 Campus
Campus
Diagrama de temas
-
-
3er Clase Sincrónica
La inteligencia artificial (IA) abarca una serie de conceptos fundamentales que permiten a las máquinas aprender, razonar y tomar decisiones de manera autónoma. En esta sección, exploraremos las bases que sustentan la IA moderna, brindándote el conocimiento necesario para entender su funcionamiento y aplicaciones en diversos contextos.
A lo largo de las lecciones, abordaremos los siguientes temas clave:
- Categorías de Inteligencia Artificial: Supervisada, no supervisada, semisupervisada y otras.
- Datos y su importancia en IA: Cómo la calidad y preparación de los datos afectan los resultados.
- Tareas comunes en IA: Clasificación, regresión, clustering, entre otras.
- Algoritmos y modelos en IA: Diferencias clave y su interrelación.
- Evaluación de modelos en IA: Métodos para medir el rendimiento de los modelos.
- Requisitos y conocimientos específicos para IA: Habilidades técnicas y científicas necesarias para proyectos de IA.
Con esta base, estarás preparado para profundizar en los conceptos esenciales que impulsan la IA y entender su impacto en el mundo real.
-
En esta lección, abordaremos de manera general las principales categorías de la inteligencia artificial (IA), brindando una visión global de los enfoques más importantes dentro de este campo. Cada categoría juega un papel crucial en el desarrollo de sistemas de IA avanzados, desde la capacidad de las máquinas para aprender de los datos hasta la simulación del pensamiento humano.
Aunque hoy daremos un vistazo amplio, en las próximas lecciones profundizaremos en cada una de estas categorías de manera individual, para que puedas entender mejor sus técnicas, aplicaciones y diferencias clave.
Aprendizaje Automático (AA)
El aprendizaje automático (Machine Learning, ML) es uno de los subcampos más importantes de la IA, centrado en el desarrollo de algoritmos que permiten a las máquinas aprender y mejorar a partir de los datos sin ser programadas explícitamente para cada tarea específica. Este enfoque permite que las máquinas identifiquen patrones en los datos, tomen decisiones o hagan predicciones basadas en ellos. Hay varios tipos de aprendizaje dentro del aprendizaje automático, siendo los más destacados el aprendizaje automático supervisado, el no supervisado, y el aprendizaje por refuerzo.
Aprendizaje Automático supervisado
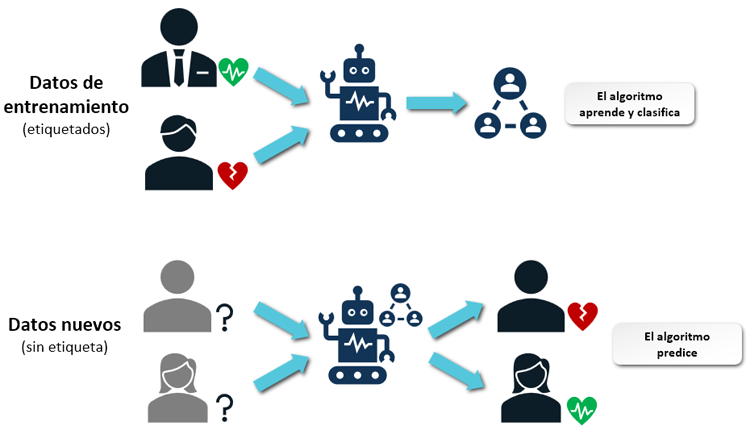
El aprendizaje supervisado es un enfoque fundamental en el aprendizaje automático que se basa en el uso de datos etiquetados para entrenar modelos predictivos. En este método, se proporciona a la máquina un conjunto de datos de entrada que incluyen las salidas esperadas, conocidas como etiquetas. El objetivo del modelo es aprender una función que, dada una nueva entrada, pueda predecir la salida correcta.
Por ejemplo: tienes una hoja de cálculo de datos de salud de las personas que participaron en un estudio:
- Los datos están en una tabla, con cada persona como una fila, varias características de cada persona como columnas, como el peso, la altura, la presión arterial, etc.
- La columna final que registra un "sí" o "no" en cuanto a si esta persona tiene o no una enfermedad cardíaca. A esto se lo llama “etiqueta”.
Se introduce el conjunto de datos al algoritmo, que incluye tanto las características como las etiquetas correspondientes. El algoritmo se entrena en estos datos, aprendiendo a asociar las características con las etiquetas. Este proceso de entrenamiento es fundamental para preparar al modelo para realizar predicciones precisas sobre nuevos datos.
Una vez entrenado, el modelo puede ser utilizado para analizar nuevos conjuntos de datos y predecir la etiqueta correspondiente. En el caso de los datos de salud, esto permitiría, por ejemplo, predecir la probabilidad de que nuevas personas tengan enfermedades cardíacas basándose en sus características médicas.
Con el aprendizaje supervisado, eliges algoritmos específicos para entrenar con estos datos, incluyendo la etiqueta de enfermedad cardíaca. Esto permite a la máquina utilizar el aprendizaje automático para realizar predicciones razonables sobre si las personas en nuevos registros podrían tener enfermedades cardíacas, basándose en su análisis de los datos.
En resumen, este conjunto de datos se introduce en el algoritmo como entrada. Se dice que el algoritmo se entrena en este conjunto de datos como parte de su proceso de aprendizaje.
Aprendizaje Automático no supervisado
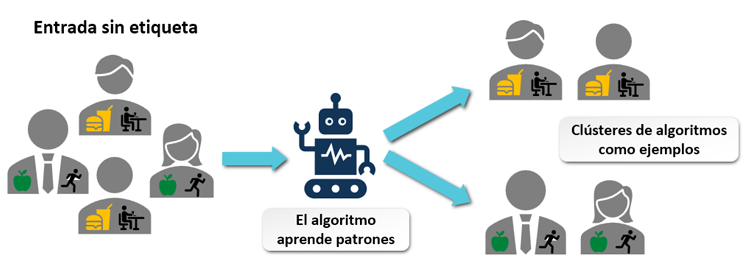
El aprendizaje no supervisado es un enfoque de aprendizaje automático donde los datos de entrenamiento no están etiquetados. El algoritmo no recibe instrucciones explícitas sobre qué debe predecir; en cambio, su objetivo es descubrir patrones ocultos o agrupaciones dentro de los datos. Este tipo de aprendizaje es fundamental para entender estructuras no evidentes en conjuntos de datos complejos.
Ejemplos de Aplicación:
Segmentación de Clientes: Agrupar usuarios en diferentes categorías basadas en comportamientos o características similares sin un objetivo predeterminado.
Investigación Médica: Analizar registros de salud sin etiquetas para identificar correlaciones, como agrupar pacientes con características similares que podrían indicar condiciones médicas no diagnosticadas.
Investigación Genética: Agrupar patrones de ADN para estudiar la evolución biológica, donde las etiquetas explícitas de los grupos genéticos no están disponibles.
Debido a la ausencia de etiquetas, el aprendizaje no supervisado puede ser desafiante de implementar efectivamente, ya que el criterio de éxito no siempre está claro y depende de la interpretación de los patrones descubiertos por el algoritmo.
Aprendizaje Semisupervisado
El aprendizaje semisupervisado combina elementos de los enfoques supervisado y no supervisado. En un conjunto de datos típico para este tipo de aprendizaje, la mayoría de los ejemplos no están etiquetados, mientras que una pequeña parte sí lo está. Esta estrategia es especialmente útil en situaciones donde etiquetar todos los datos sería demasiado costoso, laborioso o inviable.
Beneficios:
Eficiencia de Costos y Tiempo: Reducir la necesidad de etiquetado extenso sin renunciar completamente a las ventajas de tener ejemplos etiquetados.
Mejora de Rendimiento: Incluso una pequeña cantidad de datos etiquetados puede mejorar significativamente la precisión de los modelos sobre el aprendizaje completamente no supervisado.
Casos de Uso Prácticos:
En entornos donde los datos son abundantes pero las etiquetas son escasas, como en imágenes de internet para tareas de reconocimiento visual.
En la investigación biomédica, donde etiquetar ejemplos puede requerir verificación experta que es costosa y lenta.
Aprendizaje Profundo
El aprendizaje profundo (Deep Learning) es un subcampo del aprendizaje automático que se basa en redes neuronales artificiales con muchas capas (de ahí el término "profundo"). Estas redes son capaces de procesar grandes volúmenes de datos y aprender representaciones en múltiples niveles de abstracción, lo que las hace extremadamente poderosas para tareas complejas como el reconocimiento de imágenes, la traducción automática y el procesamiento del lenguaje natural. El aprendizaje profundo ha sido responsable de algunos de los avances más importantes en la IA moderna, desde los vehículos autónomos hasta los asistentes virtuales que reconocen la voz humana.
IA Simbólica
La IA simbólica es un enfoque que utiliza la lógica formal, reglas y conocimientos predefinidos para imitar el pensamiento humano. A diferencia de los métodos de aprendizaje basados en datos, la IA simbólica se basa en reglas explícitas que los desarrolladores crean para modelar el razonamiento humano. Un aspecto destacable de la IA simbólica es su capacidad para explicar sus decisiones, ya que los procesos de toma de decisiones se basan en reglas transparentes y rastreables. Este enfoque se utiliza principalmente en sistemas expertos, donde se requiere una toma de decisiones clara y justificable, como en aplicaciones médicas y legales.
IA Evolutiva
La IA evolutiva se inspira en los principios de la evolución biológica, utilizando algoritmos como los algoritmos genéticos para evolucionar soluciones a problemas. Al igual que en la naturaleza, la IA evolutiva utiliza mecanismos como la selección natural, la mutación y el cruce para iterar y mejorar gradualmente las soluciones. Este enfoque es útil para problemas complejos en los que las soluciones óptimas no pueden ser predefinidas o calculadas fácilmente, como la optimización de procesos industriales o la resolución de problemas de diseño.
Intersecciones y Superposiciones
Es importante señalar que estas categorías de IA no son mutuamente excluyentes. De hecho, muchas veces se superponen y trabajan en conjunto. Por ejemplo, el aprendizaje profundo se basa en los principios del aprendizaje automático, y algunos sistemas pueden combinar tanto enfoques simbólicos como basados en datos para lograr un mejor rendimiento. La IA evolutiva puede utilizarse junto con el aprendizaje por refuerzo para mejorar las estrategias de un agente a medida que aprende a través de la interacción con su entorno.
Próximas lecciones
A lo largo de las próximas lecciones, profundizaremos en cada una de estas categorías de inteligencia artificial. Explicaremos más a fondo sus fundamentos, cómo funcionan, y en qué aplicaciones específicas son más efectivas. Esta estructura te ayudará a obtener una comprensión sólida de las diferentes técnicas y enfoques que se utilizan en el campo de la IA, y cómo pueden aplicarse para resolver problemas del mundo real.
-
La inteligencia artificial (IA) depende de los datos para funcionar de manera efectiva. Los datos son la base sobre la cual se entrenan los modelos de IA, y su calidad y preparación son factores críticos para el éxito de cualquier pipeline de IA. Sin datos adecuados, incluso los algoritmos más avanzados producirán resultados erróneos o poco confiables. En esta lección, exploramos la importancia de los datos en la IA, cómo se deben preparar para su uso en los modelos, y los conceptos clave que giran en torno a los datos: los ejemplos, las características y las etiquetas. Además, analizaremos cómo la calidad de los datos afecta directamente los resultados de un modelo y por qué no siempre es posible contar con etiquetas en los datos, especialmente en el contexto del aprendizaje no supervisado.
Datos en IA
Los datos son fundamentales para el desarrollo de cualquier modelo de IA. Sin datos de calidad, un modelo no puede aprender de manera efectiva ni hacer predicciones precisas. La preparación de los datos implica una serie de pasos cruciales, como la limpieza de datos, la transformación y el procesamiento, que permiten alimentar adecuadamente los algoritmos de aprendizaje automático. Estos datos deben estar bien organizados y estructurados para que los modelos puedan entenderlos y aprender patrones que sean útiles en la toma de decisiones o predicciones.
El ciclo de vida de un proyecto de IA suele empezar con la recolección de datos en bruto, pero este es solo el primer paso. Antes de alimentar a un modelo con datos, es esencial preparar estos datos a través de una pipeline de datos, que se encarga de organizar y procesar los datos en varias fases. Las tareas comunes incluyen la eliminación de datos erróneos o duplicados, el manejo de valores faltantes, la normalización de características, y la transformación de los datos en un formato adecuado para el modelo de IA.
Dimensiones Clave de los Datos en IA
Los datos utilizados en los modelos de IA suelen representarse en una estructura tabular, donde cada fila corresponde a un ejemplo, cada columna a una característica, y una columna específica puede representar la etiqueta, cuando esta es conocida. Para comprender mejor cómo se estructuran los datos, es útil visualizar estos tres conceptos:
1. Ejemplo
Un ejemplo es una instancia individual de datos. Cada ejemplo corresponde a una fila de la tabla que se está utilizando como fuente de datos. Si estamos trabajando con un conjunto de datos de registros de salud, por ejemplo, cada fila puede representar a una persona individual.
Ejemplo: En un conjunto de datos de registros de salud, cada ejemplo puede ser un paciente. Los datos de este paciente incluirán características como su peso, altura, presión arterial, etc.
2. Característica
Una característica es cada propiedad o atributo mensurable de un ejemplo. Las características corresponden a las columnas de la tabla y representan las variables que influyen en la salida de un modelo de IA. Estas características pueden ser numéricas (como la altura o el peso) o categóricas (como el género o el tipo de enfermedad).
Ejemplo: En el caso del conjunto de datos de salud, las características podrían incluir variables como el peso corporal, la altura, el nivel de colesterol o la presión arterial de una persona.
3. Etiqueta
La etiqueta es la variable que estamos tratando de predecir en nuevas muestras de datos. En un modelo de IA supervisado, la etiqueta es el valor que el modelo intenta predecir en función de las características que se proporcionan como entrada.
Ejemplo: En el conjunto de datos de salud, la etiqueta podría ser una variable binaria que indica si una persona tiene una enfermedad cardíaca ("sí" o "no"). Esta etiqueta es lo que el modelo intenta predecir en base a las características del paciente.
La Calidad de los Datos en IA
La calidad de los datos es un factor crucial en el éxito de cualquier modelo de IA. Los datos de baja calidad pueden dar lugar a modelos poco precisos, mientras que los datos de alta calidad permiten al modelo generalizar mejor y realizar predicciones más precisas. Los problemas comunes relacionados con la calidad de los datos incluyen:
- Datos faltantes: Si algunos valores están ausentes, el modelo puede fallar en su tarea o producir resultados inexactos. Es importante tratar los datos faltantes mediante técnicas como la imputación (rellenar valores faltantes con estimaciones) o la eliminación de ejemplos incompletos.
- Datos desbalanceados: Cuando las etiquetas están desproporcionadamente distribuidas (por ejemplo, en un problema de clasificación binaria donde el 90% de los ejemplos pertenecen a una clase y solo el 10% a la otra), los modelos tienden a sesgarse hacia la clase mayoritaria. Esto requiere técnicas de balanceo de datos o ajuste de las métricas de evaluación.
- Datos ruidosos o irrelevantes: Características que no aportan valor pueden confundir al modelo y reducir su rendimiento. Es fundamental identificar y eliminar características irrelevantes o irreales para mejorar la precisión del modelo.
Un dato bien preparado y de calidad puede aumentar drásticamente la eficacia de los modelos de IA. El proceso de preparación de datos es vital, ya que permite que los modelos de IA operen con precisión y eficiencia, aprovechando al máximo la información contenida en los datos.
¿Qué pasa cuando no hay etiquetas?
En muchos casos, especialmente en el aprendizaje no supervisado, las etiquetas no están disponibles. A diferencia del aprendizaje supervisado, donde el modelo aprende a partir de ejemplos etiquetados, el aprendizaje no supervisado intenta descubrir patrones ocultos en los datos sin que se proporcionen salidas específicas.
Supongamos que queremos utilizar IA con el objetivo es agrupar plantas similares. En este caso, no se tiene una etiqueta predeterminada, dado que el agrupamiento puede realizarse por diversas características (tipo de hoja, cantidad, largo de la hoja, etc) y el modelo debe encontrar por sí mismo las agrupaciones dentro de los datos. Este tipo de aprendizaje es particularmente útil en la segmentación de clientes, la detección de anomalías o la compresión de datos.
La falta de etiquetas no significa que los datos no sean valiosos. De hecho, muchos problemas reales del mundo no vienen con respuestas claras o etiquetas, y el aprendizaje no supervisado puede ser clave para abordar estos desafíos.
Conclusiones
En IA, los datos son el recurso más valioso y su preparación adecuada es esencial para el éxito de los modelos. A través de la organización y la limpieza de los datos, junto con una comprensión clara de las dimensiones clave (ejemplos, características y etiquetas), podemos garantizar que los modelos de IA sean efectivos y precisos. Aunque en muchos casos se utilizan etiquetas para entrenar modelos supervisados, también es importante reconocer que no siempre tendremos etiquetas disponibles, y que en esos casos, técnicas de aprendizaje no supervisado pueden ser la solución para extraer valor de los datos.
A medida que avancemos en las próximas lecciones, profundizaremos en cómo preparar y transformar datos para diferentes tipos de tareas de IA, asegurando que puedas aplicar estos conceptos a proyectos del mundo real de manera eficaz.
-
La inteligencia artificial (IA) abarca una amplia gama de tareas que permiten a las máquinas aprender de los datos y tomar decisiones inteligentes.
En esta lección, abordaremos algunas de las tareas más comunes en la IA: es decirlos tipos de problemas o actividades que los sistemas de IA están diseñados para resolver, como la clasificación, la regresión y el clustering, así como otras tareas relevantes como el reconocimiento de patrones, el procesamiento del lenguaje natural (PLN), la visión por computadora y los juegos.
Estas tareas se aplican en diversas áreas de la IA, desde el aprendizaje supervisado y no supervisado hasta el aprendizaje por refuerzo y el aprendizaje profundo.
Aprendizaje Automático Supervisado
El aprendizaje supervisado es una de las tareas más comunes en la IA. Se basa en la idea de entrenar modelos utilizando datos etiquetados, donde las entradas y salidas correctas están claramente definidas. Los algoritmos de aprendizaje supervisado intentan encontrar patrones en estos datos para poder predecir salidas para nuevos datos no vistos.
Clasificación
La clasificación es una tarea de aprendizaje supervisado en la que el objetivo es asignar una etiqueta o clase a una entrada basada en su característica o conjunto de características. Se trata de un problema discreto en el que las salidas son categorías predefinidas.
Tipos de Clasificación:
- Clasificación Binaria: Implica solo dos clases en las que las entradas deben ser clasificadas. Ejemplos típicos incluyen determinar si un email es "spam" o "no spam" o si una transacción es fraudulenta o legítima.
- Clasificación Multiclase: Involucra tres o más clases entre las cuales las entradas pueden ser clasificadas. Un ejemplo común es el diagnóstico médico, donde los síntomas de un paciente podrían clasificarse en varias posibles enfermedades.
Ejemplos:
- Clasificación binaria: en medicina, predicción de si un paciente está en riesgo de contraer diabetes en función de datos clínicos.
- Clasificación multiclase: en biología, se podría utilizar para predecir la especie de un pingüino basándose en sus medidas (medidas de alto y del pico).
Regresión
La regresión es otra tarea de aprendizaje supervisado en la que el objetivo es predecir un valor continuo en lugar de una categoría discreta. El modelo intenta aprender la relación entre las características de entrada y un valor numérico de salida.
Ejemplos:
- En un negocio, se podría utilizar para predecir la cantidad de bicicletas que se rentarán en función del clima y día de la semana (temperatura, humedad, si es día laboral o festivo).
- En finanzas, la regresión se usa para predecir el valor futuro de acciones o bonos.
- En energía, se utiliza para pronosticar el consumo de electricidad según las condiciones climáticas y el uso anterior.
Aprendizaje No Supervisado
El aprendizaje no supervisado se diferencia del aprendizaje supervisado en que no se cuenta con etiquetas en los datos. El objetivo es descubrir patrones o estructuras ocultas en los datos sin una guía específica sobre las salidas correctas. El clustering es una de las tareas más comunes en este enfoque.
Clustering
El clustering es una tarea de aprendizaje no supervisado que busca agrupar instancias similares en grupos o "clusters". El algoritmo identifica agrupaciones basadas en la similitud de las características de las instancias, sin que estas estén etiquetadas de antemano.Ejemplos:
- En biología, se emplea para clasificar plantas en función de sus características comunes.
- En marketing, el clustering se utiliza para segmentar clientes en grupos con características similares para campañas personalizadas.
Otras Tareas Relevantes en IA
Además del aprendizaje supervisado y no supervisado, existen otras tareas críticas en la inteligencia artificial que son fundamentales para diversas aplicaciones, como el reconocimiento de patrones, el procesamiento del lenguaje natural (PLN), la visión por computadora y los juegos.
Reconocimiento de Patrones
El reconocimiento de patrones es una tarea fundamental en IA que consiste en identificar regularidades o patrones dentro de los datos. Este proceso puede ser aplicado tanto en datos estructurados como no estructurados, y puede implicar imágenes, secuencias de texto, sonidos o datos tabulares.
Ejemplos:
- En finanzas, el reconocimiento de patrones se utiliza para identificar tendencias de mercado.
- En seguridad, se emplea para detectar patrones sospechosos en comportamientos de usuarios o accesos a sistemas.
Procesamiento del Lenguaje Natural (PLN)
El Procesamiento del Lenguaje Natural (PLN) es una rama de la IA que se ocupa de la interacción entre las máquinas y el lenguaje humano. Implica el análisis y la interpretación del lenguaje escrito y hablado por las máquinas.
Ejemplos:
- En atención al cliente, los sistemas de PLN automatizan la interacción con los clientes, resolviendo problemas comunes sin intervención humana.
- En análisis de sentimientos, se utiliza para interpretar el tono emocional de los textos en redes sociales o reseñas de productos.
Visión por Computadora
La visión por computadora es el campo de la IA que permite a las máquinas interpretar y comprender el mundo visual a partir de imágenes y videos. Se basa en redes neuronales profundas que pueden aprender a reconocer objetos, personas, escenas y movimientos.
Ejemplos:
- En transporte, la visión por computadora se utiliza en los vehículos autónomos para detectar señales de tráfico, peatones y otros vehículos.
- En salud, se emplea para analizar imágenes médicas y detectar enfermedades como el cáncer de piel o la retinopatía diabética.
- En un uso cotidiano, se podría utilizar la visión por computadora para detectar entre diferentes razas de gatos o animales.
Juegos y Toma de Decisiones
La IA en juegos y toma de decisiones es un área que se centra en crear sistemas que puedan jugar a juegos de estrategia, como el ajedrez o el Go, o que puedan tomar decisiones inteligentes en entornos simulados o del mundo real.
Ejemplos:
- En simulaciones militares, la IA puede simular escenarios tácticos complejos para entrenamiento.
- En finanzas, se utilizan sistemas de toma de decisiones para optimizar portafolios de inversión en función de la evolución del mercado.
Conclusiones
Las tareas comunes en IA abarcan desde problemas supervisados como la clasificación y regresión, hasta enfoques no supervisados como el clustering. Además, la IA también se utiliza para tareas especializadas como el reconocimiento de patrones, el procesamiento del lenguaje natural, la visión por computadora y la toma de decisiones en juegos.
En las próximas lecciones, profundizaremos en cada una de estas tareas, explorando sus algoritmos, métodos y aplicaciones prácticas para que puedas entender cómo funcionan y cómo pueden aplicarse para resolver problemas reales.
-
En la inteligencia artificial (IA), es crucial entender las diferencias entre algoritmos y modelos. Estos dos conceptos, aunque relacionados, desempeñan roles distintos en el proceso de aprendizaje automático. Es común que se utilicen de manera intercambiable, pero es importante clarificar sus diferencias.
Conceptos
- Algoritmo: Es el conjunto de instrucciones o procedimientos que se siguen para realizar una tarea específica. En el contexto de IA, un algoritmo es lo que se utiliza para aprender de los datos, optimizando su funcionamiento para resolver problemas concretos, como la clasificación o la regresión. Algunos ejemplos son la regresión logística, los árboles de decisión y los algoritmos de clustering.
- Modelo: Es el resultado final del entrenamiento de un algoritmo. Cuando se entrena un algoritmo con datos, el algoritmo ajusta sus parámetros para generar un modelo. Este modelo es lo que utilizamos posteriormente para hacer predicciones o tomar decisiones basadas en nuevos datos.
Un modelo entrenado es el producto final que encapsula el conocimiento aprendido del algoritmo sobre los datos proporcionados.
Relación entre Algoritmo y Modelo
Es importante señalar que el algoritmo es la herramienta que crea el modelo. Al proporcionar datos a un algoritmo, este ajusta sus parámetros y produce un modelo entrenado que puede ser usado para realizar predicciones en nuevas entradas.
Por ejemplo, si se desea predecir si una persona está en riesgo de contraer una enfermedad, un algoritmo como la regresión logística se entrena con datos históricos. El resultado final es un modelo que puede hacer predicciones basadas en las características de una nueva persona.
Algoritmos como herramientas para tareas comunes en IA
Los algoritmos se seleccionan de acuerdo a la naturaleza de la tarea que queremos realizar:
- Clasificación: Determinar a qué categoría pertenece un nuevo dato. Ejemplos de algoritmos: Regresión Logística, Máquinas de Soporte Vectorial (SVM), Árboles de Decisión.
- Regresión: Predecir un valor numérico continuo, como el precio de una vivienda. Ejemplos: Regresión Lineal, K-Vecinos más Cercanos (KNN).
- Agrupamiento (Clustering): Agrupar datos sin etiquetas. Ejemplo: K-means, DBSCAN.
El Modelo: resultado final del entrenamiento
El modelo es la representación matemática que emerge del entrenamiento del algoritmo con los datos. Un modelo tiene la capacidad de realizar predicciones, clasificaciones o tomar decisiones sobre datos nuevos basándose en los patrones que ha aprendido.
El modelo es importante porque:
- Generaliza a partir de los datos para hacer predicciones sobre nuevas entradas.
- Es el núcleo de las aplicaciones de IA, ya que encapsula el conocimiento adquirido y permite automatizar tareas o tomar decisiones inteligentes.
No confundir algoritmo con modelo
Es común confundir estos términos porque los modelos son el producto de la aplicación de un algoritmo a un conjunto de datos. Además, los nombres de algunos modelos se derivan del nombre del algoritmo, como en el caso de un modelo de regresión lineal o un modelo de árboles de decisión.
Conclusión: Un algoritmo es el proceso que seguimos para entrenar a un sistema con datos, mientras que el modelo es el resultado final que se genera tras ese proceso. El modelo es lo que realmente utilizamos para hacer predicciones y es el activo clave en aplicaciones de IA.
Ejemplo Práctico para Refuerzo
Tarea: imagina que deseas crear un sistema de IA que prediga si un paciente tiene una enfermedad cardíaca.
- Algoritmo: Seleccionamos el algoritmo de regresión logística, que aprenderá de un conjunto de datos sobre pacientes con características como edad, presión arterial, etc.
- Modelo: Después de entrenar el algoritmo con estos datos, el modelo resultante podrá predecir si un nuevo paciente tiene un alto riesgo de enfermedad cardíaca basándose en sus características.
Con esta estructura, se logra una explicación clara sobre cómo se diferencian y se relacionan los algoritmos y los modelos en IA, con ejemplos prácticos que refuerzan la comprensión.
-
Evaluar un modelo en inteligencia artificial es un proceso fundamental que nos permite saber qué tan bien está funcionando. Un modelo que no se evalúa adecuadamente puede generar predicciones incorrectas, lo que afecta la toma de decisiones. Por ello, es esencial contar con métricas y técnicas de evaluación que nos permitan medir el rendimiento del modelo de manera precisa.
La Importancia de la Evaluación en IA
La evaluación nos permite:
- Medir el rendimiento: Saber si el modelo está resolviendo el problema correctamente.
- Comparar modelos: Determinar qué modelo o enfoque es más adecuado para una tarea específica.
- Detectar sobreajuste (overfitting) o subajuste (underfitting): Identificar si el modelo está generalizando bien a nuevos datos o si está ajustándose demasiado a los datos de entrenamiento.
Métricas Comunes de Evaluación
Las métricas de evaluación varían según el tipo de problema que se desea resolver (clasificación, regresión, clustering). A continuación, veremos algunas de las métricas más comunes utilizadas en IA.
Clasificación
En problemas de clasificación, el objetivo es asignar una categoría a cada entrada. Algunas de las métricas más utilizadas son:
- Exactitud (Accuracy): Es la proporción de predicciones correctas entre el total de predicciones.
Exactitud = (Número de predicciones correctas) / (Número total de predicciones)
Ejemplo: En un modelo de clasificación binaria para detectar spam, la precisión nos indica qué porcentaje de correos electrónicos se clasificaron correctamente como "spam" o "no spam".
- Precisión (Precision): Mide la exactitud de las predicciones positivas. Es la proporción de verdaderos positivos entre todos los ejemplos predichos como positivos.
Precisión = (Verdaderos positivos) / (Verdaderos positivos + Falsos positivos)
Ejemplo: En un sistema de detección de fraude, la precisión nos indica cuántas de las transacciones identificadas como fraudulentas realmente lo son.
- Exhaustividad (Recall): Mide cuántos de los ejemplos positivos fueron correctamente clasificados por el modelo. Es la proporción de verdaderos positivos entre todos los ejemplos que son realmente positivos.
Exhaustividad = (Verdaderos positivos) / (Verdaderos positivos + Falsos negativos)
Ejemplo: En un sistema médico que detecta cáncer, la exhaustividad nos muestra cuántos casos de cáncer fueron identificados correctamente.
- Puntuación F1 (F1 Score): Es la media armónica entre la precisión y la exhaustividad. Es útil cuando se necesita un equilibrio entre ambos.
Puntuación F1 = 2 * (Precisión * Exhaustividad) / (Precisión + Exhaustividad)
Regresión
En problemas de regresión, se busca predecir un valor continuo, como el precio de una casa o el número de bicicletas alquiladas en un día. Algunas de las métricas clave son:
- Error cuadrático medio (Mean Squared Error, MSE): Mide el promedio de los cuadrados de los errores o diferencias entre los valores predichos y los valores reales.
MSE = (1/n) * Σ (valor_real - valor_predicho)^2
Ejemplo: En la predicción del precio de una vivienda, el MSE nos muestra qué tan lejos están las predicciones del precio real.
- Error absoluto medio (Mean Absolute Error, MAE): Es el promedio de las diferencias absolutas entre los valores reales y los predichos.
MAE = (1/n) * Σ |valor_real - valor_predicho|
Ejemplo: Al predecir la demanda de energía, el MAE indica, en promedio, cuántas unidades se desviaron las predicciones de la demanda real.
- Coeficiente de determinación (R^2): Indica qué tan bien los valores predichos se ajustan a los valores reales. Un valor de R2R^2R2 cercano a 1 indica que el modelo predice muy bien.
R^2 = 1 - (Σ (valor_real - valor_predicho)^2 / Σ (valor_real - promedio_valores_reales)^2)
Ejemplo: Si el modelo para predecir el consumo de electricidad tiene un R2=0.95R^2 = 0.95R2=0.95, significa que el 95% de la variabilidad en los datos se explica por el modelo.
Clustering
En problemas de clustering, el objetivo es agrupar los datos en grupos (clusters) sin etiquetas. Las métricas comunes para evaluar este tipo de problemas son:
- Índice de Silueta (Silhouette Score): Mide la cohesión y separación de los clusters. Un valor de silueta cercano a 1 indica que los clusters están bien separados.
Índice de Silueta = (b - a) / max(a, b)
Donde:
- a es la distancia promedio entre un punto y todos los puntos en el mismo cluster.
- b es la distancia promedio entre un punto y todos los puntos en el cluster más cercano.
Validación Cruzada
Un aspecto importante en la evaluación de modelos es la validación cruzada. Esta técnica divide los datos en múltiples subconjuntos para asegurarse de que el modelo no solo funciona bien con los datos de entrenamiento, sino también con datos nuevos. El método más común es la validación cruzada k-fold:
- Los datos se dividen en k subconjuntos.
- Se entrena el modelo con 𝑘 − 1 subconjuntos y se prueba con el subconjunto restante.
- Este proceso se repite k veces, rotando los subconjuntos, y se calcula el promedio de las métricas.
Evaluación del Sobreajuste y Subajuste
- Sobreajuste (Overfitting): Ocurre cuando el modelo aprende demasiado de los datos de entrenamiento, capturando ruido y patrones que no generalizan bien a nuevos datos. Un modelo sobreajustado tiene un rendimiento muy alto en el conjunto de entrenamiento, pero bajo en el conjunto de prueba.
- Subajuste (Underfitting): Ocurre cuando el modelo no es lo suficientemente complejo para captar los patrones en los datos. Un modelo subajustado tiene un rendimiento bajo tanto en el conjunto de entrenamiento como en el de prueba.
Curvas ROC y AUC
Para modelos de clasificación binaria, una herramienta útil para evaluar su rendimiento es la curva ROC (Receiver Operating Characteristic). Esta curva traza la tasa de verdaderos positivos frente a la tasa de falsos positivos a diferentes umbrales de decisión. El área bajo la curva ROC, o AUC (Area Under the Curve), nos indica qué tan bien el modelo distingue entre las clases.
- Un valor de AUC = 1 indica un modelo perfecto.
- Un valor de AUC = 0.5 indica que el modelo no es mejor que adivinar al azar.
Conclusiones
La evaluación de modelos en IA es un paso crítico para garantizar que los modelos no solo se ajusten bien a los datos de entrenamiento, sino que también generalicen correctamente a nuevos datos. Con las métricas adecuadas y las técnicas de validación, podemos comparar modelos, detectar problemas de ajuste y mejorar el rendimiento de los sistemas de inteligencia artificial.
En las próximas lecciones, cuando pongamos en práctica los sucesivos modelos de IA vistos anteriormente, pondremos también en práctica su evaluación.
-
Los proyectos de inteligencia artificial (IA) requieren un conjunto diverso de habilidades técnicas y conocimientos especializados. Desde la ciencia de datos y la experiencia en el dominio, hasta las habilidades en tecnología de la información (TI), cada aspecto juega un papel crucial en el ciclo de vida de un proyecto de IA. En esta lección, exploramos los requisitos técnicos esenciales, las habilidades necesarias y los conocimientos que se requieren para implementar soluciones de IA efectivas.
Requisitos de Habilidades en Ciencia de Datos
La ciencia de datos es el núcleo de cualquier proyecto de IA, ya que el éxito de un modelo depende en gran medida de la cantidad, la calidad y la relevancia de los datos disponibles. Las habilidades necesarias en ciencia de datos abarcan desde la capacidad de recopilar y limpiar datos hasta la comprensión de técnicas avanzadas de análisis y visualización de datos.
Exploración e Investigación de Datos
Antes de comenzar a construir un modelo de IA, es esencial realizar una fase de exploración de datos. Durante esta fase, el equipo debe responder preguntas fundamentales, tales como:
- ¿Qué datos están disponibles? Comprender el tipo y la cantidad de datos es clave para evaluar si un proyecto de IA es viable.
- ¿Cómo se relacionan los datos con los problemas que necesitan resolverse? Se necesita un análisis detallado para garantizar que los datos puedan abordar directamente el problema que se desea resolver.
- ¿Qué método de IA o aprendizaje automático (AA) sería el más adecuado? La elección de los métodos depende del tipo de datos y del objetivo del proyecto (clasificación, predicción, agrupamiento, etc.).
- ¿Cómo debe medirse el éxito? Establecer métricas claras para medir el rendimiento del modelo es crucial para garantizar que el sistema cumple con los objetivos deseados.
Limpieza y Preparación de Datos
La preparación de datos es un paso crítico. Los datos en bruto a menudo contienen errores, valores faltantes o inconsistencias que pueden degradar el rendimiento de un modelo de IA. Algunas de las tareas de preparación incluyen:
- Limpieza de datos: Eliminación de duplicados, corrección de errores y manejo de valores faltantes.
- Normalización y transformación: Escalar los datos para que sean uniformes y compatibles con los algoritmos de IA.
- Ingeniería de características: Crear nuevas variables a partir de las existentes para mejorar el rendimiento del modelo.
Conocimientos Especializados en el Dominio
El conocimiento especializado en el dominio es esencial en cualquier proyecto de IA. Este tipo de conocimiento permite comprender profundamente el contexto en el que se aplicará la IA y garantiza que los modelos se alineen con las necesidades y objetivos específicos del problema que se está abordando.
Importancia de los Expertos en el Dominio
Los expertos en el dominio tienen un papel fundamental en varias etapas del proyecto, desde la identificación del problema hasta la validación de los resultados del modelo. Estos expertos ayudan a:
- Reconocer el problema: Los expertos del dominio comprenden las complejidades del campo de aplicación y pueden identificar las áreas donde la IA puede ser más efectiva.
- Validar los datos: Garantizan que los datos utilizados para entrenar los modelos sean precisos y representativos del problema real.
- Evaluar el rendimiento del modelo: Los expertos comparan los resultados del modelo con su experiencia previa para determinar si las predicciones son útiles y confiables.
Ejemplos de Expertos en Dominios Específicos
Dependiendo del contexto del proyecto de IA, los expertos del dominio pueden variar:
- Salud: En un proyecto que busca optimizar la distribución de vacunas, los expertos en enfermedades infecciosas y virólogos son fundamentales.
- Clima: Para proyectos centrados en predecir el cambio climático, es crucial contar con meteorólogos y expertos en emisiones de gases.
Requisitos de Habilidades en TI
Una vez que se ha completado la fase de investigación y se ha identificado el modelo adecuado, es hora de implementarlo en una solución práctica. Aquí es donde entran en juego las habilidades en TI, que son esenciales para automatizar, escalar y mantener el modelo.
Desarrollo de Software y Automatización
El desarrollo de una solución basada en IA a menudo implica la integración del modelo en un sistema mayor, que puede requerir habilidades en desarrollo de software, automatización y manejo de infraestructura. Las preguntas clave a responder en esta fase incluyen:
- ¿Cómo automatizamos el proceso de aprendizaje automático? Automatizar la actualización del modelo y su despliegue puede mejorar la eficiencia del sistema.
- ¿Cómo implementamos la solución a gran escala? Asegurar que la solución funcione en producción, con capacidad de expansión y gestión de grandes volúmenes de datos.
- ¿Cómo mantenemos el sistema a largo plazo? La solución debe poder actualizarse, mantenerse segura y seguir funcionando de manera óptima a medida que cambian los requisitos.
Especialistas en TI Clave
Poner en marcha una solución de IA puede requerir la colaboración de varios especialistas en TI, como:
- Administradores de bases de datos: Garantizan que el sistema de IA tenga acceso continuo a datos limpios y estructurados.
- Desarrolladores de software: Codifican y mantienen las aplicaciones de IA, asegurando su integración con otros sistemas.
- Administradores de sistemas y seguridad: Gestionan la infraestructura, ya sea local o en la nube, y aseguran la protección de los datos y del sistema.
Herramientas y Plataformas para la IA
Además de las habilidades técnicas, es importante conocer las herramientas y plataformas que pueden facilitar el desarrollo de soluciones de IA. Estas herramientas permiten a los equipos desarrollar, entrenar, evaluar y desplegar modelos de IA de manera más eficiente.
Herramientas de Ciencia de Datos
- Librerías de Python: NumPy, Pandas, scikit-learn y TensorFlow son algunas de las librerías más utilizadas en ciencia de datos y aprendizaje automático.
- Entornos de desarrollo: Jupyter Notebooks y Google Colab son entornos populares para explorar datos, entrenar modelos y visualizar resultados.
Plataformas de IA en la Nube
Muchas soluciones de IA se desarrollan y ejecutan en la nube debido a las ventajas de escalabilidad y potencia computacional. Algunas plataformas clave incluyen:
- Google Cloud AI: Ofrece una gama de servicios para el desarrollo de modelos, desde la visión por computadora hasta el procesamiento del lenguaje natural.
- Amazon Web Services (AWS) AI: Proporciona herramientas para entrenar modelos y desplegarlos a gran escala en la nube.
- Microsoft Azure AI: Ofrece servicios de IA que incluyen aprendizaje automático, reconocimiento de voz, visión por computadora y mucho más.
Ética y Consideraciones Legales en IA
En el desarrollo de soluciones de IA, también es crucial considerar los aspectos éticos y legales. Con el aumento en el uso de IA, cuestiones como la privacidad de los datos, el sesgo algorítmico y la transparencia han cobrado relevancia.
Privacidad de los Datos
Las leyes de protección de datos, como el Reglamento General de Protección de Datos (GDPR) en Europa, establecen reglas estrictas sobre cómo deben gestionarse los datos personales en proyectos de IA. Es esencial asegurar que los datos utilizados se manejen de manera ética y conforme a las regulaciones.
Transparencia y Explicabilidad
El concepto de "caja negra" en la IA plantea un desafío en términos de transparencia. Es fundamental que los desarrolladores sean capaces de explicar cómo un modelo de IA toma decisiones, especialmente en aplicaciones críticas como la salud, el derecho o las finanzas.
Conclusiones
Desarrollar e implementar soluciones de IA requiere un amplio conjunto de habilidades que abarcan ciencia de datos, conocimientos especializados en el dominio y habilidades técnicas en TI. Desde la preparación de datos hasta la implementación de soluciones escalables y seguras, los proyectos de IA demandan la colaboración de equipos multidisciplinarios. Además, es crucial tener en cuenta las consideraciones éticas y legales que acompañan el desarrollo de estas tecnologías para garantizar que se utilicen de manera responsable y efectiva.
-
-
-
 Campus
Campus
