 Campus
Campus
Diagrama de temas
-
Implementación de LoRA (Low-Rank Adaptation of Large Language Models)
Algoritmo detallado de LoRA
LoRA (Low-Rank Adaptation) es una técnica diseñada para adaptar grandes modelos de lenguaje mediante la inyección de capas de baja dimensionalidad en el modelo original. Esto permite actualizar un número reducido de parámetros en lugar de ajustar todos los parámetros del modelo grande, reduciendo así la complejidad y el costo de computación.
El algoritmo de LoRA se centra en la adaptación de capas específicas del modelo, generalmente las capas de atención, añadiendo matrices de baja dimensionalidad que capturan la información necesaria para la tarea específica.
Pseudocódigo y explicaciones paso a paso
Inicialización:
- Definir las dimensiones de la matriz original del modelo y las dimensiones de baja dimensionalidad para las nuevas matrices y .
- Crear matrices y con dimensiones adecuadas: de tamaño y de tamaño .
Entrenamiento:
- Congelar los parámetros del modelo original .
- Inicializar y con valores aleatorios.
- Durante el entrenamiento, actualizar solo los parámetros de y .
Forward Pass:
- Calcular la salida original del modelo .
- Calcular la salida adaptada con y como .
- Combinar las dos salidas: , donde es un factor de escalado.
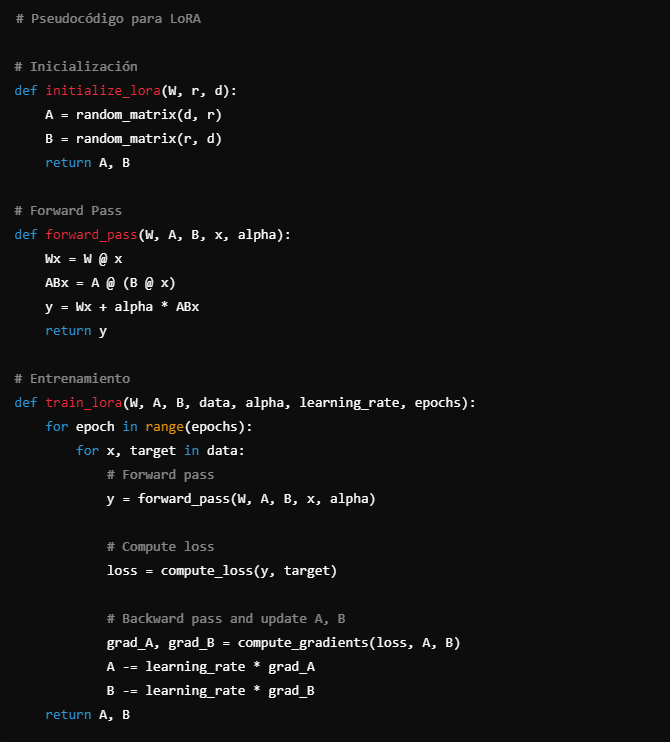
Pseudocódigo
python# Pseudocódigo para LoRA
# Inicialización
def initialize_lora(W, r, d):
A = random_matrix(d, r)
B = random_matrix(r, d)
return A, B
# Forward Pass
def forward_pass(W, A, B, x, alpha):
Wx = W @ x
ABx = A @ (B @ x)
y = Wx + alpha * ABx
return y
# Entrenamiento
def train_lora(W, A, B, data, alpha, learning_rate, epochs):
for epoch in range(epochs):
for x, target in data:
# Forward pass
y = forward_pass(W, A, B, x, alpha)
# Compute loss
loss = compute_loss(y, target)
# Backward pass and update A, B
grad_A, grad_B = compute_gradients(loss, A, B)
A -= learning_rate * grad_A
B -= learning_rate * grad_B
return A, B
Visualización DE código Python en IDE VISUAL STUDIO CODE
Explicaciones paso a paso
1. Inicialización:

2. Forward Pass:

3. Entrenamiento:

 Campus
Campus
