 Campus
Campus
Diagrama de temas
-
En esta lección, abordaremos de manera general las principales categorías de la inteligencia artificial (IA), brindando una visión global de los enfoques más importantes dentro de este campo. Cada categoría juega un papel crucial en el desarrollo de sistemas de IA avanzados, desde la capacidad de las máquinas para aprender de los datos hasta la simulación del pensamiento humano.
Aunque hoy daremos un vistazo amplio, en las próximas lecciones profundizaremos en cada una de estas categorías de manera individual, para que puedas entender mejor sus técnicas, aplicaciones y diferencias clave.
Aprendizaje Automático (AA)
El aprendizaje automático (Machine Learning, ML) es uno de los subcampos más importantes de la IA, centrado en el desarrollo de algoritmos que permiten a las máquinas aprender y mejorar a partir de los datos sin ser programadas explícitamente para cada tarea específica. Este enfoque permite que las máquinas identifiquen patrones en los datos, tomen decisiones o hagan predicciones basadas en ellos. Hay varios tipos de aprendizaje dentro del aprendizaje automático, siendo los más destacados el aprendizaje automático supervisado, el no supervisado, y el aprendizaje por refuerzo.
Aprendizaje Automático supervisado
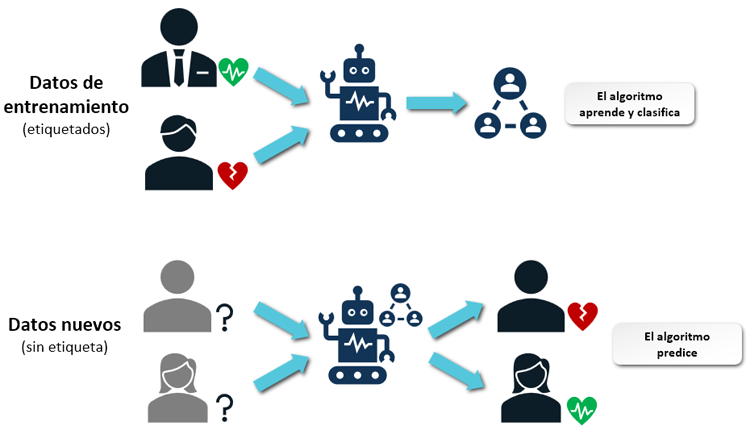
El aprendizaje supervisado es un enfoque fundamental en el aprendizaje automático que se basa en el uso de datos etiquetados para entrenar modelos predictivos. En este método, se proporciona a la máquina un conjunto de datos de entrada que incluyen las salidas esperadas, conocidas como etiquetas. El objetivo del modelo es aprender una función que, dada una nueva entrada, pueda predecir la salida correcta.
Por ejemplo: tienes una hoja de cálculo de datos de salud de las personas que participaron en un estudio:
- Los datos están en una tabla, con cada persona como una fila, varias características de cada persona como columnas, como el peso, la altura, la presión arterial, etc.
- La columna final que registra un "sí" o "no" en cuanto a si esta persona tiene o no una enfermedad cardíaca. A esto se lo llama “etiqueta”.
Se introduce el conjunto de datos al algoritmo, que incluye tanto las características como las etiquetas correspondientes. El algoritmo se entrena en estos datos, aprendiendo a asociar las características con las etiquetas. Este proceso de entrenamiento es fundamental para preparar al modelo para realizar predicciones precisas sobre nuevos datos.
Una vez entrenado, el modelo puede ser utilizado para analizar nuevos conjuntos de datos y predecir la etiqueta correspondiente. En el caso de los datos de salud, esto permitiría, por ejemplo, predecir la probabilidad de que nuevas personas tengan enfermedades cardíacas basándose en sus características médicas.
Con el aprendizaje supervisado, eliges algoritmos específicos para entrenar con estos datos, incluyendo la etiqueta de enfermedad cardíaca. Esto permite a la máquina utilizar el aprendizaje automático para realizar predicciones razonables sobre si las personas en nuevos registros podrían tener enfermedades cardíacas, basándose en su análisis de los datos.
En resumen, este conjunto de datos se introduce en el algoritmo como entrada. Se dice que el algoritmo se entrena en este conjunto de datos como parte de su proceso de aprendizaje.
Aprendizaje Automático no supervisado
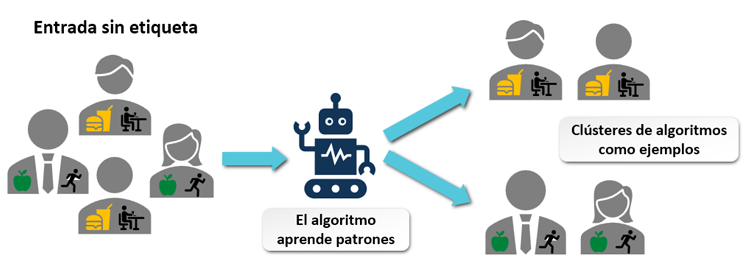
El aprendizaje no supervisado es un enfoque de aprendizaje automático donde los datos de entrenamiento no están etiquetados. El algoritmo no recibe instrucciones explícitas sobre qué debe predecir; en cambio, su objetivo es descubrir patrones ocultos o agrupaciones dentro de los datos. Este tipo de aprendizaje es fundamental para entender estructuras no evidentes en conjuntos de datos complejos.
Ejemplos de Aplicación:
Segmentación de Clientes: Agrupar usuarios en diferentes categorías basadas en comportamientos o características similares sin un objetivo predeterminado.
Investigación Médica: Analizar registros de salud sin etiquetas para identificar correlaciones, como agrupar pacientes con características similares que podrían indicar condiciones médicas no diagnosticadas.
Investigación Genética: Agrupar patrones de ADN para estudiar la evolución biológica, donde las etiquetas explícitas de los grupos genéticos no están disponibles.
Debido a la ausencia de etiquetas, el aprendizaje no supervisado puede ser desafiante de implementar efectivamente, ya que el criterio de éxito no siempre está claro y depende de la interpretación de los patrones descubiertos por el algoritmo.
Aprendizaje Semisupervisado
El aprendizaje semisupervisado combina elementos de los enfoques supervisado y no supervisado. En un conjunto de datos típico para este tipo de aprendizaje, la mayoría de los ejemplos no están etiquetados, mientras que una pequeña parte sí lo está. Esta estrategia es especialmente útil en situaciones donde etiquetar todos los datos sería demasiado costoso, laborioso o inviable.
Beneficios:
Eficiencia de Costos y Tiempo: Reducir la necesidad de etiquetado extenso sin renunciar completamente a las ventajas de tener ejemplos etiquetados.
Mejora de Rendimiento: Incluso una pequeña cantidad de datos etiquetados puede mejorar significativamente la precisión de los modelos sobre el aprendizaje completamente no supervisado.
Casos de Uso Prácticos:
En entornos donde los datos son abundantes pero las etiquetas son escasas, como en imágenes de internet para tareas de reconocimiento visual.
En la investigación biomédica, donde etiquetar ejemplos puede requerir verificación experta que es costosa y lenta.
Aprendizaje Profundo
El aprendizaje profundo (Deep Learning) es un subcampo del aprendizaje automático que se basa en redes neuronales artificiales con muchas capas (de ahí el término "profundo"). Estas redes son capaces de procesar grandes volúmenes de datos y aprender representaciones en múltiples niveles de abstracción, lo que las hace extremadamente poderosas para tareas complejas como el reconocimiento de imágenes, la traducción automática y el procesamiento del lenguaje natural. El aprendizaje profundo ha sido responsable de algunos de los avances más importantes en la IA moderna, desde los vehículos autónomos hasta los asistentes virtuales que reconocen la voz humana.
IA Simbólica
La IA simbólica es un enfoque que utiliza la lógica formal, reglas y conocimientos predefinidos para imitar el pensamiento humano. A diferencia de los métodos de aprendizaje basados en datos, la IA simbólica se basa en reglas explícitas que los desarrolladores crean para modelar el razonamiento humano. Un aspecto destacable de la IA simbólica es su capacidad para explicar sus decisiones, ya que los procesos de toma de decisiones se basan en reglas transparentes y rastreables. Este enfoque se utiliza principalmente en sistemas expertos, donde se requiere una toma de decisiones clara y justificable, como en aplicaciones médicas y legales.
IA Evolutiva
La IA evolutiva se inspira en los principios de la evolución biológica, utilizando algoritmos como los algoritmos genéticos para evolucionar soluciones a problemas. Al igual que en la naturaleza, la IA evolutiva utiliza mecanismos como la selección natural, la mutación y el cruce para iterar y mejorar gradualmente las soluciones. Este enfoque es útil para problemas complejos en los que las soluciones óptimas no pueden ser predefinidas o calculadas fácilmente, como la optimización de procesos industriales o la resolución de problemas de diseño.
Intersecciones y Superposiciones
Es importante señalar que estas categorías de IA no son mutuamente excluyentes. De hecho, muchas veces se superponen y trabajan en conjunto. Por ejemplo, el aprendizaje profundo se basa en los principios del aprendizaje automático, y algunos sistemas pueden combinar tanto enfoques simbólicos como basados en datos para lograr un mejor rendimiento. La IA evolutiva puede utilizarse junto con el aprendizaje por refuerzo para mejorar las estrategias de un agente a medida que aprende a través de la interacción con su entorno.
Próximas lecciones
A lo largo de las próximas lecciones, profundizaremos en cada una de estas categorías de inteligencia artificial. Explicaremos más a fondo sus fundamentos, cómo funcionan, y en qué aplicaciones específicas son más efectivas. Esta estructura te ayudará a obtener una comprensión sólida de las diferentes técnicas y enfoques que se utilizan en el campo de la IA, y cómo pueden aplicarse para resolver problemas del mundo real.
 Campus
Campus
