 Campus
Campus
Diagrama de temas
-
-
En el campo de la inteligencia artificial, el aprendizaje automático (AA) es una de las ramas más fundamentales y potentes. Su capacidad de analizar grandes volúmenes de datos, identificar patrones y hacer predicciones ha transformado industrias enteras, desde la atención médica y las finanzas hasta la manufactura y el marketing. A medida que las empresas buscan aprovechar estos beneficios, surge la necesidad de entender cómo diseñar e implementar un enfoque sólido de aprendizaje automático para resolver problemas específicos del mundo real.
En esta sección, nos enfocaremos en cómo diseñar un enfoque práctico para implementar un modelo de AA eficaz y eficiente. Desde la definición del problema hasta la implementación y mantenimiento del modelo, recorreremos cada paso clave que forma parte del ciclo de vida de un proyecto de AA. Esta metodología no solo cubre el proceso técnico del desarrollo, sino que también ofrece una perspectiva práctica sobre cómo gestionar los datos, seleccionar los algoritmos adecuados, y garantizar que el modelo se mantenga relevante a lo largo del tiempo.
Temas clave que veremos en esta sección:
- Un repaso sobre el aprendizaje automático: Recordaremos los conceptos esenciales para refrescar las bases teóricas necesarias para los próximos pasos.
- Definición del problema: Cómo formular correctamente el problema que se quiere resolver con AA y definir las variables clave.
- Recolección y preparación de datos: Cómo manejar los datos crudos, limpiarlos y transformarlos en un formato adecuado para el algoritmo.
- Selección de algoritmos: Cómo elegir el algoritmo adecuado según el tipo de problema (clasificación, regresión, clustering).
- Entrenamiento del modelo: El proceso mediante el cual un modelo ajusta sus parámetros para aprender de los datos.
- Evaluación y ajuste iterativo: Cómo evaluar el rendimiento del modelo y refinarlo para mejorar su precisión y generalización.
- Sesgo y varianza: Entender el equilibrio entre sesgo y varianza para evitar tanto el sobreajuste como el subajuste.
- Ajuste de hiperparámetros: Estrategias para optimizar el rendimiento del modelo ajustando los hiperparámetros clave.
-
Ya hemos explorado anteriormente los fundamentos del aprendizaje automático, pero dado que esta sección se enfocará en el diseño de enfoques prácticos para implementar modelos de aprendizaje automático, es útil revisar los conceptos clave que forman la base de este campo. En esta lección, revisaremos de manera más detallada los principios esenciales y los componentes clave que hemos estudiado anteriormente, preparando el terreno para profundizar en cómo construir sistemas de IA eficientes y efectivos.
Recordando: ¿qué es el aprendizaje automático?
El aprendizaje automático es una rama de la inteligencia artificial que permite a los sistemas aprender de los datos y tomar decisiones o hacer predicciones sin ser programados explícitamente para cada tarea. En lugar de seguir una serie de reglas rígidas, los algoritmos de aprendizaje automático analizan datos y detectan patrones que les permiten generalizar sus predicciones a partir de nuevas muestras de datos.
La verdadera fortaleza del aprendizaje automático radica en su capacidad para aprender y mejorar con el tiempo. Esto significa que, a medida que el algoritmo se expone a más datos, refina su capacidad de análisis, haciéndose más preciso y efectivo en la resolución de problemas. Este proceso de mejora constante es lo que distingue al aprendizaje automático de los métodos de programación tradicionales, que son estáticos y dependen de las reglas definidas por los desarrolladores.
Tipos de Aprendizaje Automático: Un Repaso
Como mencionamos anteriormente en el curso, el aprendizaje automático se divide en diferentes tipos según la naturaleza de los datos y las tareas a realizar. Hagamos un breve repaso:
Aprendizaje Supervisado: En este enfoque, el algoritmo se entrena con datos etiquetados. Esto significa que cada ejemplo de datos de entrada tiene una salida correspondiente, y el objetivo es aprender la relación entre ambos. Los problemas comunes incluyen la clasificación (asignar etiquetas a categorías) y la regresión (predecir valores continuos).
Ejemplo: Predecir si un correo electrónico es spam o no (clasificación), o predecir el precio de una casa basado en características como el tamaño y la ubicación (regresión).
Aprendizaje No Supervisado: Aquí, el modelo no tiene acceso a salidas etiquetadas. En lugar de eso, busca patrones o estructuras ocultas en los datos. Un ejemplo común es el clustering, donde el objetivo es agrupar los datos en categorías basadas en similitudes.
Ejemplo: Agrupar clientes en diferentes segmentos basados en sus comportamientos de compra sin conocer previamente las categorías.
Aprendizaje por Refuerzo: En este caso, un agente interactúa con un entorno y aprende a tomar decisiones basadas en las recompensas o castigos que recibe. A través de la retroalimentación obtenida de sus acciones, el agente ajusta su estrategia para maximizar las recompensas a largo plazo.
Ejemplo: Enseñar a un robot a navegar por una habitación evitando obstáculos y alcanzando un objetivo.
¿Qué es un Modelo de Aprendizaje Automático?
Un modelo de aprendizaje automático es esencialmente una representación matemática que se ajusta a los datos mediante un algoritmo. Es la herramienta práctica que implementa el análisis y toma de decisiones a partir de datos previamente entrenados. En otras palabras, el modelo es el resultado tangible del proceso de aprendizaje automático y lo que se utiliza para hacer inferencias sobre nuevos datos.
Un modelo de aprendizaje automático es una versión especializada de un modelo estadístico, que es cualquier representación matemática que toma en cuenta patrones dentro de un conjunto de datos para hacer estimaciones sobre una población más amplia. En este sentido, un modelo estadístico y un modelo de aprendizaje automático tienen puntos en común, pero el aprendizaje automático generalmente implica un enfoque más automatizado y adaptable que los métodos estadísticos tradicionales.
- Ejemplo de un modelo estadístico: Supongamos que tienes un conjunto de datos que contiene las edades y alturas de unas pocas centenas de personas. A partir de estos datos, puedes construir un modelo que prediga cómo cambia la altura en función de la edad. Este modelo podría luego extrapolar esta relación a una población más amplia, permitiéndote hacer estimaciones, como por ejemplo, a qué edad los ciudadanos de un país suelen dejar de crecer.
Los modelos de aprendizaje automático funcionan de manera similar, pero con una diferencia clave: la capacidad del modelo para aprender automáticamente a partir de los datos y mejorar con el tiempo sin intervención explícita del ser humano.
Algoritmos de Aprendizaje Automático
Antes de entrenar el modelo de aprendizaje automático inicial, tendrás que seleccionar uno o varios algoritmos que usará para producir el resultado que necesita. Por ejemplo, si necesitas realizar una tarea de clasificación, como determinar si alguien está en riesgo de contraer una enfermedad en función de varios insumos (factores de estilo de vida, edad, sexo, etc.), podría usar la regresión logística, el bosque aleatorio, Bayes ingenuos o uno de varios otros algoritmos.
En la ilustración siguiente se muestran los algoritmos de ejemplo en los tres modos principales de aprendizaje automático (supervisado, no supervisado y refuerzo) y tres resultados/tareas (regresión, clasificación y agrupación en clústeres). Esta no es una lista exhaustiva de algoritmos, solo algunos de los más comunes utilizados en el campo (aparte de las redes neuronales utilizadas en el aprendizaje profundo, que están fuera del ámbito de este curso).
Conclusión
En esta lección, hemos repasado los principios fundamentales del aprendizaje automático, destacando la capacidad de los algoritmos para aprender de los datos y mejorar su rendimiento con el tiempo. A medida que avanzamos en esta sección sobre diseño de enfoques de aprendizaje automático, comprender estos conceptos será clave para abordar los desafíos prácticos y diseñar sistemas que puedan resolver problemas complejos de manera eficiente. Hemos recordado que la selección de algoritmos, el entrenamiento, la evaluación y la optimización son los pilares sobre los que se construyen las soluciones de aprendizaje automático, y estos elementos guiarán nuestro enfoque en las siguientes lecciones.
-
- Al implementar un enfoque de aprendizaje automático, se deben considerar varias etapas clave. Cada una de estas etapas contribuye al diseño, desarrollo y mejora de los modelos. A continuación, se revisan las etapas básicas en el ciclo de vida de un proyecto de aprendizaje automático:
- Definición del problema: El primer paso es formular claramente el problema que se desea resolver. Esto incluye definir el objetivo, las variables a predecir (etiquetas), y los posibles enfoques a utilizar.
- Recolección y preparación de datos: Los modelos de aprendizaje automático dependen de la calidad y cantidad de datos. Aquí, los datos se recolectan, se limpian y se transforman en un formato adecuado para el algoritmo.
- Selección de un algoritmo: Dependiendo del tipo de problema (clasificación, regresión, clustering, etc.), se selecciona el algoritmo más adecuado. La elección del algoritmo es crucial, ya que diferentes algoritmos tienen distintas capacidades de generalización y rendimiento.
- Entrenamiento del modelo: El algoritmo se expone a los datos de entrenamiento, y ajusta sus parámetros internos para aprender a realizar las tareas requeridas. El objetivo es minimizar los errores durante el entrenamiento, de manera que el modelo sea capaz de realizar predicciones precisas.
- Evaluación del modelo: Una vez entrenado, el modelo se evalúa utilizando datos de prueba que no fueron utilizados durante el entrenamiento. Esto permite medir su capacidad de generalizar a datos nuevos y desconocidos.
- Ajuste y optimización: Si el rendimiento del modelo es insatisfactorio, se ajustan los hiperparámetros del algoritmo, se prueban diferentes enfoques o se utilizan técnicas avanzadas como la validación cruzada para mejorar el rendimiento.
- Implementación y mantenimiento: Cuando el modelo ha alcanzado un rendimiento aceptable, se implementa en un entorno real para hacer predicciones o tomar decisiones en el mundo real. Es fundamental seguir monitorizando el rendimiento del modelo a lo largo del tiempo, ya que el entorno y los datos pueden cambiar, provocando que el modelo se vuelva menos efectivo.
Paso 1: Definición del problema
Definir claramente el problema que se quiere resolver utilizando aprendizaje automático y establecer los objetivos de predicción.
Definición del problema en AA
El primer paso crucial en cualquier proyecto de AA es definir claramente el problema que se desea resolver. Una buena definición del problema ayuda a guiar todas las decisiones posteriores, desde la selección de los datos hasta la implementación del modelo. Un problema mal definido puede conducir a resultados ineficaces, desperdicio de recursos y soluciones que no abordan las necesidades reales.
Identificación de las Variables
Un aspecto fundamental de la definición del problema es identificar las variables clave, que generalmente incluyen:
- Variables objetivo o etiquetas: Es lo que se desea predecir o estimar. Ejemplo: ¿Es probable que un cliente cancele su suscripción?
- Variables de entrada o características: Son los datos que se utilizarán para hacer las predicciones. Estas pueden incluir datos demográficos, históricos, o de comportamiento.
Tipos de Problemas de Aprendizaje Automático
Dependiendo del problema, los proyectos de AA suelen dividirse en varias categorías:
- Clasificación: Asignar una categoría a una entrada (por ejemplo, determinar si un correo electrónico es spam o no).
- Regresión: Predecir un valor continuo (como predecir el precio de una vivienda).
- Clustering: Agrupar elementos en categorías no predefinidas (como segmentar clientes en función de sus comportamientos de compra).
Importancia de una Buena Definición del Problema
Una vez que se tiene una definición clara del problema, es posible seleccionar los datos relevantes y planificar la estrategia de AA. La definición de variables es crítica ya que estas determinan el tipo de modelo y los algoritmos que se utilizarán.
Conclusión
La definición del problema es el primer paso crítico en cualquier proyecto de AA. Con una definición clara, los desarrolladores pueden concentrarse en los enfoques adecuados para recopilar, preparar y analizar los datos.
Paso 2: Recolección y preparación de datos
En esta lección, profundizaremos en el segundo paso esencial del ciclo de vida de un proyecto de aprendizaje automático: la recolección y preparación de datos. Este paso es crítico, ya que los modelos de aprendizaje automático dependen en gran medida de la calidad y cantidad de los datos disponibles para su entrenamiento. La frase “basura entra, basura sale” es especialmente cierta en este contexto. Incluso con algoritmos avanzados, los resultados serán pobres si los datos son inadecuados o mal preparados.
El objetivo de esta lección es aprender cómo recolectar, limpiar y transformar datos para maximizar su utilidad en los modelos de aprendizaje automático. Veremos cómo seleccionar las fuentes de datos, cómo manejar los datos faltantes, y qué técnicas emplear para normalizar, escalar y estructurar los datos para alimentar los algoritmos de manera eficiente.
Objetivo
El objetivo de esta lección es que comprendas la importancia de la calidad de los datos y aprendas cómo prepararlos de manera efectiva para entrenar modelos de aprendizaje automático. Al finalizar, estarás equipado para identificar las mejores prácticas en la preparación de datos, asegurando que tu modelo se entrene con la información correcta y en el formato adecuado.Recolección de datos
Fuentes de datos
La primera etapa de este proceso implica identificar y recolectar los datos adecuados para resolver el problema. Los datos pueden provenir de diversas fuentes, como bases de datos, APIs, web scraping, sensores o incluso archivos de texto o CSVs. Es crucial considerar que las fuentes de datos deben ser relevantes y fiables para garantizar la integridad del modelo. Aquí se recomienda:
- Bases de datos relacionales: Excelentes para datos estructurados con relaciones claras entre diferentes entidades (como clientes y productos).
- APIs: Permiten acceder a datos dinámicos y actualizados de servicios en línea, como redes sociales o servicios financieros.
- Datos abiertos: Fuentes públicas como el portal de datos abiertos del gobierno o bases de datos científicas que ofrecen datos valiosos para entrenamiento.
Es importante identificar las características de los datos que serán clave para el modelo. Por ejemplo, si estás trabajando en un modelo de predicción de precios de viviendas, necesitarás recopilar datos como la ubicación, tamaño de la propiedad, número de habitaciones y otros factores relacionados.
Preparación de datos
Limpieza de datos
La limpieza de datos es un paso crítico. La mayoría de los conjuntos de datos reales contienen errores, valores faltantes, duplicados o entradas irrelevantes. Si no se corrigen estos problemas, el modelo entrenado será propenso a errores. Los pasos clave incluyen:
- Eliminación o imputación de valores faltantes: Los valores faltantes pueden manejarse eliminando las filas o columnas incompletas, o mediante técnicas de imputación, como rellenar con la media, mediana o valores derivados de otros cálculos. Por ejemplo, en un dataset sobre el precio de los automóviles, si faltan valores en la columna de kilometraje, podemos imputar estos valores con la media del kilometraje de autos similares.
- Eliminación de duplicados: Los datos duplicados deben ser eliminados, ya que pueden sesgar los resultados del modelo. Por ejemplo, si tienes entradas duplicadas en un conjunto de datos de clientes, el modelo podría sobrevalorar la importancia de ciertos patrones.
- Corrección de datos erróneos: Si se encuentran valores claramente incorrectos (por ejemplo, una edad de 150 años en un conjunto de datos demográficos), es necesario corregirlos o eliminarlos.
Transformación de datos
Después de limpiar los datos, a menudo es necesario transformarlos para que sean adecuados para el algoritmo de aprendizaje automático. Este proceso puede incluir:
- Escalado y normalización: Muchos algoritmos de aprendizaje automático, como la regresión logística o las redes neuronales, funcionan mejor cuando los datos numéricos están escalados o normalizados. El escalado (normalmente en un rango de 0 a 1 o -1 a 1) ayuda a garantizar que todas las características contribuyan por igual al modelo. Un ejemplo común es el escalado de precios y tamaño de las propiedades en un conjunto de datos inmobiliarios.
- Codificación de variables categóricas: Si tienes variables categóricas (por ejemplo, "masculino" y "femenino"), debes convertirlas en una representación numérica antes de que puedan ser utilizadas por el modelo. Esto puede hacerse mediante técnicas como la codificación de etiquetas o la codificación one-hot, donde cada categoría se representa como una columna binaria (1 o 0).
- Generación de nuevas características: Este proceso, conocido como ingeniería de características, consiste en crear nuevas variables a partir de las ya existentes que puedan ayudar a mejorar el rendimiento del modelo. Por ejemplo, en un modelo de predicción de fraude en transacciones bancarias, podrías generar una nueva característica que mida la frecuencia con la que se realizan transacciones fuera del país del cliente.
Selección de características
No todas las variables disponibles en un conjunto de datos serán útiles para el modelo. Algunas pueden ser irrelevantes o incluso perjudiciales para el rendimiento. Por lo tanto, el proceso de selección de características es clave para reducir la dimensionalidad de los datos y centrarse en las variables que tienen mayor impacto en el resultado. Las técnicas comunes incluyen:
- Selección basada en correlación: Identificar y eliminar variables altamente correlacionadas que podrían introducir redundancia.
- Selección basada en importancia: Algunas técnicas, como los árboles de decisión o los bosques aleatorios, pueden evaluar la importancia de cada característica en el modelo, lo que permite eliminar las que tienen poca o ninguna relevancia.
Herramientas para la recolección y preparación de datos
En la práctica, utilizarás herramientas como pandas en Python para manejar grandes volúmenes de datos, NumPy para operaciones numéricas, y bibliotecas específicas como scikit-learn para la transformación y selección de características. Además, en proyectos más grandes y complejos, soluciones como Azure Machine Learning o AWS Sagemaker te permiten automatizar gran parte del proceso de preparación de datos y ofrecer potentes pipelines para transformar y escalar los datos de manera eficiente.
Conclusión
En esta lección, hemos cubierto cómo recolectar y preparar los datos necesarios para construir modelos de aprendizaje automático efectivos. Este proceso incluye la recolección de datos de fuentes fiables, su limpieza y transformación, y la selección de características que maximicen el rendimiento del modelo. Recordar la importancia de esta etapa es crucial, ya que cualquier error o negligencia en esta fase puede impactar negativamente en todo el proyecto. En la siguiente lección, abordaremos la selección de algoritmos, el siguiente paso en la construcción de un modelo de AA.
Paso 3: Selección de Algoritmos
Una vez que los datos han sido recolectados y preparados adecuadamente, el siguiente paso crítico es la selección de algoritmos. La elección del algoritmo correcto determinará en gran medida el éxito de tu modelo de aprendizaje automático. Con un vasto número de algoritmos disponibles, puede ser abrumador elegir el más adecuado, ya que cada algoritmo tiene sus propias ventajas y desventajas dependiendo del tipo de datos y la tarea que se va a resolver.
En esta lección, vamos a analizar cómo seleccionar el algoritmo más adecuado para tu problema particular, considerando factores como la velocidad de entrenamiento, la precisión, la complejidad y la interpretabilidad. También veremos cómo abordar la experimentación con varios algoritmos antes de decidir cuál es el más adecuado para tu proyecto.
Objetivo
El objetivo de esta lección es que aprendas a seleccionar los algoritmos más adecuados para abordar diferentes tipos de problemas en aprendizaje automático, considerando tanto el tipo de datos como las características del problema en cuestión.Factores a considerar en la selección de algoritmos
Al seleccionar un algoritmo, debes tener en cuenta varios factores importantes:
- Velocidad de entrenamiento: Algunos algoritmos, como las redes neuronales profundas, requieren grandes cantidades de tiempo y recursos computacionales para entrenar, especialmente en conjuntos de datos grandes. En contraste, los modelos más simples, como la regresión logística o los árboles de decisión, pueden entrenarse mucho más rápidamente.
- Efectividad del modelo: No todos los algoritmos se adaptan bien a todos los problemas. Por ejemplo, los bosques aleatorios suelen ser más efectivos para problemas con datos desbalanceados o ruidosos que los modelos lineales.
- Requisitos de preparación de datos: Algunos algoritmos, como las máquinas de vectores de soporte (SVM), requieren que los datos sean escalados y normalizados antes de ser utilizados, mientras que otros algoritmos, como los árboles de decisión, son más robustos ante la variabilidad en las características.
- Complejidad: Algunos algoritmos, como las redes neuronales, son extremadamente complejos y difíciles de interpretar, lo que puede ser un inconveniente si necesitas que el modelo sea explicable. En este caso, un árbol de decisión o un modelo lineal puede ser más adecuado.
- Transparencia e interpretabilidad: Dependiendo del uso previsto del modelo, es posible que necesites que el algoritmo sea fácilmente comprensible para los usuarios o los reguladores. Por ejemplo, un médico podría preferir utilizar un modelo que pueda interpretar fácilmente para justificar sus decisiones, como un árbol de decisión, en lugar de una "caja negra" como una red neuronal.
- Disponibilidad: No todos los algoritmos están disponibles en todas las bibliotecas o plataformas. Debes considerar las herramientas y recursos disponibles en tu entorno de desarrollo. Por ejemplo, scikit-learn ofrece una amplia variedad de algoritmos estándar, mientras que para redes neuronales más avanzadas, puedes requerir bibliotecas como TensorFlow o PyTorch.
Tipos de algoritmos y cuándo usarlos
Los algoritmos de aprendizaje automático se pueden dividir en diferentes categorías según el tipo de problema que abordan:
- Clasificación: Se utiliza para problemas donde el objetivo es asignar una etiqueta a una entrada. Ejemplos de algoritmos comunes incluyen la regresión logística, árboles de decisión, máquinas de vectores de soporte (SVM) y bosques aleatorios. La regresión logística es útil cuando hay una relación lineal entre las características y la etiqueta, mientras que los bosques aleatorios son más efectivos en datos ruidosos.
- Regresión: Se usa para predecir valores continuos. Ejemplos incluyen la regresión lineal, los bosques aleatorios y las redes neuronales. La regresión lineal es adecuada para problemas simples con relaciones lineales claras, mientras que las redes neuronales o los métodos de boosting son más efectivos para problemas complejos.
- Clustering: Se utiliza cuando el objetivo es agrupar datos similares sin etiquetas. Los algoritmos populares incluyen k-means y clustering jerárquico. K-means es más eficiente en conjuntos de datos grandes, mientras que el clustering jerárquico proporciona más flexibilidad para manejar diferentes formas de datos.
Experimentación con múltiples algoritmos
En muchos casos, no sabrás de antemano qué algoritmo será el mejor para tu problema. Por esta razón, es común experimentar con múltiples algoritmos. Este proceso de experimentación puede involucrar:
- Entrenamiento de múltiples modelos: Entrenar diferentes algoritmos utilizando el mismo conjunto de datos y compararlos para ver cuál produce los mejores resultados.
- Evaluación del rendimiento: Comparar los modelos utilizando métricas como la precisión, el recall, el F1-score o el AUC (Área bajo la curva), dependiendo del tipo de problema que estés abordando.
- Selección del mejor modelo: Basándote en los resultados, seleccionar el modelo que mejor se ajuste a tus necesidades. En algunos casos, el modelo más preciso puede no ser el más adecuado, especialmente si es demasiado complejo o difícil de interpretar.
Herramientas para seleccionar y experimentar con algoritmos
Existen diversas herramientas que pueden ayudarte a automatizar el proceso de selección de algoritmos. Plataformas como Azure Machine Learning y AutoML de Google permiten entrenar múltiples modelos de manera automática y seleccionar el más prometedor en función del rendimiento. Estas plataformas reducen significativamente el tiempo y el esfuerzo necesarios para experimentar con diferentes algoritmos.
Conclusión
La selección de algoritmos es una parte crítica del proceso de diseño de modelos de aprendizaje automático. Es importante considerar no solo la precisión del modelo, sino también otros factores como la velocidad de entrenamiento, la complejidad y la interpretabilidad. No existe un único "mejor" algoritmo para todos los problemas, por lo que debes estar preparado para experimentar con múltiples enfoques. En la siguiente lección, exploraremos cómo entrenar estos modelos utilizando los algoritmos seleccionados.
Paso 4: Entrenamiento del Modelo
Una vez que se ha seleccionado el algoritmo adecuado, el siguiente paso crucial es el entrenamiento del modelo. Durante este proceso, el modelo utiliza los datos de entrenamiento para aprender patrones y relaciones significativas. Este es el corazón del aprendizaje automático, donde los algoritmos ajustan sus parámetros internos para minimizar el error y hacer predicciones precisas. Este proceso puede variar significativamente en complejidad y duración según el tipo de modelo que utilices y la cantidad de datos disponibles.
En esta lección, examinaremos el proceso de entrenamiento del modelo, desde la configuración de los datos y la optimización de los parámetros, hasta el uso de técnicas avanzadas como el "early stopping". Además, haremos énfasis en cómo diferentes herramientas, como Azure Custom Vision, Language Studio, y Azure Machine Learning, nos permiten realizar este entrenamiento. Cada una de estas plataformas tiene su propia interfaz y características específicas que facilitan el proceso de diferentes maneras.
Objetivo
El objetivo de esta lección es entender cómo entrenar eficazmente un modelo de aprendizaje automático utilizando diferentes plataformas y herramientas. Aprenderás a configurar los datos, ajustar los parámetros y emplear técnicas avanzadas para garantizar que tu modelo realice predicciones precisas. También veremos cómo seleccionar la plataforma adecuada según el tipo de problema y cómo aprovechar las distintas interfaces que ofrecen las herramientas que hemos utilizado en este curso.El proceso de entrenamiento
El entrenamiento de un modelo implica exponer el algoritmo a los datos de entrenamiento y permitir que ajuste sus parámetros para optimizar su rendimiento. El objetivo es minimizar la diferencia entre las predicciones del modelo y los valores reales (el error). Este proceso es iterativo y normalmente se repite muchas veces (en lo que se denomina "epochs") para garantizar que el modelo se ajuste bien a los datos.
- Configuración
de los datos
Antes de iniciar el entrenamiento, debes asegurarte de que los datos estén bien organizados. Esto implica la normalización o escalado de las características, la selección de las características adecuadas y la división de los datos en conjuntos de entrenamiento, validación y prueba. Estas etapas son esenciales para garantizar que el modelo aprenda de manera efectiva sin sobreajustarse a los datos. - Inicialización
del modelo
El modelo comienza con parámetros iniciales que pueden ser aleatorios o derivados de una estrategia de inicialización específica. En las redes neuronales, por ejemplo, los pesos iniciales se suelen inicializar aleatoriamente, aunque hay métodos como la inicialización de Xavier o He que mejoran la velocidad de convergencia. - Forward
propagation y cálculo de error
En cada iteración de entrenamiento, el modelo realiza una propagación hacia adelante ("forward propagation"), que implica realizar cálculos basados en los parámetros actuales del modelo para hacer predicciones. Luego, se calcula el error comparando las predicciones con los valores reales (etiquetas) del conjunto de datos. Dependiendo del tipo de problema, se utilizan distintas funciones de pérdida, como el error cuadrático medio (MSE) en problemas de regresión o la entropía cruzada en clasificación. - Optimización
y ajuste de parámetros
El siguiente paso es reducir el error del modelo ajustando los parámetros. Aquí es donde los algoritmos de optimización juegan un papel crucial. El descenso por gradiente es uno de los métodos más comunes, en el cual el modelo ajusta sus parámetros en la dirección que minimiza el error. Los optimizadores más avanzados, como Adam o RMSprop, son utilizados en modelos más complejos para mejorar la velocidad y precisión del entrenamiento. - Evaluación
y retropropagación
Después de calcular el error, el algoritmo ajusta los parámetros mediante retropropagación ("backpropagation"). Esto es particularmente importante en las redes neuronales, donde el gradiente del error se propaga hacia atrás a través de las capas, ajustando los pesos de cada neurona para minimizar el error en las siguientes iteraciones. - Iteración
y refinamiento
Este proceso de evaluación y ajuste de parámetros se repite para cada batch de datos, durante múltiples epochs. A medida que avanzan los epochs, el modelo debería volverse progresivamente más preciso. Sin embargo, hay que tener cuidado de no sobreajustar (overfitting) el modelo a los datos de entrenamiento, un problema que abordaremos más adelante.
Herramientas para el entrenamiento de modelos
En este curso, hemos explorado varias herramientas para entrenar modelos de aprendizaje automático. Aunque el proceso básico es el mismo, cada herramienta tiene su propia interfaz y características específicas que pueden facilitar el entrenamiento dependiendo del tipo de problema que estés abordando.
- Azure
Custom Vision
Azure Custom Vision es una herramienta especializada para la clasificación de imágenes. La interfaz es intuitiva y está diseñada para usuarios que quizás no tengan experiencia profunda en programación. Permite cargar conjuntos de imágenes etiquetadas directamente, definir proyectos de clasificación o detección de objetos, y entrenar modelos visuales. Una de las ventajas es que el proceso de entrenamiento está altamente automatizado, y puedes monitorear el progreso directamente desde la interfaz web. También puedes ajustar parámetros básicos como el número de iteraciones y obtener un análisis visual del rendimiento del modelo. - Language
Studio
Language Studio está orientado al procesamiento de lenguaje natural (PLN). Esta plataforma te permite entrenar modelos para tareas como el análisis de sentimientos, la clasificación de texto y la extracción de entidades. Similar a Custom Vision, Language Studio ofrece una interfaz sencilla y visual donde puedes cargar tus datos textuales y configurar rápidamente el entrenamiento. El proceso se centra en optimizar modelos preentrenados en lenguaje natural, ajustándolos a las necesidades específicas de tus datos. - Azure
Machine Learning
Azure Machine Learning es una plataforma mucho más general y potente, diseñada para usuarios avanzados y proyectos complejos. Aquí, puedes entrenar modelos de aprendizaje automático utilizando grandes volúmenes de datos y algoritmos personalizados. A diferencia de Custom Vision o Language Studio, Azure ML te da control total sobre los pipelines de datos, la selección de hiperparámetros, la elección de optimizadores avanzados y el uso de infraestructuras escalables como clústeres GPU. También puedes implementar técnicas de "auto-ML" que automatizan gran parte del proceso de entrenamiento, desde la selección de algoritmos hasta la optimización de hiperparámetros.
Cada herramienta tiene ventajas particulares según el tipo de tarea que estás realizando y el nivel de control que deseas tener sobre el proceso. Mientras que herramientas como Custom Vision y Language Studio son más amigables y rápidas de implementar, Azure Machine Learning te da la flexibilidad y el control necesario para proyectos más complejos.
Técnicas avanzadas en el entrenamiento del modelo
Early stopping
Uno de los problemas más comunes al entrenar modelos es el sobreajuste. Early stopping es una técnica que ayuda a mitigar este problema. Monitorea el rendimiento del modelo en un conjunto de validación y detiene el entrenamiento cuando el rendimiento en este conjunto comienza a deteriorarse. Esto garantiza que el modelo no se entrene en exceso y conserve su capacidad de generalizar a nuevos datos.
Regularización
Otra técnica clave para evitar el sobreajuste es la regularización. Existen diferentes formas de regularización:
- L1 (Lasso): Promueve modelos más simples al forzar algunos pesos a ser exactamente cero, eliminando características irrelevantes.
- L2 (Ridge): Distribuye la penalización entre todas las características, reduciendo los pesos pero sin eliminarlos completamente.
- Dropout (en redes neuronales): Durante cada iteración, un conjunto de neuronas es "apagado" aleatoriamente, lo que previene que las neuronas dependan demasiado unas de otras, fomentando una red más robusta.
Aprendizaje por transferencia
Si estás trabajando con un problema complejo y no tienes suficientes datos, puedes recurrir al aprendizaje por transferencia. Esta técnica implica utilizar un modelo preentrenado en un gran conjunto de datos y ajustarlo a tu problema específico. Esta es una técnica muy común en Custom Vision y Language Studio, donde puedes usar modelos preentrenados en tareas generales (como la clasificación de imágenes o el análisis de sentimientos) y adaptarlos a tus propios datos.
Monitorización del entrenamiento
Es esencial que monitorees el rendimiento de tu modelo durante el entrenamiento. Esto incluye:
- Curvas de aprendizaje: Monitorea las métricas de pérdida y precisión a lo largo de los epochs para asegurarte de que el modelo esté mejorando. Si las curvas muestran un estancamiento o un empeoramiento en el conjunto de validación, puede ser una señal de sobreajuste o de que el modelo necesita ajustes.
- Métricas específicas del problema: Además de las curvas de aprendizaje, evalúa el modelo con métricas relevantes, como la precisión, recall, F1-score, o AUC. Estas métricas te darán una idea de cómo está desempeñándose el modelo en la tarea específica que estás abordando.
Conclusión
En esta lección, hemos profundizado en el proceso de entrenamiento de un modelo de aprendizaje automático, abarcando desde la configuración de los datos y la optimización de parámetros hasta la aplicación de técnicas avanzadas como la regularización y el early stopping. También exploramos cómo diferentes herramientas como Azure Custom Vision, Language Studio, y Azure Machine Learning facilitan el proceso de entrenamiento, adaptándose a diferentes tipos de problemas y usuarios. Con este conocimiento, estás mejor preparado para avanzar al siguiente paso
Paso 5: Evaluación del Modelo
Una vez que has entrenado tu modelo, el siguiente paso es determinar cuán efectivo es en realizar las tareas para las cuales fue diseñado. La evaluación del modelo es crucial porque te dice si el modelo generaliza bien a datos nuevos o si necesita más ajustes. Es aquí donde se utilizan conjuntos de validación o prueba que no fueron vistos durante el entrenamiento, y se aplican métricas específicas para evaluar su rendimiento.
En esta lección, abordaremos cómo evaluar los modelos de aprendizaje automático utilizando diferentes métricas y técnicas, cómo interpretar los resultados, y cómo evitar problemas comunes como el sobreajuste. Además, veremos cómo estas evaluaciones guían el proceso de ajuste del modelo.
Objetivo
El objetivo de esta lección es que aprendas a evaluar el rendimiento de los modelos de aprendizaje automático utilizando métricas adecuadas y a interpretar los resultados de manera que puedas tomar decisiones informadas sobre cómo mejorar el modelo si es necesario.Métricas de evaluación del modelo
Dependiendo del tipo de problema que estés abordando, hay diferentes métricas de evaluación que puedes utilizar:
- Precisión (Accuracy): Es la métrica más básica y mide el porcentaje de predicciones correctas. Se utiliza principalmente en problemas de clasificación binaria o multiclase. Sin embargo, en conjuntos de datos desbalanceados, esta métrica puede ser engañosa, por lo que es importante complementarla con otras métricas.
- Matriz de confusión: Esta matriz muestra las predicciones del modelo en comparación con las etiquetas reales en términos de verdaderos positivos (TP), falsos positivos (FP), verdaderos negativos (TN) y falsos negativos (FN). Es particularmente útil para entender los errores específicos que comete el modelo.
- Precisión y recall: Estas métricas son cruciales en problemas donde hay un desbalance en las clases, como en la detección de fraudes o enfermedades raras. La precisión mide cuántos de los elementos clasificados como positivos son realmente positivos, mientras que el recall mide cuántos de los verdaderos positivos fueron correctamente identificados por el modelo.
- F1-Score: Es una métrica que combina la precisión y el recall en una sola medida. Es útil cuando tienes un conjunto de datos desbalanceado, ya que proporciona una visión más equilibrada del rendimiento del modelo.
- Área bajo la curva ROC (AUC-ROC): Esta métrica es muy utilizada en problemas de clasificación binaria. La curva ROC mide la tasa de verdaderos positivos frente a la tasa de falsos positivos, mientras que el AUC indica qué tan bien el modelo separa las clases. Un AUC cercano a 1 indica un buen rendimiento del modelo.
- Error cuadrático medio (MSE): En problemas de regresión, esta métrica mide el promedio de los cuadrados de los errores, es decir, la diferencia entre los valores predichos y los reales. El MSE penaliza más los errores grandes, por lo que es útil cuando los errores grandes son más preocupantes que los pequeños.
Evaluación con conjuntos de prueba
Una vez que has elegido las métricas adecuadas, es importante evaluar el modelo con datos que no haya visto antes. Aquí es donde entra en juego el conjunto de prueba. La idea es simular cómo el modelo se comportará con datos del mundo real, proporcionando una evaluación objetiva de su rendimiento.
Es importante no utilizar el conjunto de prueba para ajustar el modelo. Esto debe realizarse utilizando el conjunto de validación. El conjunto de prueba se reserva exclusivamente para la evaluación final del modelo.
Consideraciones importantes en la evaluación
- Problemas de sobreajuste: Si el modelo muestra un rendimiento significativamente mejor en los datos de entrenamiento que en los datos de prueba, probablemente estés ante un caso de sobreajuste. Esto indica que el modelo ha aprendido los detalles específicos del conjunto de entrenamiento, pero no ha generalizado bien a nuevos datos.
- Distribución de los datos: Asegúrate de que los conjuntos de prueba y validación sean representativos de los datos reales que el modelo encontrará en producción. Si los datos de prueba no reflejan las condiciones del mundo real, la evaluación no será precisa.
- Interpretabilidad de las métricas: No todas las métricas son útiles para todos los problemas. Por ejemplo, en problemas de clasificación desbalanceados, como detectar fraudes donde solo el 1% de las transacciones son fraudulentas, una alta precisión puede ser engañosa. En su lugar, métricas como el recall o el F1-score proporcionan una mejor visión del rendimiento real del modelo.
Conclusión
En esta lección, hemos explorado cómo evaluar los modelos de aprendizaje automático utilizando métricas adecuadas para el tipo de problema. La evaluación es esencial para asegurarte de que tu modelo no solo es preciso en los datos de entrenamiento, sino que también generaliza bien a datos nuevos. A partir de aquí, podrás utilizar esta información para ajustar y mejorar tu modelo en el siguiente paso del proceso.
Paso 6: Ajuste Iterativo del Modelo
El proceso de ajuste iterativo es esencial en el diseño de modelos de aprendizaje automático. A pesar de que un modelo pueda parecer efectivo después del entrenamiento inicial, rara vez alcanza su máximo potencial sin ajustes y refinamientos adicionales. La razón es que los modelos de aprendizaje automático, especialmente los más complejos, suelen necesitar múltiples ciclos de ajuste para mejorar su capacidad predictiva y generalización.
En esta lección, exploraremos en detalle cómo realizar ajustes iterativos en un modelo, revisando cómo evaluar los resultados después de cada iteración, ajustar los hiperparámetros y realizar mejoras en el modelo. También abordaremos cómo realizar experimentos con diferentes configuraciones y estrategias para maximizar la capacidad del modelo. El ajuste iterativo es la clave para pasar de un modelo básico a uno altamente optimizado, capaz de manejar datos del mundo real de manera precisa.
Objetivo
El objetivo de esta lección es aprender cómo realizar ajustes iterativos en un modelo de aprendizaje automático para mejorar su rendimiento. Veremos cómo diagnosticar problemas comunes como el sobreajuste y el subajuste, y cómo ajustar los hiperparámetros del modelo para maximizar su habilidad predictiva.Proceso de ajuste iterativo
El ajuste iterativo se basa en el principio de repetición continua de las siguientes etapas: entrenar, evaluar, ajustar, y volver a entrenar. El ciclo puede repetirse tantas veces como sea necesario hasta que se alcance el nivel de rendimiento deseado.
- Entrenamiento
inicial y evaluación
Después del primer entrenamiento, el modelo debe ser evaluado utilizando un conjunto de datos de prueba. La evaluación inicial proporciona una línea de base sobre cómo se desempeña el modelo con datos no vistos. Las métricas utilizadas para la evaluación inicial, como precisión, recall, F1-score, o AUC, son cruciales para guiar el ajuste posterior del modelo. - Identificación
de problemas comunes
Existen dos problemas comunes que pueden surgir tras la evaluación inicial: el sobreajuste (overfitting) y el subajuste (underfitting). - Sobreajuste: Ocurre cuando el modelo ha aprendido demasiado bien los datos de entrenamiento, capturando tanto la señal como el ruido. Esto resulta en un excelente desempeño en el conjunto de entrenamiento, pero un pobre rendimiento en datos nuevos. Un modelo sobreajustado tiende a ser demasiado complejo, ajustándose a patrones específicos del conjunto de entrenamiento que no se generalizan bien.
- Subajuste: Este problema se presenta cuando el modelo no ha aprendido suficientemente de los datos. Un modelo subajustado es demasiado simple y no captura adecuadamente los patrones subyacentes en los datos. Esto resulta en un mal desempeño tanto en los datos de entrenamiento como en los datos de prueba.
- Diagnosticar estos problemas es el primer paso hacia un ajuste efectivo.
Estrategias de ajuste iterativo
Para corregir los problemas de sobreajuste y subajuste, existen varias estrategias que se pueden implementar en el proceso iterativo:
- Ajuste
de hiperparámetros
Los hiperparámetros son parámetros del modelo que se configuran antes de iniciar el proceso de entrenamiento, como la tasa de aprendizaje, el número de neuronas en una red neuronal, o la profundidad máxima en un árbol de decisión. Ajustar estos valores es esencial para encontrar el equilibrio adecuado entre sesgo y varianza. - Disminuir la tasa de aprendizaje: Puede ser útil en casos donde el modelo está sobreajustando. Una tasa de aprendizaje más pequeña permite que el modelo realice ajustes más pequeños y controlados en los parámetros en cada iteración de entrenamiento.
- Aumentar la tasa de regularización: En modelos como las redes neuronales, puedes aplicar regularización L1 o L2 para evitar que el modelo se ajuste demasiado a los datos de entrenamiento. Esto ayuda a reducir el sobreajuste al penalizar las complejidades innecesarias del modelo.
- Cambiar el número de capas o neuronas: En redes neuronales, ajustar la arquitectura (el número de capas o neuronas) es clave. Modelos más simples con menos capas tienden a subajustar, mientras que modelos excesivamente complejos pueden sobreajustar.
- Entrenamiento
adicional con más datos
Si el modelo sufre de sobreajuste, agregar más datos de entrenamiento puede ayudar a mejorar la capacidad del modelo para generalizar. A menudo, los modelos sobreajustan cuando los datos disponibles son insuficientes o no cubren adecuadamente la diversidad del problema. - Cross-validation
(validación cruzada)
Una técnica poderosa para mitigar el sobreajuste es la validación cruzada. La validación cruzada k-fold permite que cada subconjunto de datos sea utilizado tanto para entrenamiento como para evaluación en diferentes iteraciones, minimizando la varianza y proporcionando una estimación más confiable del rendimiento del modelo en datos no vistos. Implementar este enfoque mejora la robustez del modelo. - Early
stopping (parada temprana)
Early stopping es otra técnica útil para evitar el sobreajuste. Esta técnica consiste en monitorear el rendimiento del modelo en un conjunto de validación durante el entrenamiento. Si el rendimiento en el conjunto de validación deja de mejorar, el entrenamiento se detiene antes de que el modelo comience a ajustarse demasiado a los datos de entrenamiento. - Modificación
de características (feature engineering)
A veces, el problema puede estar en las características utilizadas. Feature engineering puede incluir la creación de nuevas características, eliminar las características irrelevantes o realizar una transformación de las características existentes (como la normalización o el escalado). Mejorar la calidad de las características puede hacer que el modelo capte mejor los patrones reales en los datos.
Experimentación y comparación
El ajuste iterativo es también un proceso de experimentación. A menudo, se entrenan múltiples modelos con distintas configuraciones de hiperparámetros o diferentes arquitecturas, y luego se comparan sus rendimientos. Las herramientas como Azure Machine Learning ofrecen la capacidad de realizar múltiples experimentos en paralelo, lo que facilita la comparación y optimización de modelos.
Por ejemplo, podrías entrenar tres versiones diferentes de un modelo de clasificación utilizando distintas tasas de aprendizaje y comparar los resultados para ver cuál produce el mejor rendimiento. Este enfoque iterativo de prueba y error es fundamental para encontrar la mejor configuración posible del modelo.
Monitoreo de métricas y ajuste continuo
El monitoreo de métricas es esencial para el ajuste iterativo. Algunas métricas comunes que debes monitorear son:
- Precisión: Qué tan a menudo el modelo realiza predicciones correctas.
- Recall: Qué proporción de casos positivos son identificados correctamente por el modelo.
- F1-Score: La media armónica entre precisión y recall, que ofrece un balance entre ambos.
- AUC-ROC: La curva ROC y el área bajo la curva (AUC) son útiles para problemas de clasificación, ya que evalúan la capacidad del modelo para distinguir entre clases.
La clave es utilizar métricas que se ajusten al tipo de problema que estás resolviendo. Después de cada ciclo de ajuste y reentrenamiento, debes volver a evaluar el rendimiento del modelo en base a estas métricas, y continuar ajustando hasta lograr mejoras estables.
Herramientas para el ajuste iterativo
En este curso hemos explorado herramientas como Azure Machine Learning, Custom Vision, y Language Studio, todas las cuales facilitan el ajuste iterativo de modelos.
- Azure Machine Learning ofrece funcionalidades avanzadas para realizar experimentos en paralelo, permitiendo probar distintas configuraciones de hiperparámetros en un solo flujo de trabajo. Además, con AutoML, Azure Machine Learning puede automatizar parte del proceso iterativo al ajustar de forma automática los hiperparámetros y seleccionar el mejor modelo en base a las métricas de rendimiento.
- Custom Vision permite realizar ajustes iterativos de manera más sencilla para tareas de visión por computadora. Puedes ajustar la tasa de aprendizaje o la cantidad de iteraciones de entrenamiento de manera directa desde la interfaz, realizando evaluaciones continuas con nuevos lotes de datos.
- Language Studio también facilita ajustes iterativos en modelos de procesamiento de lenguaje natural. Permite cargar nuevos conjuntos de datos, ajustar los parámetros y evaluar las mejoras a medida que el modelo se expone a más datos y configuraciones.
Conclusión
El ajuste iterativo del modelo es uno de los aspectos más importantes del ciclo de vida de un proyecto de aprendizaje automático. Mediante un proceso continuo de entrenar, evaluar y ajustar, es posible mejorar significativamente el rendimiento del modelo. Es un proceso que requiere paciencia y atención a los detalles, ya que implica probar diferentes configuraciones, diagnosticar problemas como el sobreajuste o el subajuste, y aplicar técnicas avanzadas como la regularización, la validación cruzada y el early stopping. Las herramientas que hemos explorado a lo largo del curso, como Azure Machine Learning, Custom Vision, y Language Studio, son aliados importantes en este proceso, ofreciendo interfaces flexibles y potentes para facilitar el ajuste iterativo.
Sesgo y Varianza en Modelos de Aprendizaje Automático
Cuando construyes un modelo de aprendizaje automático, uno de los mayores desafíos es encontrar un equilibrio entre dos fuentes de error clave: sesgo y varianza. Estos conceptos están en el centro de la capacidad del modelo para generalizar correctamente a nuevos datos. Mientras que el sesgo y la varianza son conceptos estadísticos fundamentales, su impacto en el rendimiento del modelo de aprendizaje automático puede ser profundo y, por lo tanto, es esencial comprenderlos y manejarlos de manera efectiva.
En esta lección, exploraremos en detalle qué significan el sesgo y la varianza, cómo se manifiestan en el comportamiento de los modelos de aprendizaje automático, y cómo puedes optimizar un modelo para lograr el equilibrio adecuado entre ambos. Este equilibrio es crucial para evitar dos problemas comunes en el aprendizaje automático: subajuste y sobrerajuste, que pueden reducir drásticamente la efectividad de tu modelo.
Objetivo
El objetivo de esta lección es aprender a identificar y gestionar los errores asociados con el sesgo y la varianza, y lograr un equilibrio óptimo entre ambos para mejorar la capacidad del modelo de generalizar adecuadamente a nuevos datos.
¿Qué es el sesgo?
El sesgo en un modelo de aprendizaje automático se refiere a los errores introducidos por las suposiciones simplificadas del modelo al intentar representar una relación subyacente en los datos. En otras palabras, el sesgo ocurre cuando el modelo es demasiado simplista para captar los patrones presentes en los datos, lo que genera predicciones erróneas de manera sistemática.
-
Sesgo elevado: Ocurre cuando el modelo es tan simple que no puede capturar los patrones complejos en los datos, lo que lleva a un subajuste. Por ejemplo, en un problema de regresión, un modelo de regresión lineal puede tener un sesgo elevado si la relación entre las variables no es lineal. El modelo subestima la complejidad de la relación entre las variables y realiza predicciones inexactas.
¿Qué es la varianza?
La varianza mide la sensibilidad del modelo a las fluctuaciones en el conjunto de datos de entrenamiento. Un modelo con alta varianza tiende a aprender demasiado bien los detalles y el ruido de los datos de entrenamiento, lo que afecta su capacidad de generalizar a nuevos datos no vistos.
-
Varianza elevada: Ocurre cuando el modelo es demasiado complejo y ajusta en exceso los datos de entrenamiento, lo que lleva a un sobreajuste. En estos casos, el modelo aprende patrones específicos que no se repiten en otros conjuntos de datos, lo que hace que las predicciones sean erróneas en escenarios del mundo real.
Subajuste vs. Sobreajuste
-
Subajuste: Ocurre cuando el modelo es demasiado simple y tiene un sesgo elevado. El modelo no logra aprender los patrones importantes de los datos, lo que da como resultado predicciones inexactas en los datos de entrenamiento y prueba. Un ejemplo sería intentar ajustar una línea recta a datos que tienen una forma curva compleja.
-
Sobreajuste: Este problema aparece cuando el modelo tiene una varianza elevada y se ajusta demasiado a los datos de entrenamiento. El modelo no puede generalizar a nuevos datos porque ha aprendido demasiado bien los detalles específicos y el ruido del conjunto de entrenamiento. Por ejemplo, en clasificación, un modelo sobreajustado podría aprender patrones de ruido en los datos, como características irrelevantes, que no se aplican a nuevos ejemplos.
Equilibrio entre sesgo y varianza
El desafío principal al entrenar un modelo es encontrar el punto óptimo entre el sesgo y la varianza, donde el modelo sea lo suficientemente complejo como para capturar patrones importantes en los datos, pero no tan complejo como para aprender el ruido.
-
Sesgo elevado, baja varianza: El modelo subajusta, es decir, es demasiado simple para hacer predicciones precisas.
-
Bajo sesgo, alta varianza: El modelo sobreajusta y no generaliza bien a nuevos datos.
-
Equilibrio adecuado: El objetivo es encontrar el punto en el que el modelo tenga un sesgo bajo y una varianza controlada, lo que permite que generalice correctamente.
Técnicas para mitigar sesgo y varianza
Existen varias estrategias para encontrar un equilibrio adecuado:
-
Regularización: Aplicar técnicas como la regularización L1 o L2 puede ayudar a reducir el sobreajuste penalizando los coeficientes del modelo, obligándolo a simplificar.
-
Aumento de datos: Para reducir la varianza, puedes ampliar el conjunto de datos de entrenamiento. Más datos ayudan al modelo a aprender patrones más generales.
-
Validación cruzada: Esta técnica permite evaluar cómo el modelo generaliza dividiendo los datos en múltiples subconjuntos y rotando entre conjuntos de entrenamiento y prueba.
-
Early stopping (parada temprana): Para redes neuronales, la parada temprana interrumpe el entrenamiento antes de que el modelo sobreajuste los datos.
Sesgo elevado
El punto óptimo
Varianza elevada
Puede subajustar el conjunto de entrenamiento
Ajuste muy bueno
Puede sobreajustar el conjunto de entrenamiento
Más simplista
Solo lo suficientemente complejo
Más complejo
Es menos probable que sea objeto de influencia por parte de las relaciones reales entre las características y las salidas deseadas.
Hábil para encontrar relaciones verdaderas entre las características y las salidas deseadas, a la vez que no está demasiado influenciado por el ruido.
Es más probable que sea objeto de influencia por parte de las relaciones falsas entre las características y las salidas deseadas ("ruido").
Conclusión
En esta lección, has aprendido sobre la importancia de mantener un equilibrio entre el sesgo y la varianza para mejorar la capacidad del modelo de generalizar correctamente a nuevos datos. Aunque es natural que todos los modelos tengan algún grado de error debido al sesgo y la varianza, lograr un equilibrio adecuado minimiza estos errores y maximiza la utilidad del modelo. Como parte del proceso de ajuste iterativo, debes estar preparado para ajustar el sesgo y la varianza a medida que optimizas el modelo.
Generalización del Modelo
Uno de los principios fundamentales en el aprendizaje automático es la capacidad de los modelos para generalizar. Esto significa que un modelo no solo debe funcionar bien con los datos de entrenamiento, sino también ser capaz de predecir con precisión y efectividad cuando se enfrenta a nuevos datos que no ha visto antes. En este sentido, la generalización es la medida más crítica de la habilidad de un modelo de aprendizaje automático.
En esta lección, exploraremos cómo los modelos generalizan, qué factores afectan su capacidad para hacerlo bien, y cómo puedes asegurarte de que tu modelo tenga una buena generalización. Además, veremos las consecuencias del subajuste y sobreajuste en la generalización y cómo las técnicas de evaluación y validación juegan un papel crucial en este proceso.
Objetivo
El objetivo de esta lección es comprender qué significa que un modelo generalice bien y aprender técnicas para mejorar la capacidad de generalización, evitando tanto el subajuste como el sobreajuste.¿Qué es la generalización?
La generalización se refiere a la capacidad de un modelo para realizar predicciones precisas en nuevos conjuntos de datos, diferentes de los utilizados durante el entrenamiento. Si un modelo ha sido entrenado adecuadamente, debe ser capaz de identificar patrones significativos en los datos y aplicarlos correctamente a situaciones desconocidas.
Un modelo que generaliza bien tiene las siguientes características:
- Produce predicciones precisas en nuevos conjuntos de datos.
- No se ve afectado excesivamente por el ruido o las peculiaridades específicas de los datos de entrenamiento.
- Es capaz de adaptarse a diferentes escenarios con datos similares.
Factores que afectan la generalización
Existen varios factores que afectan la capacidad de un modelo para generalizar:
- Complejidad del modelo: Un modelo demasiado simple puede sufrir de subajuste y no captar los patrones relevantes. Un modelo demasiado complejo puede sufrir de sobreajuste y aprender detalles irrelevantes de los datos de entrenamiento.
- Tamaño y calidad del conjunto de datos: Un conjunto de datos pequeño o de mala calidad puede limitar la capacidad del modelo para generalizar. Un conjunto de datos más grande y variado proporciona más oportunidades para que el modelo aprenda patrones robustos.
- Ruido en los datos: Si los datos contienen mucho ruido, el modelo puede ajustarse a ese ruido en lugar de los patrones verdaderos, lo que afecta negativamente la generalización.
- Regularización: El uso de técnicas de regularización como L1 y L2 puede ayudar a mejorar la generalización al evitar que el modelo sea demasiado flexible o complejo.
Técnicas para mejorar la generalización
- Validación cruzada: Como mencionamos en lecciones anteriores, la validación cruzada divide los datos en múltiples subconjuntos para asegurarse de que el modelo se pruebe exhaustivamente en datos no vistos. Esto ayuda a estimar el rendimiento del modelo en situaciones del mundo real.
- Early stopping: Detener el entrenamiento cuando el rendimiento en un conjunto de validación deja de mejorar es una técnica útil para prevenir el sobreajuste y mejorar la generalización.
- Regularización: Aplicar regularización penaliza la complejidad excesiva del modelo, evitando que se ajuste demasiado a los datos de entrenamiento.
- Aumento de datos: La técnica de aumento de datos, común en la visión por computadora, implica generar nuevas muestras a partir de las existentes mediante transformaciones como rotaciones, escalado o cambios de iluminación. Esto ayuda a que el modelo aprenda de datos más variados y generalice mejor.
Consecuencias del subajuste y sobreajuste en la generalización
El subajuste y el sobreajuste tienen efectos directos en la capacidad del modelo para generalizar.
- Subajuste: Cuando un modelo está subajustado, no ha captado adecuadamente los patrones en los datos de entrenamiento y, por lo tanto, no puede realizar predicciones precisas en nuevos datos. Generalmente, esto se debe a que el modelo es demasiado simple o a que los datos no contienen suficientes características relevantes.
- Sobreajuste: Un modelo sobreajustado ha aprendido en exceso los detalles y peculiaridades de los datos de entrenamiento, incluidas las anomalías y el ruido. Como resultado, el modelo tiene dificultades para generalizar porque espera encontrar los mismos patrones irrelevantes en los nuevos datos.
Conclusión
En esta lección, has aprendido que la generalización es el objetivo final de cualquier modelo de aprendizaje automático. Un modelo que generaliza bien puede realizar predicciones precisas en datos no vistos, lo que lo convierte en una herramienta útil en aplicaciones del mundo real. Al evitar el subajuste y el sobreajuste, y mediante el uso de técnicas como la validación cruzada, regularización y aumento de datos, puedes mejorar significativamente la capacidad de generalización de tus modelos.
Método de Retención y Validación Cruzada
En el proceso de desarrollo de modelos de aprendizaje automático, es fundamental evaluar su rendimiento utilizando datos no vistos antes de implementarlos en aplicaciones reales. Una forma eficaz de hacerlo es mediante el uso del método de retención y la validación cruzada, que permiten medir la capacidad del modelo para generalizar a nuevos datos. Estas técnicas ayudan a detectar problemas como el sobreajuste y proporcionan una visión más realista del rendimiento del modelo.
En esta lección, aprenderemos a aplicar el método de retención y la validación cruzada para evaluar modelos de aprendizaje automático de manera efectiva. Exploraremos sus ventajas, cómo implementarlos y cuándo utilizarlos según las características de tus datos y modelo.
Objetivo
El objetivo de esta lección es que comprendas cómo dividir los datos en diferentes subconjuntos utilizando el método de retención y cómo aplicar la validación cruzada para mejorar la evaluación de los modelos. Estos métodos permitirán una evaluación más sólida y ayudarán a mejorar la capacidad de generalización del modelo.Método de retención
El método de retención es una técnica fundamental en el aprendizaje automático para evaluar el rendimiento de un modelo. Este método consiste en dividir el conjunto de datos en varios subconjuntos, cada uno con una función específica en el proceso de entrenamiento y evaluación.
Los subconjuntos del método de retención
Conjunto de entrenamiento: Este conjunto de datos se utiliza para entrenar el modelo. Es decir, el modelo aprende de los patrones presentes en estos datos y ajusta sus parámetros para minimizar el error en las predicciones. Es crucial que el conjunto de entrenamiento represente bien el problema que el modelo intentará resolver en el mundo real.
Conjunto de validación (opcional): Este conjunto se utiliza para ajustar hiperparámetros y tomar decisiones durante el proceso de desarrollo del modelo. A diferencia del conjunto de entrenamiento, el modelo no aprende de estos datos, sino que los utiliza para verificar qué tan bien generaliza. Si se ajusta correctamente, puede ayudar a mejorar el rendimiento del modelo.
Conjunto de prueba: Una vez que el modelo ha sido entrenado y optimizado utilizando los conjuntos de entrenamiento y validación, se evalúa su rendimiento final en el conjunto de prueba. Este conjunto no debe influir en la construcción del modelo y se utiliza únicamente para evaluar su capacidad de generalización.
Ejemplo de división de datos
En la práctica, es común dividir los datos de la siguiente manera:
70-80 % para el conjunto de entrenamiento.
10-20 % para el conjunto de validación (si se utiliza).
10-20 % para el conjunto de prueba.
Por ejemplo, si tienes un conjunto de datos de 1,000 ejemplos, podrías asignar 700 ejemplos para el entrenamiento, 150 para la validación y 150 para la prueba. La proporción puede variar dependiendo del tamaño total del conjunto de datos y la complejidad del modelo.
Validación cruzada
La validación cruzada es una técnica más avanzada que permite evaluar el rendimiento del modelo de manera más robusta que el método de retención. En lugar de utilizar solo un conjunto de prueba, la validación cruzada divide los datos en múltiples subconjuntos, o folds, y entrena y evalúa el modelo varias veces utilizando diferentes combinaciones de datos.
Validación cruzada de k-fold
Una de las técnicas más comunes de validación cruzada es la validación cruzada de k-fold. En este enfoque, los datos se dividen en k subconjuntos (o folds). Se entrena el modelo k veces, usando k-1 subconjuntos para el entrenamiento y uno diferente para la prueba en cada iteración. Al final, se calcula el rendimiento promedio en las k iteraciones para obtener una estimación precisa del rendimiento del modelo.
Por ejemplo, si utilizas una validación cruzada de 5-fold, el conjunto de datos se dividirá en cinco partes. El modelo se entrenará cinco veces, cada vez utilizando cuatro partes para el entrenamiento y una para la prueba. El rendimiento final será el promedio de los cinco resultados obtenidos.
Validación cruzada estratificada
En problemas de clasificación con clases desequilibradas, la validación cruzada estratificada es preferible. Esta técnica asegura que cada fold tenga aproximadamente la misma proporción de ejemplos de cada clase, lo que mejora la representatividad y precisión del modelo.
Ventajas y desventajas de la validación cruzada
Ventajas:
- Proporciona una evaluación más robusta y confiable del rendimiento del modelo al probarlo en múltiples subconjuntos de datos.
- Minimiza la varianza y ofrece una mejor estimación de cómo funcionará el modelo en datos no vistos.
Desventajas:
- Requiere más tiempo de cómputo y recursos, ya que el modelo se entrena y evalúa varias veces.
- En modelos complejos y grandes conjuntos de datos, puede ser computacionalmente costoso.
Conclusión
En esta lección, has aprendido sobre dos técnicas esenciales para evaluar el rendimiento de un modelo: el método de retención y la validación cruzada. Mientras que el método de retención es una forma básica y directa de dividir los datos, la validación cruzada proporciona una evaluación más exhaustiva y ayuda a reducir el riesgo de sobreajuste. Saber cuándo y cómo aplicar cada técnica es clave para garantizar que tu modelo de aprendizaje automático pueda generalizar con éxito a nuevos datos y ofrecer resultados confiables en aplicaciones del mundo real.
Ajuste de Hiperparámetros en Modelos de Aprendizaje Automático
Los hiperparámetros son uno de los componentes más críticos y desafiantes en el diseño de un modelo de aprendizaje automático. A diferencia de los parámetros del modelo, que se ajustan automáticamente durante el entrenamiento, los hiperparámetros son valores que deben ser configurados antes de entrenar el modelo y afectan directamente su rendimiento. Encontrar los hiperparámetros óptimos puede marcar la diferencia entre un modelo con un rendimiento deficiente y uno que generaliza con precisión en nuevos datos.
En esta lección, aprenderemos qué son los hiperparámetros, cómo influyen en el comportamiento del modelo, y las principales técnicas utilizadas para su ajuste, como la búsqueda en cuadrícula (Grid Search) y la búsqueda aleatoria (Random Search). Además, haremos referencia a herramientas como Azure Machine Learning, que facilitan la automatización y optimización del ajuste de hiperparámetros de manera eficiente y escalable.
Objetivo
El objetivo de esta lección es comprender el papel de los hiperparámetros en los modelos de aprendizaje automático y aprender técnicas de ajuste para optimizar el rendimiento del modelo utilizando herramientas automatizadas y eficientes como Azure Machine Learning.Diferencia entre parámetros y hiperparámetros
Antes de profundizar en los métodos de ajuste, es importante aclarar la diferencia entre parámetros y hiperparámetros:
- Parámetros del modelo: Son los valores internos que el modelo aprende durante el proceso de entrenamiento. Por ejemplo, en una regresión lineal, los coeficientes que multiplican las variables independientes son parámetros. Estos se ajustan automáticamente para minimizar la función de pérdida durante el entrenamiento.
- Hiperparámetros: Son los valores que configuran el comportamiento del algoritmo de aprendizaje, pero no se ajustan durante el entrenamiento. Ejemplos incluyen la tasa de aprendizaje en redes neuronales, el número de árboles en un modelo de bosques aleatorios, o el número de vecinos en un clasificador k-Nearest Neighbors (k-NN). Los hiperparámetros deben configurarse manualmente antes de entrenar el modelo.
Métodos de ajuste de hiperparámetros
Búsqueda en cuadrícula (Grid Search)
Grid Search es una técnica exhaustiva para ajustar hiperparámetros. Se define un conjunto discreto de valores posibles para cada hiperparámetro y se evalúan todas las combinaciones posibles. Cada combinación se prueba mediante un proceso de validación cruzada, y el modelo con los hiperparámetros que mejor rendimiento tenga en promedio es seleccionado como el mejor modelo.
Ventajas:
- Asegura que se exploren todas las combinaciones de hiperparámetros.
- Útil cuando el número de combinaciones posibles es bajo y cuando tienes tiempo de cómputo disponible.
Desventajas:
- Es computacionalmente costoso, ya que debe evaluar cada combinación.
- Se vuelve poco práctico cuando el número de hiperparámetros y sus posibles valores es grande.
Búsqueda aleatoria (Random Search)
Random Search selecciona combinaciones de hiperparámetros al azar dentro de un rango definido para cada hiperparámetro. En lugar de probar todas las combinaciones posibles, se prueban un número determinado de combinaciones aleatorias, lo que permite encontrar hiperparámetros óptimos de manera más eficiente.
Ventajas:
- Más eficiente que Grid Search en espacios de hiperparámetros grandes.
- Tiende a encontrar buenas combinaciones de hiperparámetros sin necesidad de probar todas las posibilidades.
Desventajas:
- No garantiza que se encuentre la mejor combinación absoluta de hiperparámetros.
- Puede requerir más iteraciones que Grid Search para llegar a un resultado óptimo, dependiendo de la aleatoriedad.
Optimizadores bayesianos
Una alternativa más avanzada a las búsquedas en cuadrícula y aleatorias es la optimización bayesiana. Este enfoque construye un modelo probabilístico de la función objetivo y utiliza ese modelo para seleccionar de manera inteligente los hiperparámetros que probablemente mejoren el rendimiento del modelo, en lugar de probar combinaciones aleatorias o exhaustivas.
Ventajas:
- Más eficiente que las técnicas anteriores, especialmente en espacios de hiperparámetros grandes y complejos.
- Mejora el rendimiento al buscar activamente combinaciones más prometedoras de hiperparámetros.
Desventajas:
- Requiere una mayor complejidad en la implementación.
- Es computacionalmente costoso en problemas muy grandes.
Uso de herramientas automatizadas: Azure Machine Learning
En proyectos de aprendizaje automático que requieren un ajuste extensivo de hiperparámetros, herramientas como Azure Machine Learning proporcionan una plataforma eficiente y escalable para realizar este proceso de manera automatizada. Azure Machine Learning incluye capacidades avanzadas de HyperDrive, que permite realizar búsquedas de hiperparámetros mediante Grid Search, Random Search y optimización bayesiana de manera distribuida.
Ventajas de Azure Machine Learning:
- Escalabilidad: Azure Machine Learning puede distribuir las pruebas de hiperparámetros en múltiples máquinas virtuales, lo que acelera significativamente el proceso, sobre todo cuando se trabaja con grandes volúmenes de datos o modelos complejos.
- Automatización: Con HyperDrive, puedes definir un rango de valores para cada hiperparámetro, y la herramienta se encarga de gestionar automáticamente el ajuste de hiperparámetros, seleccionando las combinaciones más prometedoras.
- Experimentación y registro: Azure Machine Learning registra y compara automáticamente los resultados de cada combinación de hiperparámetros, lo que facilita la selección del modelo final basado en criterios como la precisión, la pérdida o cualquier métrica de evaluación que definas.
- Compatibilidad: Puedes utilizar Azure Machine Learning con modelos desarrollados en scikit-learn, TensorFlow, PyTorch, entre otros, lo que proporciona flexibilidad para integrar diferentes frameworks de aprendizaje automático.
Técnicas adicionales de ajuste de hiperparámetros
Además de las técnicas anteriores, existen otras estrategias para ajustar los hiperparámetros:
- Análisis manual: Los profesionales pueden ajustar los hiperparámetros mediante prueba y error basándose en su conocimiento previo del problema.
- Algoritmos genéticos: Utilizan conceptos de evolución natural, como la selección, cruza y mutación, para ajustar los hiperparámetros de forma automática.
- Simulated Annealing: Técnica de optimización que utiliza el concepto de enfriamiento en física para buscar la mejor combinación de hiperparámetros.
Conclusión
En esta lección, has aprendido sobre la importancia de los hiperparámetros en el rendimiento de los modelos de aprendizaje automático y sobre varias técnicas utilizadas para ajustarlos, incluyendo Grid Search, Random Search y la optimización bayesiana. Además, exploramos el uso de herramientas avanzadas como Azure Machine Learning, que pueden automatizar y escalar el proceso de ajuste de hiperparámetros, haciendo que el desarrollo de modelos sea más eficiente y accesible. Ajustar los hiperparámetros es un paso crucial para mejorar la capacidad de generalización de un modelo y garantizar su éxito en tareas del mundo real.
Paso 7: Implementación del Modelo y Mantenimiento
El proceso de aprendizaje automático no finaliza una vez que hemos entrenado, evaluado y ajustado nuestro modelo. De hecho, una de las partes más críticas del ciclo de vida del aprendizaje automático es la implementación y el mantenimiento del modelo en un entorno de producción. Aquí es donde los modelos se utilizan para hacer predicciones en tiempo real o para automatizar decisiones. Sin embargo, implementar un modelo con éxito no es suficiente; también es necesario garantizar que el modelo se mantenga actualizado y eficiente en el tiempo a medida que el entorno y los datos evolucionan.
En esta lección, abordaremos el proceso de implementación, desde la elección de la infraestructura adecuada hasta las estrategias de monitoreo y mantenimiento de modelos, garantizando que mantengan su capacidad predictiva a lo largo del tiempo. Exploraremos también las herramientas que pueden facilitar la implementación, como Azure Machine Learning, que permite desplegar modelos en la nube y gestionar su ciclo de vida.
Objetivo
El objetivo de esta lección es comprender cómo implementar un modelo de aprendizaje automático en producción, explorar las herramientas disponibles para facilitar esta tarea y aprender sobre las mejores prácticas para mantener el rendimiento del modelo con el paso del tiempo.Proceso de implementación del modelo
La implementación de un modelo de aprendizaje automático es el proceso de trasladar el modelo entrenado a un entorno de producción donde pueda hacer predicciones en datos en tiempo real o ser parte de un flujo de trabajo automatizado. Existen varias formas de implementar un modelo, dependiendo de la arquitectura de la solución y del entorno en el que se trabajará.
Elección de la infraestructura
Para implementar un modelo, primero debes decidir en qué infraestructura o plataforma se ejecutará. Las opciones incluyen:
Localmente: Los modelos pueden ejecutarse en servidores locales o en dispositivos específicos, lo que puede ser adecuado para aplicaciones empresariales internas o casos donde los datos no pueden salir del entorno local por razones de seguridad.
Nube: Implementar un modelo en la nube, utilizando plataformas como Azure, AWS, o Google Cloud, es común debido a la escalabilidad, flexibilidad y facilidad de acceso desde cualquier parte del mundo. Las infraestructuras en la nube permiten desplegar modelos como servicios web que pueden ser accedidos por otras aplicaciones a través de APIs.
Uso de herramientas para la implementación
El uso de herramientas especializadas puede simplificar significativamente el proceso de implementación y mantenimiento de modelos. En este curso, hemos trabajado con Azure Machine Learning, una plataforma que no solo facilita el entrenamiento y ajuste de modelos, sino que también permite desplegarlos en producción de manera sencilla.
Azure Machine Learning:
Despliegue de modelos: Permite implementar modelos como servicios web, contenedores Docker o integrados en pipelines de datos en tiempo real.
Mantenimiento: Azure Machine Learning facilita la actualización continua del modelo mediante pipelines automatizados, permitiendo un redeployment fácil cuando se reentrena el modelo con nuevos datos.
Azure Custom Vision y Language Studio:
Estas herramientas permiten desplegar modelos personalizados, como clasificaciones de imágenes o modelos de procesamiento de lenguaje natural, directamente desde la plataforma. Una vez entrenado el modelo en estas interfaces, puedes publicarlo como un servicio API accesible desde cualquier aplicación externa.
Mantenimiento del modelo
Una vez implementado, el modelo no puede quedarse estático. Con el tiempo, los datos y las condiciones pueden cambiar, lo que puede degradar el rendimiento del modelo. Este fenómeno se conoce como deriva del modelo. Es crucial realizar el mantenimiento para asegurar que el modelo siga siendo preciso y eficiente.
Monitoreo continuo
El primer paso en el mantenimiento es implementar un sistema de monitoreo que permita detectar cambios en la precisión del modelo y su comportamiento en el entorno de producción. Los aspectos clave a monitorear incluyen:
Desempeño del modelo: Monitorizar métricas como la precisión, sensibilidad, especificidad, etc., en tiempo real para asegurarse de que el modelo esté funcionando de acuerdo con las expectativas.
Deriva de datos: El cambio en la distribución de los datos de entrada puede afectar la efectividad del modelo. Es fundamental rastrear si los datos de entrada comienzan a diferir significativamente de los datos con los que el modelo fue entrenado.
Azure Machine Learning incluye herramientas para la monitorización automatizada de modelos. Estos servicios pueden alertar cuando se detectan desviaciones significativas en el desempeño del modelo, lo que puede desencadenar un proceso de revisión y reentrenamiento.
Retraining y redeployment
Cuando el rendimiento de un modelo disminuye o se detecta una deriva en los datos, es probable que necesites reentrenar el modelo utilizando datos más actualizados. Las plataformas modernas como Azure Machine Learning facilitan este proceso a través de pipelines automatizados de machine learning. Estos pipelines permiten integrar nuevos datos, entrenar el modelo nuevamente y desplegarlo de manera automática, sin necesidad de intervención manual continua.
Un ciclo típico de mantenimiento de un modelo incluiría los siguientes pasos:
- Monitoreo continuo de los datos y del rendimiento del modelo.
- Detección de problemas, como una caída en la precisión o la aparición de datos atípicos.
- Reentrenamiento del modelo utilizando datos más recientes o actualizados.
- Validación del nuevo modelo para asegurarse de que se han resuelto los problemas detectados.
- Redeployment del modelo actualizado en producción.
Consideraciones sobre escalabilidad
Al implementar un modelo en un entorno de producción, debes asegurarte de que la infraestructura pueda escalar adecuadamente para manejar aumentos en el volumen de datos o peticiones. Por ejemplo, si tu modelo se usa en una aplicación de gran alcance, como un motor de recomendación o un sistema de detección de fraude, necesitarás asegurarte de que pueda escalar horizontalmente y procesar miles o millones de predicciones simultáneamente.
Azure Machine Learning y otras plataformas en la nube permiten escalar automáticamente los servicios según la demanda, asegurando que los tiempos de respuesta y el rendimiento no se vean afectados, independientemente del volumen de datos.
Conclusión
En esta lección, hemos explorado la fase final y crucial del ciclo de vida del aprendizaje automático: la implementación y mantenimiento del modelo. Implementar un modelo en producción no es el fin del proceso; es solo el comienzo de una fase de mantenimiento continuo en la que debes asegurarte de que el modelo siga siendo eficiente y relevante a lo largo del tiempo. Hemos aprendido sobre las estrategias y herramientas, como Azure Machine Learning, que permiten la implementación eficiente y el mantenimiento automatizado de modelos, desde la monitorización hasta el redeployment. El objetivo es que tus modelos sigan siendo útiles y efectivos en entornos reales y cambiantes.
-
Modelos de DALL-E
Descripción de DALL-E
DALL-E es un modelo de inteligencia artificial desarrollado por OpenAI, diseñado para generar imágenes a partir de descripciones textuales. Este modelo se basa en una versión modificada de GPT-3 y utiliza un enfoque de aprendizaje profundo para interpretar el lenguaje natural y convertirlo en representaciones visuales. La capacidad de DALL-E para crear imágenes coherentes y detalladas a partir de textos permite una amplia gama de aplicaciones en diferentes campos.
Aplicaciones y Ejemplos de Uso en Creatividad y Diseño
1. Diseño Gráfico y Publicidad: DALL-E puede generar imágenes personalizadas para campañas publicitarias, permitiendo a los diseñadores crear contenido visual único basado en descripciones específicas.
2. Prototipos de Producto: Los diseñadores de productos pueden utilizar DALL-E para visualizar conceptos e ideas rápidamente sin necesidad de habilidades avanzadas de dibujo o software de diseño.
3. Ilustración y Arte Digital: Artistas y creadores pueden aprovechar DALL-E para producir ilustraciones y obras de arte basadas en descripciones detalladas, explorando nuevas formas de creatividad.
4. Educación y Materiales Didácticos: Los educadores pueden generar imágenes que acompañen explicaciones textuales, mejorando la comprensión y el interés de los estudiantes en diversos temas.
5. Generación de Contenido para Redes Sociales: Los gestores de contenido pueden crear imágenes llamativas y relevantes para publicaciones en redes sociales basadas en tendencias o temas específicos.Ejemplos Concretos
- Creación de Mascotas Virtuales: DALL-E puede generar imágenes de mascotas imaginarias basadas en descripciones como "un gato con alas de mariposa y pelaje arcoíris".
- Visualización de Conceptos Abstractos: Puede ilustrar ideas abstractas, como "una ciudad futurista flotante sobre nubes".
En resumen, DALL-E representa un avance significativo en la intersección de la inteligencia artificial y las artes visuales, ofreciendo nuevas herramientas para la creatividad y la innovación en múltiples disciplinas.
Enlace Adicional
Para más información, visita la documentación de OpenAI sobre modelos.
-
Modelos de CLIP (Contrastive Language–Image Pre-training)
Explicación de CLIP
CLIP, desarrollado por OpenAI, es un modelo de aprendizaje profundo que integra el entendimiento de texto e imágenes. Utiliza una técnica de pre-entrenamiento contrastivo que permite al modelo aprender a asociar descripciones textuales con imágenes correspondientes. CLIP entrena simultáneamente en grandes conjuntos de datos de texto e imágenes, logrando una comprensión semántica profunda y bidireccional entre estos dos tipos de datos.
Capacidades de CLIP
Comprensión y Relación de Texto e Imágenes:
- CLIP puede identificar la relación entre texto e imágenes, comprendiendo el contexto y contenido de ambas formas de datos.
- Su capacidad para entender descripciones textuales y emparejarlas con imágenes relevantes lo hace extremadamente versátil para diversas aplicaciones.
Clasificación de Imágenes:
- CLIP se puede utilizar para tareas de clasificación de imágenes sin necesidad de un ajuste fino específico para cada tarea.
- El modelo puede clasificar imágenes basándose en descripciones textuales generales, lo que permite una gran flexibilidad y adaptabilidad en diferentes contextos.
Generación de Contenido Multimedia:
- Además de la clasificación de imágenes, CLIP puede asistir en la generación de contenido multimedia.
- Esto incluye la creación de imágenes a partir de descripciones textuales, facilitando aplicaciones en diseño gráfico, publicidad, y generación de arte digital.
Usos de CLIP en Clasificación de Imágenes y Generación de Contenido Multimedia
Clasificación de Imágenes
- CLIP puede clasificar imágenes basándose en una amplia variedad de descripciones textuales sin necesidad de entrenar modelos específicos para cada categoría.
- Esto lo hace ideal para aplicaciones que requieren una clasificación flexible y adaptable, como sistemas de búsqueda visual y catálogos de imágenes.
Generación de Contenido Multimedia
- La capacidad de CLIP para asociar texto con imágenes permite la generación automática de contenido visual basado en descripciones textuales.
- Esto es útil en la creación de contenido personalizado, donde el texto proporcionado por un usuario puede generar imágenes coherentes y relevantes.
En resumen, CLIP representa un avance significativo en la integración de la comprensión de texto e imágenes, ofreciendo aplicaciones prácticas tanto en la clasificación de imágenes como en la generación de contenido multimedia.
-
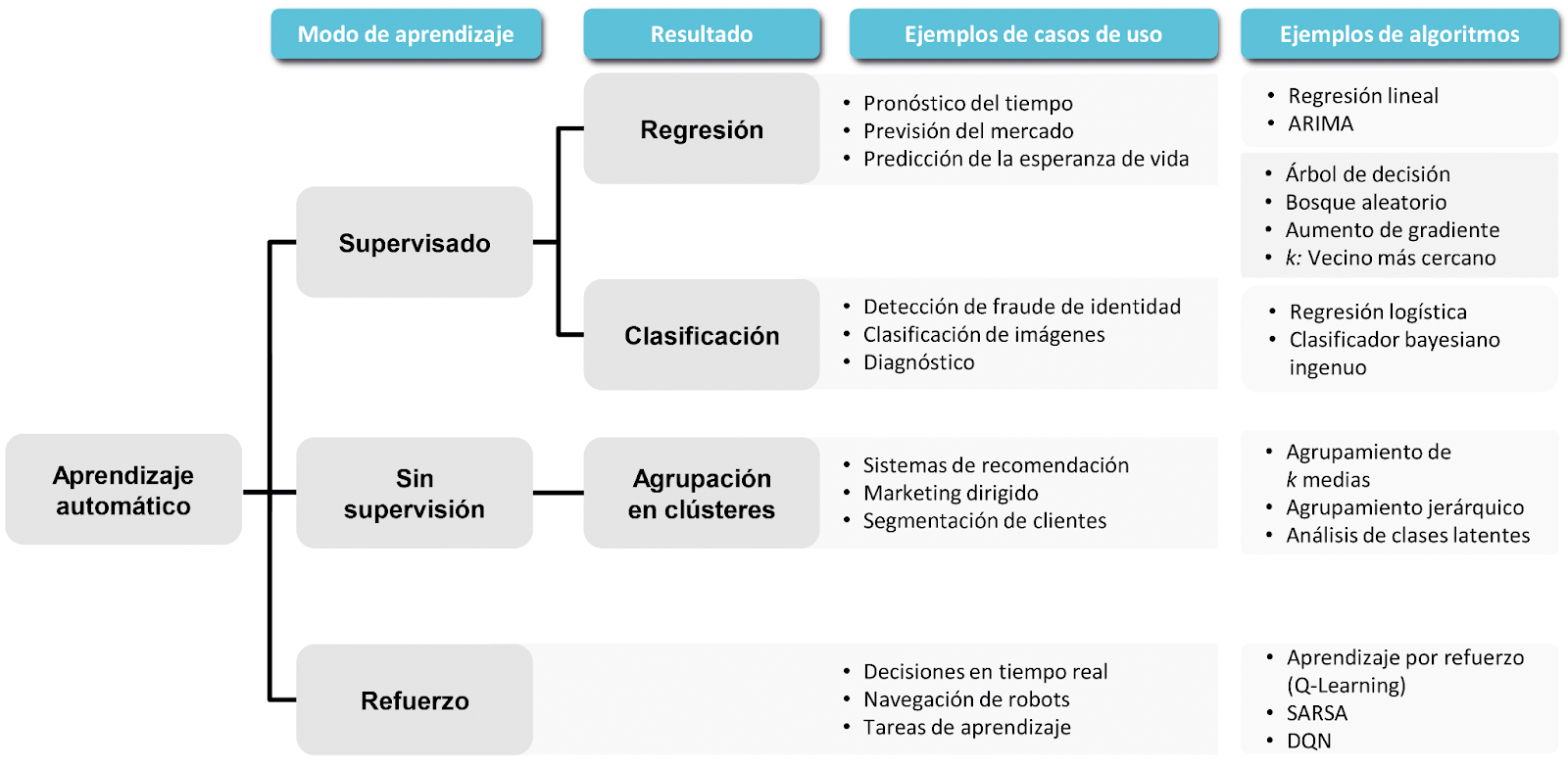
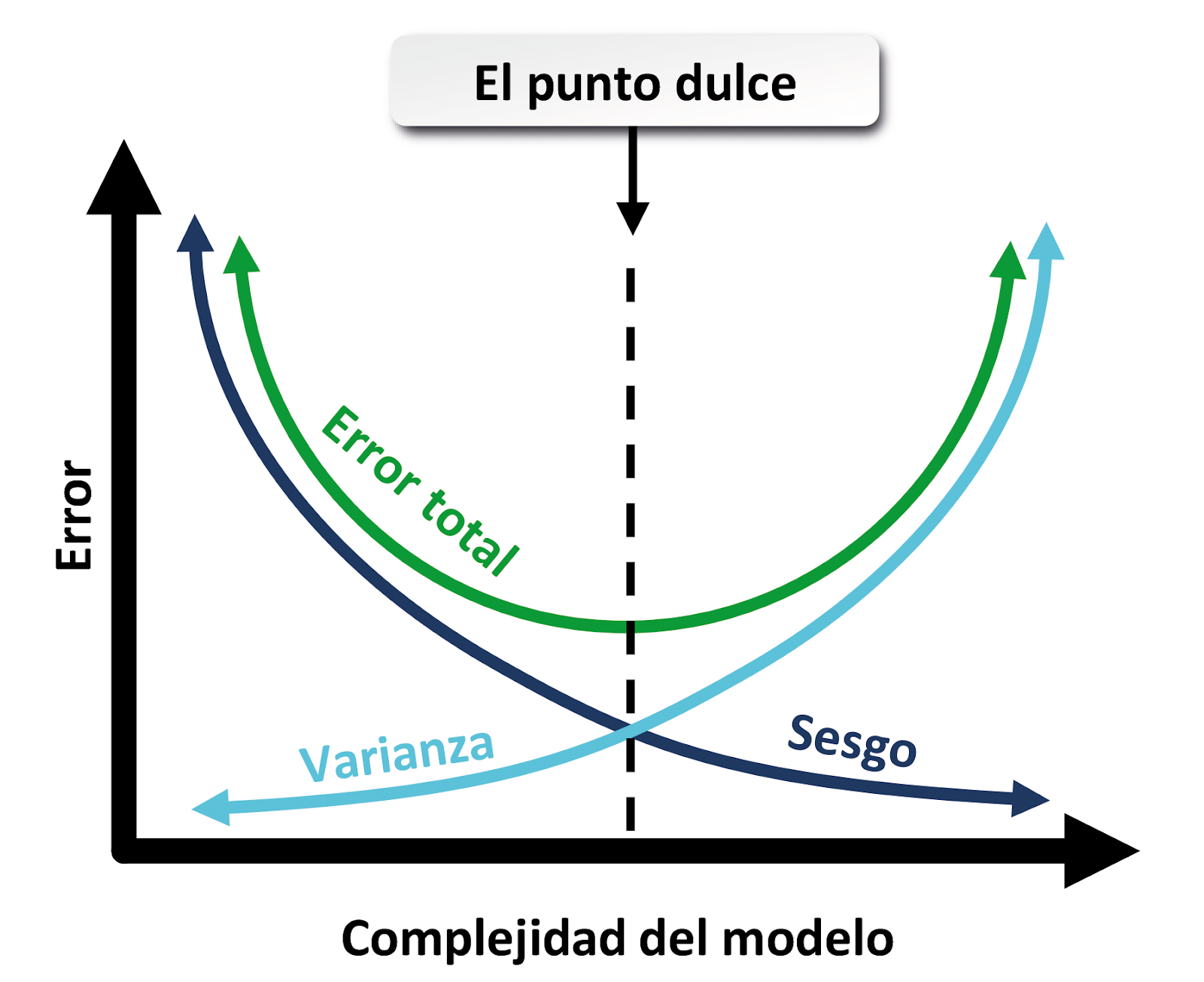
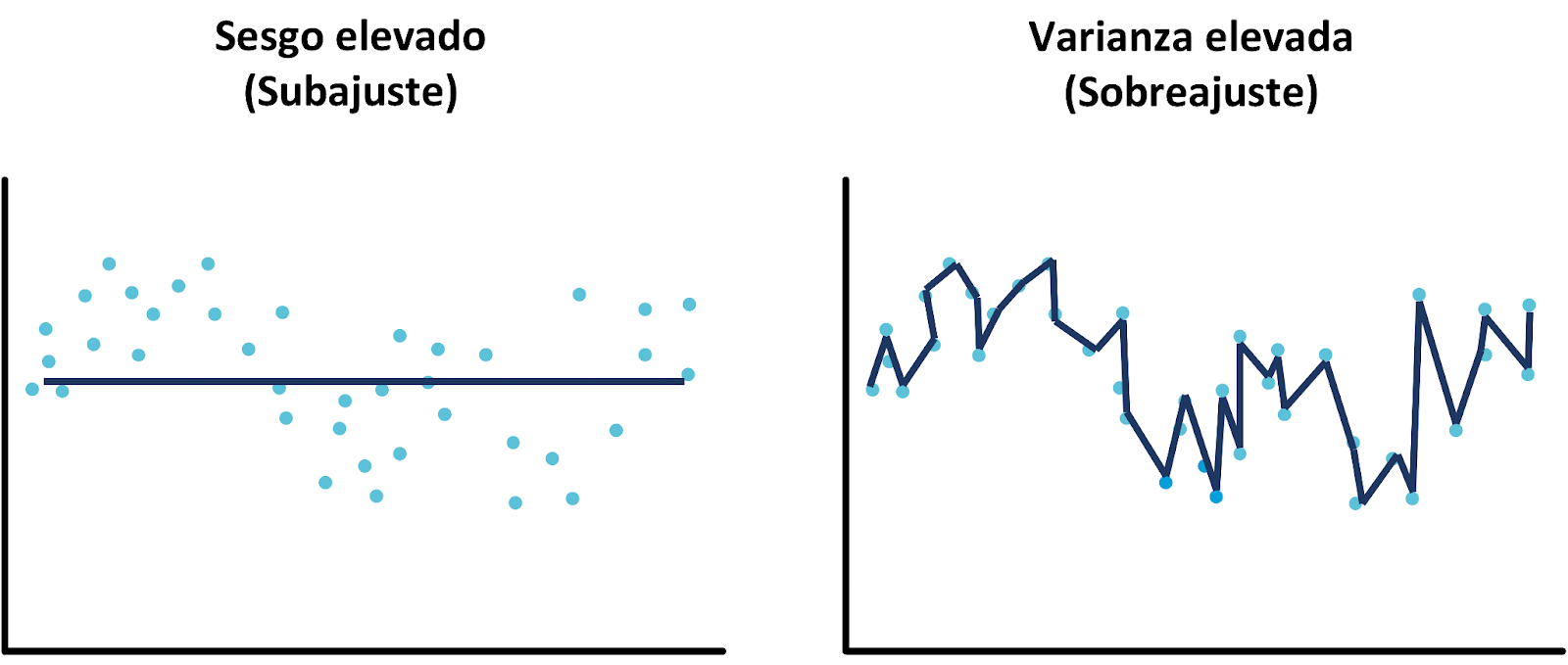
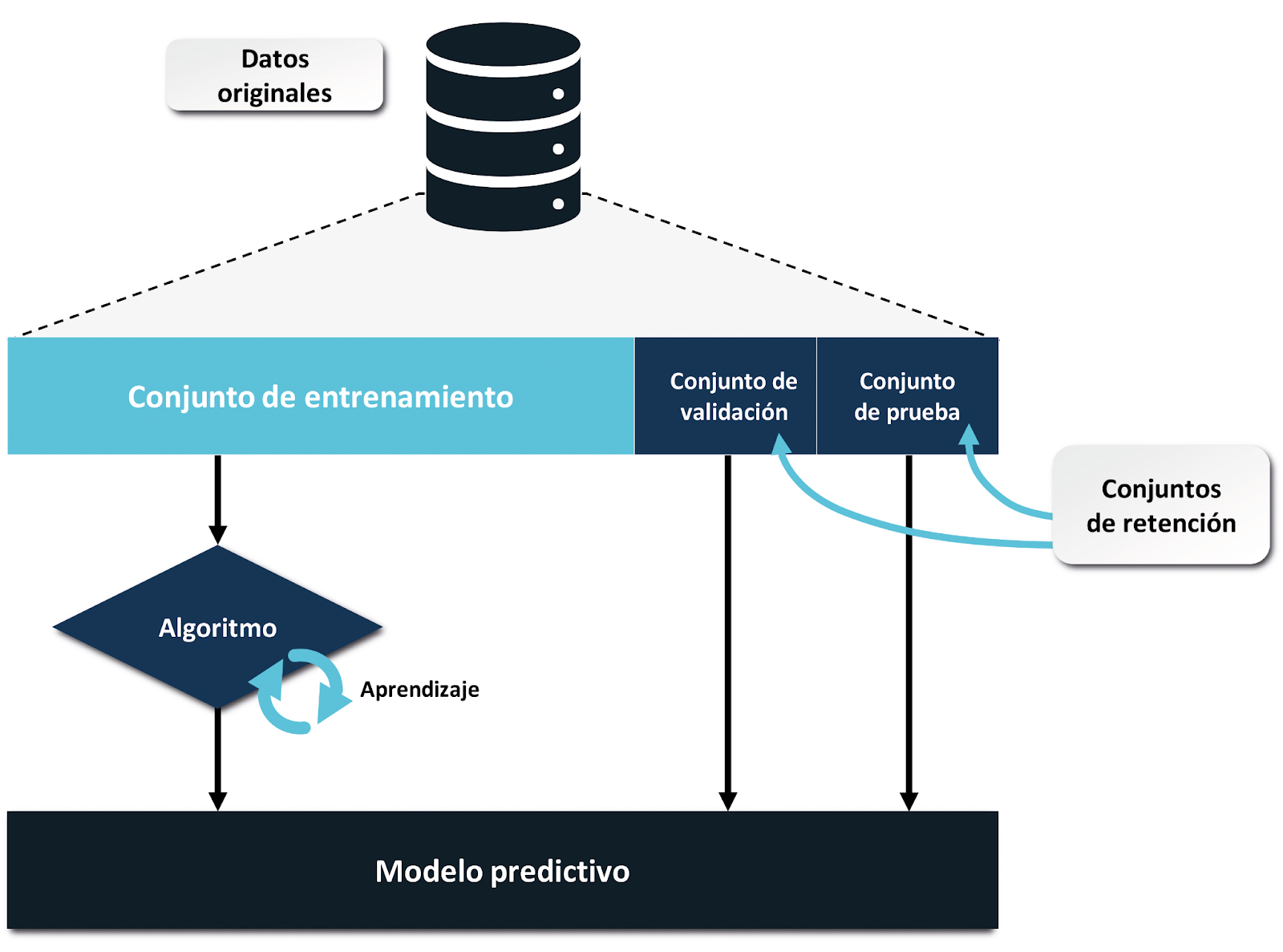
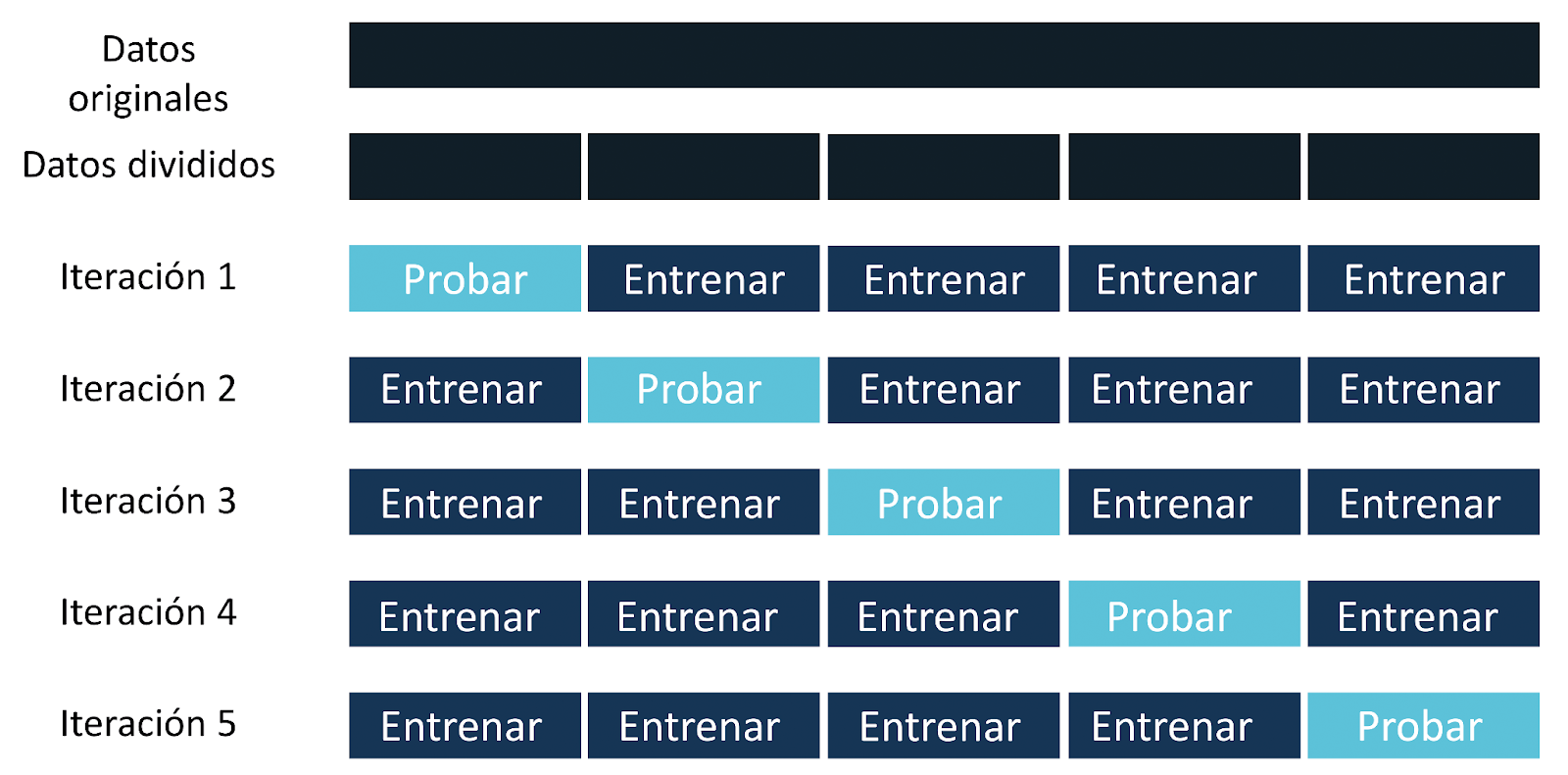
 Campus
Campus
