principios de las máquinas de soporte vectorial (SVM) para predecir valores continuos. Es útil para capturar relaciones no lineales complejas entre las variables.
Conclusiones
Los modelos de regresión son esenciales para comprender y predecir valores continuos, y se aplican en una amplia variedad de campos como la economía, la salud y la ciencia de datos. La regresión lineal es adecuada para relaciones simples, mientras que la regresión polinomial permite capturar relaciones no lineales, y la regresión logística es ideal para problemas de clasificación binaria. -
¿Qué es un modelo de clasificación?
Un modelo de clasificación es una técnica de aprendizaje automático utilizada para asignar una etiqueta o clase a una observación basada en sus características o atributos. A diferencia de los modelos de regresión, que predicen valores continuos, los modelos de clasificación predicen categorías discretas. Por ejemplo, un modelo de clasificación puede predecir si un correo electrónico es "spam" o "no spam", o si un paciente está "enfermo" o "sano".
El objetivo principal de un modelo de clasificación es encontrar patrones en los datos que permitan predecir la clase a la que pertenece una nueva observación. En términos simples, los modelos de clasificación responden a preguntas de tipo "¿A qué categoría pertenece esta observación?".
Tipos comunes de clasificación
Existen varios algoritmos de clasificación que se utilizan según la naturaleza del problema y los datos. A continuación, exploraremos algunos de los modelos más comunes utilizados para problemas de clasificación.
Árboles de Decisión
Los árboles de decisión son un tipo de algoritmo de clasificación que divide iterativamente los datos en subconjuntos basados en condiciones simples, representadas en forma de árbol. Cada nodo interno del árbol representa una condición sobre una característica (como "¿el valor es mayor que x?"), y las hojas representan las clases o categorías.
El árbol de decisión se crea dividiendo los datos en función de la característica que mejor separa las clases. Este proceso se repite de manera recursiva hasta que se alcanzan las hojas, donde cada hoja representa una clase. El objetivo es que las ramas del árbol lleven a una decisión clara sobre la clase a la que pertenece una instancia.
Ventajas:
- Fácil de interpretar y visualizar.
- Funciona bien con datos categóricos y numéricos.
- No requiere una gran preparación de los datos.
Desventajas:
- Los árboles de decisión simples pueden ser propensos al sobreajuste (overfitting), especialmente cuando se crean árboles profundos.
k-Vecinos más cercanos
El algoritmo k-Vecinos más Cercanos (k-NN) es un método de clasificación simple e intuitivo. Se basa en la idea de que una nueva observación se clasifica de acuerdo con las clases de las observaciones más cercanas en el espacio de características. Es decir, se predice la clase de una nueva instancia basándose en las clases mayoritarias de sus k vecinos más cercanos.
El algoritmo mide la distancia entre las observaciones utilizando métricas como la distancia euclidiana y asigna la clase más común entre los k vecinos más cercanos.
Ventajas:
- Sencillo de implementar.
- No requiere un entrenamiento previo, ya que las predicciones se hacen en tiempo real.
Desventajas:
- El rendimiento puede ser bajo con grandes conjuntos de datos, ya que requiere calcular la distancia de todos los puntos.
- Sensible a la escala de las características, por lo que es necesario normalizar los datos.
Regresión Logística
La regresión logística ya fue discutida en la lección anterior sobre modelos de regresión. Sin embargo, en el contexto de clasificación, la regresión logística se utiliza para predecir una probabilidad que posteriormente se clasifica en categorías. A pesar de su nombre, la regresión logística es un modelo de clasificación binaria o multinomial, ya que su salida es una categoría y no un valor numérico continuo.
La regresión logística en la lección de regresión se discutió desde la perspectiva de cómo transforma la entrada en probabilidades. Aquí se destaca que, al final, esas probabilidades se utilizan para asignar una clase, lo que la convierte en un modelo clave para problemas de clasificación.
Otros modelos de clasificación
Máquinas de Vectores de Soporte (SVM)
Las Máquinas de Vectores de Soporte (SVM) son un algoritmo avanzado de clasificación que encuentra un hiperplano óptimo que separa las clases en el espacio de características. En los problemas de clasificación binaria, el objetivo de SVM es encontrar un hiperplano que maximice la distancia entre los puntos de las dos clases (conocido como el margen). Este enfoque hace que SVM sea particularmente poderoso cuando hay una clara separación entre las clases.
En situaciones más complejas donde las clases no pueden separarse linealmente, SVM utiliza núcleos (kernels) para mapear los datos a un espacio de mayor dimensión donde sí pueden separarse linealmente.
Ventajas:
- Eficiente en espacios de alta dimensión.
- Eficaz cuando hay una clara separación entre clases.
- Funciona bien con datos no lineales utilizando el truco del kernel.
Desventajas:
- Puede ser ineficiente cuando los conjuntos de datos son muy grandes.
- Requiere ajuste de hiperparámetros y selección de kernel.
Por qué se considera un tema avanzado:
SVM es considerado más avanzado debido a la matemática subyacente y la necesidad de ajustar correctamente parámetros como el kernel. Además, su eficacia en espacios de alta dimensión y su capacidad para manejar problemas no lineales lo colocan en un nivel más complejo en comparación con algoritmos como k-NN o árboles de decisión.
Redes Neuronales Artificiales
Las Redes Neuronales Artificiales (ANN) son modelos inspirados en la estructura del cerebro humano. Consisten en neuronas (nodos) organizadas en capas: una capa de entrada, una o más capas ocultas, y una capa de salida. Cada neurona recibe un conjunto de entradas, las procesa y genera una salida, que luego se transmite a la siguiente capa.
En los problemas de clasificación, las redes neuronales pueden aprender relaciones complejas y no lineales entre las características de entrada y las clases de salida, lo que las hace extremadamente poderosas para problemas complejos. Las redes neuronales se entrenan utilizando el algoritmo de retropropagación (backpropagation) y gradiente descendente para ajustar los pesos de las conexiones entre las neuronas.
Ventajas:
- Extremadamente flexibles, capaces de aprender patrones complejos.
- Eficaces en problemas de clasificación con grandes conjuntos de datos y relaciones no lineales.
Desventajas:
- Requieren grandes cantidades de datos y recursos computacionales para entrenarse correctamente.
- Dificultad para interpretar los resultados debido a su naturaleza de "caja negra".
Por qué se consideran un tema avanzado:
Las redes neuronales son consideradas avanzadas debido a su complejidad estructural, la necesidad de ajustar múltiples hiperparámetros (número de capas, neuronas, tasa de aprendizaje), y el uso de técnicas de optimización más sofisticadas. Además, su entrenamiento requiere más tiempo y poder de cómputo.
Conclusiones
Los modelos de clasificación son fundamentales en inteligencia artificial para resolver problemas donde se necesita asignar una categoría o clase a una observación. Desde modelos simples y explicables como los árboles de decisión, la regresión logística y k-Vecinos más Cercanos, hasta modelos más complejos y poderosos como las Máquinas de Vectores de Soporte (SVM) y las Redes Neuronales Artificiales, cada uno tiene sus ventajas y desventajas en función del tipo de problema y los datos disponibles.
Es importante elegir el modelo adecuado en función del contexto, la cantidad de datos y la complejidad de las relaciones entre las características y las clases:
- Los modelos más simples, como los árboles de decisión y k-Vecinos más Cercanos, son fáciles de interpretar y útiles en escenarios con datos bien estructurados y fáciles de entender.
- Sin embargo, a medida que los problemas de clasificación se vuelven más complejos, los modelos más avanzados como las Máquinas de Vectores de Soporte (SVM) y las Redes Neuronales Artificiales se vuelven necesarios para capturar las relaciones no lineales y las interacciones más profundas en los datos.
- Además, es importante recordar que la regresión logística es un modelo clave para problemas de clasificación binaria, a pesar de su nombre, y se repite aquí por su capacidad para manejar decisiones probabilísticas en clasificación.
El desafío con los modelos avanzados, como las SVM y las redes neuronales, es que requieren más recursos computacionales y habilidades técnicas, lo que los convierte en herramientas poderosas, pero a menudo más difíciles de interpretar y ajustar.
Al final, la selección de un modelo de clasificación depende de los datos disponibles, el problema a resolver y los recursos técnicos a disposición. La clave es encontrar un equilibrio entre simplicidad, eficiencia y precisión, lo que permitirá desarrollar soluciones de clasificación efectivas y escalables para una amplia variedad de aplicaciones. -
¿Qué es un modelo de agrupación en clústeres?
La agrupación en clústeres (o simplemente "clustering") es una técnica de aprendizaje no supervisado utilizada para organizar un conjunto de datos en grupos o clústeres, de tal forma que los elementos dentro de cada grupo sean más similares entre sí que con los elementos de otros grupos. El objetivo principal es identificar estructuras subyacentes o patrones en los datos sin contar con etiquetas predefinidas o una variable de salida clara.
A diferencia de los modelos supervisados, como la clasificación o la regresión, en los modelos de agrupación no se proporciona una variable de destino que el modelo deba predecir. El algoritmo debe descubrir las estructuras internas del conjunto de datos basándose únicamente en las similitudes o diferencias entre los datos. Los clústeres son conjuntos de puntos que comparten características comunes, y estos puntos pueden representar individuos, objetos, comportamientos o cualquier otro tipo de entidad.
El clustering es muy utilizado en la exploración de datos, segmentación de clientes, análisis de mercado, y detección de patrones en grandes volúmenes de datos, entre otros.
Ejemplo práctico: imagina que tienes un conjunto de datos de clientes de una tienda online y quieres segmentar a los clientes en diferentes grupos basados en su comportamiento de compra, como "compradores frecuentes", "compradores ocasionales", o "nuevos clientes". Un modelo de agrupación en clústeres puede ayudarte a encontrar estos grupos automáticamente, lo que permite a la empresa personalizar campañas de marketing para cada grupo.
Tipos comunes de agrupación en clústeres
Existen varios métodos y algoritmos para la agrupación en clústeres. Cada uno utiliza diferentes enfoques para formar los grupos y es adecuado para diferentes tipos de datos. A continuación, exploramos los métodos más comunes:
k-Means
k-Means es uno de los algoritmos de agrupación más populares y sencillos. El objetivo de este algoritmo es dividir los datos en k grupos (o clústeres) predefinidos, donde k es el número de clústeres que se desea formar. El algoritmo funciona asignando inicialmente los puntos a clústeres aleatorios y luego ajusta iterativamente los centroides de cada clúster (el punto medio de cada grupo) hasta que las asignaciones de los puntos a los clústeres ya no cambian significativamente.
Proceso básico:
- Se eligen aleatoriamente k centroides (uno para cada clúster).
- Se asigna cada punto al clúster cuyo centroide está más cercano.
- Se recalculan los centroides en función de los puntos asignados a cada clúster.
- Se repiten los pasos 2 y 3 hasta que no haya cambios en las asignaciones.
Ventajas:
- Fácil de implementar y rápido de ejecutar.
- Funciona bien cuando los clústeres tienen forma esférica y tamaño similar.
Desventajas:
- Es necesario predefinir el número de clústeres (k).
- Sensible a la escala de las variables y a los valores atípicos.
- No funciona bien con clústeres de formas no esféricas o de diferentes tamaños.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN es un algoritmo de agrupación basado en la densidad, lo que significa que forma clústeres donde los puntos están densamente conectados, es decir, donde hay una alta concentración de puntos en un espacio. Este algoritmo es ideal para identificar clústeres de formas irregulares y detectar ruido o puntos atípicos que no pertenecen a ningún clúster.
Proceso básico:
- Se define un radio de búsqueda (ϵ\epsilonϵ) y un número mínimo de puntos (minPtsminPtsminPts) para formar un clúster.
- Se selecciona un punto aleatorio en el conjunto de datos.
- Si hay suficientes puntos en el radio ϵ\epsilonϵ alrededor de este punto, se forma un clúster.
- Se extiende el clúster a los puntos vecinos hasta que no se puedan agregar más puntos.
- Los puntos que no se pueden asignar a ningún clúster se consideran ruido.
Ventajas:
- No es necesario predefinir el número de clústeres.
- Es capaz de detectar clústeres de forma arbitraria y funciona bien con datos con ruido.
Desventajas:
- El rendimiento depende de los parámetros ϵ\epsilonϵ y minPtsminPtsminPts, que deben ajustarse correctamente.
- Puede ser sensible a la densidad de los clústeres.
Agrupamiento Jerárquico
El agrupamiento jerárquico construye un árbol de clústeres conocido como dendrograma, donde cada hoja representa un punto y cada nodo un clúster de puntos. El objetivo es crear una jerarquía de clústeres de tal forma que los puntos que son más similares entre sí se encuentren en los mismos clústeres en los niveles más bajos de la jerarquía.
Existen dos enfoques principales:
- Aglomerativo: Empieza con cada punto en su propio clúster y luego los combina iterativamente en clústeres más grandes hasta que todos los puntos están en un solo clúster.
- Divisivo: Comienza con todos los puntos en un solo clúster y luego divide iterativamente los clústeres en clústeres más pequeños.
Ventajas:
- No es necesario predefinir el número de clústeres.
- Proporciona una visión jerárquica de los datos, permitiendo diferentes niveles de granularidad en la agrupación.
Desventajas:
- Requiere más recursos computacionales que k-Means, especialmente con grandes conjuntos de datos.
- No es adecuado para datos con ruido o con clústeres no bien definidos.
Conclusiones
Los modelos de agrupación en clústeres son una herramienta poderosa para descubrir patrones y estructuras ocultas en conjuntos de datos sin necesidad de etiquetas. Dependiendo de la naturaleza de los datos y el problema a resolver, diferentes algoritmos de clustering, como k-Means, DBSCAN o el agrupamiento jerárquico, pueden ser más adecuados.
k-Means es rápido y eficiente para clústeres esféricos, pero requiere definir el número de clústeres de antemano.
DBSCAN es ideal para datos con clústeres de formas irregulares y es capaz de detectar ruido.
El agrupamiento jerárquico ofrece una estructura jerárquica de los clústeres, lo que permite una mayor flexibilidad en la agrupación, pero puede ser costoso en términos de computación.
La selección del algoritmo adecuado depende en gran medida de la estructura de los datos y del tipo de agrupamiento que se desee lograr. Sin embargo, todos estos métodos proporcionan una visión valiosa y no supervisada de los datos, permitiendo que las máquinas descubran patrones por sí solas.
-
¿Qué son los modelos generativos?
Los modelos generativos son un tipo de modelo de aprendizaje automático cuyo objetivo principal es aprender la distribución de probabilidad que genera los datos. A diferencia de los modelos discriminativos, que se centran en clasificar o hacer predicciones basadas en características, los modelos generativos se utilizan para generar nuevos datos que se parecen a los datos de entrenamiento. Estos modelos intentan aprender la estructura subyacente de los datos y, una vez entrenados, pueden crear ejemplos sintéticos nuevos que siguen la misma distribución que los datos originales.
Los modelos generativos pueden ser aplicados en diversas áreas, como la generación de imágenes, la síntesis de texto, la creación de música, y la simulación de datos para mejorar modelos en áreas con pocos datos.
Ejemplo práctico: un modelo generativo entrenado con imágenes de rostros humanos puede generar rostros completamente nuevos que nunca han sido vistos, pero que parecen realistas. Los modelos generativos también pueden usarse para tareas como la detección de anomalías, ya que al aprender lo que es "normal" en los datos, pueden identificar fácilmente lo que no encaja en ese patrón.
Tipos comunes de modelos generativos
Modelos de Mezcla Gaussiana
Los Modelos de Mezcla Gaussiana (GMM, por sus siglas en inglés) son un tipo de modelo generativo que asume que los datos son generados a partir de una combinación (mezcla) de varias distribuciones gaussianas o normales. Cada componente gaussiano representa un subgrupo o un clúster de datos en el conjunto general, y la suma ponderada de estas gaussianas describe la distribución general de los datos.
El GMM es muy flexible porque permite que los datos provengan de varias distribuciones gaussianas con diferentes medias y covarianzas. Además, cada punto en los datos tiene una probabilidad de pertenecer a cada uno de los componentes gaussianos, lo que permite manejar incertidumbres en la asignación de clústeres.
Funcionamiento básico:
- Se define un número de componentes (normalmente especificado por el usuario).
- Se asigna cada punto de datos a uno de los componentes gaussianos, calculando la probabilidad de que pertenezca a cada uno.
- Se actualizan las medias y las varianzas de los componentes gaussianos para maximizar la probabilidad de que los datos provengan de la mezcla de estas distribuciones.
- El proceso continúa hasta que las asignaciones se estabilizan.
Ventajas:
- Es flexible y puede modelar distribuciones complejas con múltiples modos.
- Es útil para detectar clústeres suaves, donde los datos no se agrupan de manera estricta, sino probabilística.
Desventajas:
- Requiere definir el número de componentes gaussianos de antemano.
- Puede ser sensible a los valores iniciales, lo que afecta los resultados.
Aplicaciones comunes:
- Segmentación de imágenes, donde diferentes regiones de una imagen pueden ser modeladas por diferentes distribuciones gaussianas.
- Modelado de datos en problemas donde hay múltiples poblaciones o distribuciones que generan los datos.
Autoencoders Variacionales (VAEs)
Los Autoencoders Variacionales (VAEs) son un tipo de red neuronal profunda utilizada para generar datos nuevos similares a los del conjunto de datos original. A diferencia de los autoencoders tradicionales, cuyo objetivo es aprender una representación comprimida de los datos, los VAEs están diseñados para aprender la distribución subyacente de los datos de manera probabilística. Esto los convierte en un tipo de modelo generativo.
El VAE consiste en dos partes principales:
- Codificador (Encoder): El codificador transforma los datos de entrada en una representación latente que sigue una distribución normal multivariada.
- Decodificador (Decoder): El decodificador toma esa representación latente y genera una reconstrucción de los datos de entrada.
La diferencia clave con un autoencoder tradicional es que el VAE genera distribuciones en lugar de puntos específicos en el espacio latente, lo que permite generar nuevas muestras.
Funcionamiento básico:
- Los datos de entrada se codifican en una distribución latente (normalmente gaussiana).
- Se muestrea un punto de esta distribución.
- El decodificador genera una nueva observación a partir de este punto muestreado.
- El entrenamiento del VAE se realiza minimizando dos términos: la pérdida de reconstrucción (para que los datos generados se parezcan a los originales) y la divergencia KL (para que la distribución latente se acerque a una normal).
Ventajas:
- Los VAEs pueden generar ejemplos nuevos que son variaciones suaves de los datos de entrenamiento.
- Permiten explorar el espacio latente de manera continua, lo que facilita la interpolación entre puntos.
Desventajas:
- Aunque los VAEs son poderosos, tienden a generar ejemplos que son menos nítidos o detallados en comparación con otros modelos generativos como las GANs.
Aplicaciones comunes:
- Generación de imágenes nuevas.
- Compresión de datos.
- Exploración de espacio latente en problemas donde es importante encontrar representaciones continuas.
Redes Generativas Antagónicas (GANs)
Las Redes Generativas Antagónicas (GANs) son uno de los modelos generativos más populares y poderosos. Propuestas por Ian Goodfellow en 2014, las GANs consisten en dos redes neuronales que compiten entre sí: un generador y un discriminador. La idea es que el generador intenta crear datos falsos que se parezcan a los datos reales, mientras que el discriminador intenta diferenciar entre los datos reales y los datos generados.
Esta competencia es lo que impulsa el aprendizaje: el generador mejora sus habilidades para crear datos realistas, mientras que el discriminador mejora su capacidad para detectar los datos falsos.
Funcionamiento básico:
- El generador toma una entrada aleatoria (normalmente un vector de ruido) y genera una muestra falsa (como una imagen).
- El discriminador recibe una mezcla de datos reales y generados, y su tarea es clasificar si los datos son reales o generados.
- El generador intenta engañar al discriminador produciendo ejemplos que parezcan lo más reales posibles.
- Ambos modelos se entrenan juntos, donde el generador mejora en crear datos realistas, y el discriminador mejora en distinguir entre datos reales y falsos.
Ventajas:
- Las GANs son capaces de generar imágenes y ejemplos extremadamente realistas.
- Son versátiles y se han utilizado para generar imágenes, videos, música, entre otros.
Desventajas:
- El entrenamiento de las GANs es inestable y puede llevar a problemas como el colapso del modo, donde el generador produce solo un pequeño conjunto de ejemplos repetitivos.
- Las GANs requieren ajustes finos y mucha potencia computacional.
Aplicaciones comunes:
- Generación de imágenes de alta calidad.
- Creación de contenido sintético para aumentar conjuntos de datos.
- Mejora de la resolución de imágenes (super-resolución).
- Transformación de estilo de imágenes (como convertir una foto en una obra de arte).
Otros modelos generativos
Aunque los Modelos de Mezcla Gaussiana, los Autoencoders Variacionales (VAEs) y las Redes Generativas Antagónicas (GANs) son ampliamente utilizados y considerados los enfoques principales en el ámbito de los modelos generativos, existen otras técnicas menos comunes pero igualmente poderosas. Estos modelos ofrecen soluciones alternativas para tareas específicas y brindan herramientas para modelar distribuciones de datos de formas más sofisticadas o especializadas.
A continuación, presentamos algunos de estos modelos generativos menos comunes, que aunque no son tan populares como las GANs o VAEs, siguen siendo útiles en varios escenarios, especialmente cuando se busca mayor flexibilidad, control, o se trabaja con estructuras de datos particulares.
Restricted Boltzmann Machines (RBM)
Las Restricted Boltzmann Machines (RBM) son un tipo de red neuronal estocástica que se utiliza para modelar distribuciones de probabilidad de un conjunto de datos. A diferencia de los modelos discriminativos, que solo predicen etiquetas o valores a partir de las características de los datos, las RBMs aprenden la distribución conjunta de los datos de entrada.
- Estructura: Están formadas por una capa visible y una capa oculta, donde las neuronas de una capa están conectadas con las de la otra, pero no hay conexiones dentro de las mismas capas.
- Aplicaciones: Las RBM han sido utilizadas en sistemas de recomendación y para preentrenar redes neuronales profundas (como parte de los Deep Belief Networks, una técnica utilizada antes del auge del aprendizaje profundo moderno).
Flow-based Models
Los Flow-based Models son un enfoque en el que la transformación entre la distribución latente y la distribución de los datos observados es invertible. Esto significa que es posible mapear de manera eficiente un punto en el espacio latente a un dato generado, y viceversa.
- Funcionamiento: Estos modelos se basan en transformaciones invertibles de la variable latente que permiten el cálculo exacto de la probabilidad, lo que permite generar datos y calcular la probabilidad de una muestra de manera directa.
- Ejemplos: Modelos como RealNVP y Glow son conocidos por generar imágenes realistas, y su capacidad para realizar transformaciones invertibles permite un control más detallado sobre los datos generados.
Deep Belief Networks (DBN)
Las Deep Belief Networks (DBN) son una clase de redes neuronales generativas compuestas por múltiples capas de Restricted Boltzmann Machines (RBM) apiladas. Se entrenan capa por capa de manera no supervisada y luego se pueden ajustar utilizando un algoritmo de retropropagación supervisada.
- Aplicaciones: Aunque han sido parcialmente reemplazadas por redes neuronales profundas más modernas, las DBN fueron pioneras en el área de preentrenamiento no supervisado para mejorar el rendimiento en tareas supervisadas.
Autoregressive Models
Los Modelos Autoregresivos son aquellos en los que el valor de cada variable en el conjunto de datos se modela como dependiente de los valores anteriores. Estos modelos generan nuevos datos paso a paso, prediciendo el valor de cada componente de una muestra secuencialmente, basándose en los componentes previos.
- Ejemplos: PixelRNN y PixelCNN son ejemplos de modelos autoregresivos que se utilizan para generar imágenes píxel por píxel, donde cada píxel se genera basándose en los píxeles anteriores.
- Aplicaciones: Además de la generación de imágenes, se utilizan en tareas de procesamiento de lenguaje natural, como la generación de texto o secuencias de audio.
Normalizing Flows
Los Normalizing Flows son modelos generativos que transforman una distribución simple (como una distribución normal) en una distribución más compleja a través de una secuencia de transformaciones invertibles. Al ser completamente invertibles, permiten calcular de manera eficiente tanto la probabilidad de los datos como la generación de nuevos ejemplos.
- Funcionamiento: Transforman la variable latente a través de una serie de funciones invertibles y parametrizables que pueden ajustarse para modelar la distribución de los datos de manera precisa.
- Aplicaciones: Estos modelos son utilizados en tareas como la generación de imágenes y en problemas donde es crucial tener control sobre la distribución generada.
Conclusiones
Los modelos generativos representan una de las áreas más emocionantes y desafiantes en la inteligencia artificial y el aprendizaje profundo. Al aprender la distribución subyacente de los datos, estos modelos permiten la creación de datos sintéticos que parecen realistas, lo que tiene aplicaciones en la generación de imágenes, el procesamiento de lenguaje natural, la simulación de datos y mucho más. -
¿Qué son los LLMs?
Los Modelos de Lenguaje de Gran Escala (LLMs, por sus siglas en inglés) son un tipo de modelo de aprendizaje automático que ha transformado el campo del procesamiento del lenguaje natural (NLP). Estos modelos están entrenados en grandes cantidades de texto para comprender, generar y manipular el lenguaje humano de manera efectiva. El término "gran escala" se refiere al hecho de que estos modelos tienen miles de millones de parámetros, lo que les permite captar las complejidades y sutilezas del lenguaje.
Los LLMs son capaces de realizar tareas avanzadas como la traducción automática, el resumen de textos, la respuesta a preguntas, la generación de texto coherente, y más. Gracias a su capacidad para aprender patrones a partir de grandes cantidades de datos, pueden generalizar el conocimiento a una amplia variedad de tareas de lenguaje natural.
Ejemplo práctico: modelos como GPT-3 pueden generar texto continuo basado en una entrada, mientras que BERT puede entender y completar oraciones, lo que lo hace útil para tareas como el análisis de sentimientos o la respuesta a preguntas.
El surgimiento de los transformers ha permitido que los LLMs manejen secuencias largas y comprendan el contexto en profundidad, lo que los convierte en herramientas poderosas en aplicaciones como la asistencia virtual, la creación de contenido y la automatización de procesos de lenguaje.
¿Qué son los transformers?
Los Transformers son una arquitectura de red neuronal introducida en el artículo "Attention is All You Need" (Vaswani et al., 2017) que ha revolucionado el procesamiento del lenguaje natural. Antes de los transformers, las arquitecturas más comunes en NLP eran las redes recurrentes (RNNs) y las LSTM, que procesaban el texto de forma secuencial, lo que dificultaba el manejo de secuencias largas debido a problemas como la dependencia temporal y la pérdida de información contextual.
El transformer supera estas limitaciones al utilizar un mecanismo de atención que le permite a cada palabra en una secuencia prestar atención a todas las demás palabras simultáneamente, en lugar de procesarlas en un orden estricto. Esto significa que los transformers pueden captar relaciones entre palabras y frases distantes, permitiendo una comprensión mucho más profunda del contexto.
Componentes principales:
- Atención Multi-Cabeza (Multi-Head Attention): Este mecanismo permite al modelo prestar atención a diferentes partes de la secuencia en paralelo, lo que mejora su capacidad para aprender múltiples relaciones dentro del texto.
- Codificación Posicional: Dado que los transformers no procesan el texto en orden secuencial, utilizan una codificación que indica la posición de cada palabra en la secuencia, lo que les permite mantener el sentido del orden.
- Capas de Feed Forward: Después de la atención, las representaciones de las palabras pasan por capas densas que ayudan a refinar la comprensión del contexto.
Aplicaciones:
- Traducción automática.
- Resumen de texto.
- Generación de texto.
- Respuesta a preguntas.
Los transformers son la base de muchos de los modelos de lenguaje de gran escala más avanzados que utilizamos hoy en día, como GPT, BERT, T5, y XLNet.
Tipos comunes de modelos LLM
Modelos GPT
Los Modelos GPT son una serie de modelos desarrollados por OpenAI que han popularizado el uso de transformers en tareas de generación de texto. Los GPT están entrenados utilizando un enfoque autoregresivo, en el que el modelo predice la siguiente palabra de una secuencia basándose en las palabras anteriores.
GPT-3
GPT-3, lanzado en 2020, es uno de los modelos más conocidos de la serie GPT. Con 175 mil millones de parámetros, se trata de uno de los modelos más grandes jamás creados. GPT-3 ha demostrado una capacidad sorprendente para generar texto coherente, responder preguntas, realizar traducciones, escribir código, y mucho más. Su flexibilidad le permite realizar múltiples tareas con poco ajuste específico (fine-tuning).
Las características de GPT 3 son:
- Generación de texto fluida: GPT-3 puede generar texto continuo y coherente a partir de una simple entrada.
- Versatilidad: Desde la creación de contenido hasta la respuesta a preguntas y generación de código, GPT-3 puede realizar tareas muy diversas.
- Zero-shot y few-shot learning: GPT-3 puede realizar tareas sin entrenamiento adicional o con solo unos pocos ejemplos, lo que reduce la necesidad de grandes cantidades de datos etiquetados.
GPT-4
GPT-4, lanzado en 2023, es una evolución de GPT-3. Aparte de sus mejoras en capacidad y precisión, GPT-4 introduce la capacidad multimodal, lo que significa que puede procesar tanto texto como imágenes. Esta característica le permite realizar tareas combinadas, como interpretar gráficos, generar descripciones de imágenes, y realizar análisis visuales y textuales simultáneamente.
Las características de GPT-4:
- Multimodalidad: GPT-4 no solo genera texto, sino que también puede analizar imágenes, lo que permite aplicaciones más complejas y ricas.
- Mejora en el razonamiento: GPT-4 tiene una mayor capacidad de razonamiento y manejo de tareas complejas, ofreciendo resultados más precisos.
GPT-5 (anticipado)
Aunque aún no ha sido lanzado, se espera que GPT-5 continúe el avance en capacidades de generación y razonamiento, mejorando la coherencia en conversaciones más largas y la comprensión multimodal. GPT-5 podría consolidar aún más la capacidad de los LLMs para interactuar en tareas complejas a través de múltiples modalidades, desde texto hasta imágenes y posiblemente audio.
Modelos BERT
BERT, lanzado por Google en 2018, es un modelo basado en transformers que utiliza un enfoque bidireccional. Esto significa que, a diferencia de GPT, BERT analiza el contexto de una palabra considerando tanto las palabras que vienen antes como las que vienen después en una oración, lo que le permite comprender mejor el significado de las palabras dentro de un contexto más amplio.
BERT se entrenó usando una técnica llamada enmascaramiento de palabras, en la que ciertas palabras de una oración se ocultan, y el modelo debe predecirlas usando el contexto circundante. Esto lo hace ideal para tareas como la respuesta a preguntas o la clasificación de texto.
Características de BERT:
- Bidireccionalidad: Permite una mejor comprensión del contexto completo, tanto de palabras anteriores como posteriores.
- Fine-tuning: Aunque BERT se preentrena en grandes corpus de texto, su fuerza reside en la capacidad de ajustarse fácilmente para tareas específicas, como el análisis de sentimientos o la clasificación.
Gemini (Evolución de BERT)
Google ha lanzado Gemini, que representa una evolución de BERT. Mientras que BERT se centra en la comprensión bidireccional de texto, Gemini amplía esta capacidad, integrando el procesamiento multimodal (similar a GPT-4), lo que le permite trabajar tanto con texto como con imágenes.
Características de Gemini:
- Multimodalidad: Gemini puede procesar y generar tanto texto como imágenes, lo que lo convierte en un modelo más versátil.
- Mejora en eficiencia: Gemini ha sido diseñado para ser más eficiente en términos de capacidad y rendimiento, con avances en la comprensión y generación de datos complejos.
Otros modelos LLM
Además de GPT y BERT, que son los modelos de lenguaje de gran escala (LLMs) más conocidos, existen otros modelos menos comunes que también juegan un papel importante en el campo del procesamiento del lenguaje natural (NLP). Estos modelos utilizan la misma arquitectura base de transformers, pero con variaciones o mejoras que los hacen adecuados para tareas o aplicaciones específicas.
T5 (Text-To-Text Transfer Transformer)
El T5 (Text-to-Text Transfer Transformer) es un modelo de lenguaje desarrollado por Google que reformula todas las tareas de NLP como un problema de traducción de texto. En lugar de tener diferentes enfoques para tareas como la clasificación de texto o la traducción automática, T5 convierte cada problema en una tarea de "input-output" donde el modelo toma texto como entrada y genera texto como salida.
Características de T5:
- Enfoque text-to-text: En T5, todas las tareas se plantean como una transformación de texto a texto. Por ejemplo, para una tarea de clasificación, el modelo genera el nombre de la clase como texto.
- Transferencia de aprendizaje: Similar a BERT, T5 se preentrena en un gran corpus de datos y luego se ajusta para tareas específicas de NLP.
- Versatilidad: T5 es extremadamente flexible y se puede aplicar a diversas tareas de NLP, incluyendo traducción, resumen, clasificación y más.
Aplicaciones:
- Traducción automática.
- Resumen de documentos.
- Clasificación de texto.
RoBERTa (Robustly Optimized BERT Pretraining Approach)
RoBERTa es una variación de BERT que optimiza su preentrenamiento para mejorar el rendimiento en tareas de NLP. Desarrollado por Facebook AI, RoBERTa utiliza un entrenamiento más largo y en un conjunto de datos más grande, y ajusta algunos de los hiperparámetros del modelo original de BERT, lo que le permite obtener mejores resultados sin cambiar la arquitectura básica.
Características de RoBERTa:
- Entrenamiento más intensivo: RoBERTa se entrena en más datos y durante más tiempo que BERT, lo que le permite captar patrones más sutiles en los datos.
- Eliminación de la predicción de la próxima oración (Next Sentence Prediction): A diferencia de BERT, RoBERTa omite esta tarea durante el preentrenamiento, centrándose solo en la predicción de palabras enmascaradas.
Aplicaciones:
- Tareas de clasificación de texto.
- Respuesta a preguntas.
- Análisis de sentimientos.
XLNet
XLNet es un modelo de lenguaje que combina las ventajas de BERT y los modelos autoregresivos como GPT, mejorando la representación bidireccional del lenguaje. Desarrollado por Google y la Universidad de Carnegie Mellon, XLNet supera algunas de las limitaciones de BERT al utilizar un enfoque basado en permutaciones que permite modelar relaciones a largo plazo en el texto de una manera más flexible.
Características de XLNet:
- Permutación de secuencias: En lugar de procesar las secuencias de texto en un orden específico, XLNet utiliza una técnica de permutación que le permite aprender mejor las relaciones contextuales entre las palabras.
- Mejora sobre BERT: Mientras que BERT utiliza enmascaramiento bidireccional, XLNet combina la bidireccionalidad con un enfoque autoregresivo para una comprensión más profunda del texto.
Aplicaciones:
- Análisis de texto.
- Respuesta a preguntas.
- Modelado de lenguaje.
ALBERT (A Lite BERT)
ALBERT es una variante de BERT diseñada para reducir la cantidad de parámetros y hacer que el modelo sea más eficiente, tanto en términos de almacenamiento como de tiempo de entrenamiento. Aunque más pequeño, ALBERT sigue manteniendo un rendimiento competitivo en tareas de NLP.
Características de ALBERT:
- Compartición de parámetros: ALBERT reutiliza los parámetros de cada capa en lugar de tener un conjunto de parámetros separado para cada capa, lo que reduce significativamente el tamaño del modelo.
- Factorización de embedding: ALBERT divide las representaciones en dos partes, lo que mejora la eficiencia sin perder precisión.
Aplicaciones:
- Tareas de comprensión de texto.
- Clasificación de texto en dispositivos con limitaciones de recursos.
ELECTRA
ELECTRA es un modelo de lenguaje generativo que introduce un nuevo método de preentrenamiento basado en la detección de tokens. En lugar de enmascarar palabras en el texto y predecir las palabras enmascaradas como en BERT, ELECTRA genera palabras incorrectas en una secuencia y entrena al modelo para distinguir entre las palabras reales y las generadas.
Características de ELECTRA:
- Preentrenamiento eficiente: ELECTRA ofrece un método más eficiente que BERT al generar datos sintéticos durante el preentrenamiento, lo que reduce significativamente el costo computacional.
- Detección de tokens: ELECTRA entrena un clasificador que distingue entre las palabras reales y las palabras "falsas" generadas, lo que mejora el rendimiento en tareas supervisadas.
Aplicaciones:
- Clasificación de texto.
- Análisis de sentimientos.
- Respuesta a preguntas.
Conclusiones
Los LLMs han impulsado enormemente el campo del NLP y continúan expandiendo los límites de lo que las máquinas pueden hacer con el lenguaje humano. Los modelos más comunes como GPT y BERT son los más influyentes debido a su capacidad de adaptación y flexibilidad en una amplia variedad de tareas, mientras que los modelos menos comunes siguen proporcionando innovaciones importantes, como mayor eficiencia y especialización. Juntos, estos modelos amplían el panorama del procesamiento del lenguaje, haciéndolo más accesible y poderoso que nunca. -
-
-
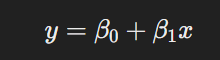
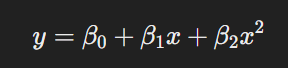
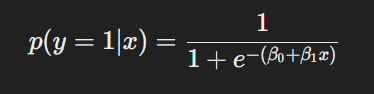
 Campus
Campus
