 Campus
Campus
Diagrama de temas
-
-
Introducción a Low-Rank Adaptation (LoRAs)
Contexto y motivación
En los últimos años, los modelos de aprendizaje profundo han logrado avances significativos en diversas tareas de inteligencia artificial, desde la visión por computadora hasta el procesamiento del lenguaje natural. Estos modelos suelen ser extremadamente grandes, con millones o incluso miles de millones de parámetros. Entrenar estos modelos desde cero es computacionalmente costoso y requiere grandes cantidades de datos y recursos.
Low-Rank Adaptation (LoRA) es una técnica que se introduce para abordar este problema. La motivación principal detrás de LoRA es reducir la complejidad computacional y los requisitos de almacenamiento de los modelos de aprendizaje profundo al adaptarlos a nuevas tareas específicas. LoRA permite que un modelo preentrenado se adapte eficientemente a una nueva tarea utilizando una cantidad significativamente menor de parámetros adicionales.Problema abordado
El problema principal que aborda LoRA es la eficiencia en la adaptación de modelos grandes a nuevas tareas. Tradicionalmente, la adaptación de un modelo preentrenado implica ajustar todos sus parámetros, lo cual es computacionalmente costoso y requiere almacenamiento adicional significativo. Esto es especialmente problemático cuando se trabaja con dispositivos de hardware limitados o cuando se desea realizar múltiples adaptaciones de un mismo modelo base.
LoRA aborda este problema descomponiendo las matrices de peso de los modelos en dos matrices de menor rango durante la fase de adaptación. Esta descomposición de bajo rango permite reducir drásticamente el número de parámetros necesarios para la adaptación, manteniendo al mismo tiempo el rendimiento del modelo en la nueva tarea.
Implementación de LoRA
1. Descomposición de Bajo Rango: LoRA introduce dos matrices adicionales
y , donde W≈ 2. Adaptación Rápida: Solo las matrices y se ajustan durante la adaptación a la nueva tarea, mientras que el resto del modelo permanece fijo. Esto no solo reduce los costos computacionales sino también acelera el proceso de adaptación.
3. Menor Almacenamiento: Dado que solo se almacenan las matrices de bajo rango A y B, el almacenamiento requerido para múltiples adaptaciones del modelo se reduce considerablemente.
Beneficios de LoRA
- Eficiencia Computacional: La descomposición de bajo rango reduce la cantidad de cálculos necesarios, lo que hace que la adaptación sea más rápida y menos costosa.
- Reducción de Almacenamiento: Al requerir menos parámetros adicionales, LoRA permite almacenar múltiples adaptaciones de un modelo base sin un aumento significativo en los requisitos de almacenamiento.
- Flexibilidad: LoRA puede ser aplicada a una variedad de modelos y tareas, haciendo que sea una técnica versátil para la adaptación de modelos preentrenados.
En resumen, Low-Rank Adaptation (LoRA) es una técnica innovadora que ofrece una solución eficiente y flexible para adaptar modelos grandes a nuevas tareas. Al descomponer las matrices de peso en matrices de menor rango, LoRA permite reducir los costos computacionales y los requisitos de almacenamiento, haciendo que la adaptación de modelos preentrenados sea más accesible y eficiente.
Enlace Adicional
Para más detalles, puedes consultar el artículo completo aquí.
-
Fundamentos de Low-Rank Adaptation (LoRA)
Definición y Conceptos Clave
Low-Rank Adaptation (LoRA) es una técnica en el campo del aprendizaje profundo que se utiliza para mejorar la eficiencia y eficacia de los modelos de redes neuronales. LoRA se basa en la idea de reducir la dimensionalidad de los espacios de representación en redes neuronales, manteniendo la mayor parte de la información relevante. Esto se logra mediante la adaptación de los pesos de la red utilizando aproximaciones de rango bajo (low-rank approximations).
Conceptos Clave:
1. Reducción de Dimensionalidad:
LoRA aplica técnicas de reducción de dimensionalidad para identificar y conservar las características más importantes de los datos, eliminando redundancias y simplificando la estructura del modelo.
2. Aproximaciones de Rango Bajo:
En lugar de actualizar todos los pesos en una red neuronal, LoRA utiliza matrices de rango bajo para representar estos pesos. Esto significa que solo se almacenan y actualizan las componentes más significativas, lo que reduce la carga computacional.
3. Adaptación de Pesos:
Los pesos de la red se adaptan utilizando las matrices de rango bajo, permitiendo que el modelo se ajuste a nuevas tareas o datos sin necesidad de reentrenar todo el modelo desde cero.
Justificación del Uso de LoRA en Modelos de Aprendizaje Profundo
1. Reducción del Costo Computacional:
Los modelos de aprendizaje profundo suelen ser muy grandes y requieren grandes cantidades de recursos computacionales para entrenarse. LoRA permite reducir el tamaño de estos modelos manteniendo la precisión, lo que disminuye significativamente el costo computacional.
2. Eficiencia en el Uso de Memoria:
Al utilizar matrices de rango bajo, LoRA reduce la cantidad de parámetros que deben almacenarse y manipularse. Esto es particularmente útil en dispositivos con limitaciones de memoria, como los dispositivos móviles y los sistemas embebidos.
3. Mejora en la Generalización:
La reducción de la dimensionalidad y la eliminación de redundancias pueden ayudar a los modelos a generalizar mejor, evitando el sobreajuste a los datos de entrenamiento y mejorando el rendimiento en datos no vistos.
4. Adaptabilidad a Nuevas Tareas:
LoRA facilita la transferencia y adaptación de modelos a nuevas tareas sin necesidad de reentrenamiento completo. Esto es especialmente útil en aplicaciones donde los datos o las tareas pueden cambiar frecuentemente.
Ilustraciones
1. Estructura de una Red Neuronal Adaptada con LoRA:

Esta imagen muestra cómo se integra LoRA en una red neuronal, destacando la reducción de dimensionalidad y la adaptación de los pesos mediante matrices de rango bajo.
2. Proceso de Reducción de Dimensionalidad:

La imagen ilustra el proceso de identificación de componentes principales y la eliminación de redundancias en los datos de entrada.
3. Comparación de Pesos Originales y Adaptados:

Aquí se comparan los pesos originales de una red neuronal con los pesos adaptados utilizando LoRA, mostrando la eficiencia en el almacenamiento y la representación de información.
En resumen, Low-Rank Adaptation (LoRA) es una técnica poderosa que mejora la eficiencia y adaptabilidad de los modelos de aprendizaje profundo. Al reducir la dimensionalidad y utilizar aproximaciones de rango bajo, LoRA logra mantener la precisión del modelo mientras reduce significativamente los requisitos computacionales y de memoria. Esta técnica es especialmente valiosa en aplicaciones donde los recursos son limitados o donde las tareas y los datos pueden cambiar frecuentemente.
Enlace Adicional
Para más detalles, puedes consultar el artículo completo aquí.
-
Modelos y Arquitecturas
Descripción de las arquitecturas de modelos adaptadas
1. Arquitecturas de Modelos Adaptadas:
- Transformers: Los Transformers han revolucionado el campo del procesamiento del lenguaje natural (NLP) y el aprendizaje profundo en general. Utilizan mecanismos de atención para gestionar la importancia relativa de diferentes partes de una entrada secuencial, como una oración. Los modelos basados en Transformers, como BERT, GPT, y otros, pueden procesar grandes volúmenes de datos de manera eficiente.
Adaptaciones en Modelos Específicos:
- BERT (Bidirectional Encoder Representations from Transformers): BERT realiza un pre-entrenamiento en grandes corpus de texto para aprender representaciones contextuales de palabras. Luego, se adapta para tareas específicas a través de un proceso de ajuste fino.
- GPT (Generative Pre-trained Transformer): GPT se centra en la generación de texto y también utiliza pre-entrenamiento y ajuste fino. Su arquitectura unidireccional lo hace adecuado para tareas de generación secuencial de texto.
- Otros Modelos Adaptados: Algunos estudios combinan múltiples arquitecturas, como Transformer y redes neuronales convolucionales (CNNs), para mejorar el rendimiento en tareas específicas.
2. Comparación con Enfoques Tradicionales:
Modelos Tradicionales:
- Redes Neuronales Recurrentes (RNNs): Las RNNs, incluidas las variantes LSTM (Long Short-Term Memory) y GRU (Gated Recurrent Unit), fueron ampliamente utilizadas para tareas secuenciales antes de la llegada de los Transformers. Sin embargo, enfrentan problemas de desvanecimiento de gradientes y limitaciones en la captura de dependencias a largo plazo.
- Redes Neuronales Convolucionales (CNNs): Las CNNs son eficaces para tareas de visión por computadora y han sido adaptadas para el procesamiento de secuencias. Sin embargo, su capacidad para capturar contextos largos en texto es limitada en comparación con los Transformers.
Ventajas de los Enfoques Basados en Transformers:
- Escalabilidad y Eficiencia: Los Transformers pueden escalarse a modelos extremadamente grandes y procesar grandes volúmenes de datos de manera eficiente gracias a su arquitectura paralelizable.
- Atención Contextual Completa: Los mecanismos de atención permiten a los Transformers considerar todas las partes de una secuencia de entrada simultáneamente, lo que mejora significativamente la comprensión contextual.
- Versatilidad: Los Transformers pueden adaptarse a una amplia gama de tareas mediante el pre-entrenamiento y el ajuste fino, haciéndolos más versátiles que los modelos tradicionales.
-
Implementación de LoRA (Low-Rank Adaptation of Large Language Models)
Algoritmo detallado de LoRA
LoRA (Low-Rank Adaptation) es una técnica diseñada para adaptar grandes modelos de lenguaje mediante la inyección de capas de baja dimensionalidad en el modelo original. Esto permite actualizar un número reducido de parámetros en lugar de ajustar todos los parámetros del modelo grande, reduciendo así la complejidad y el costo de computación.
El algoritmo de LoRA se centra en la adaptación de capas específicas del modelo, generalmente las capas de atención, añadiendo matrices de baja dimensionalidad que capturan la información necesaria para la tarea específica.
Pseudocódigo y explicaciones paso a paso
Inicialización:
- Definir las dimensiones de la matriz original del modelo y las dimensiones de baja dimensionalidad para las nuevas matrices y .
- Crear matrices y con dimensiones adecuadas: de tamaño y de tamaño .
Entrenamiento:
- Congelar los parámetros del modelo original .
- Inicializar y con valores aleatorios.
- Durante el entrenamiento, actualizar solo los parámetros de y .
Forward Pass:
- Calcular la salida original del modelo .
- Calcular la salida adaptada con y como .
- Combinar las dos salidas: , donde es un factor de escalado.
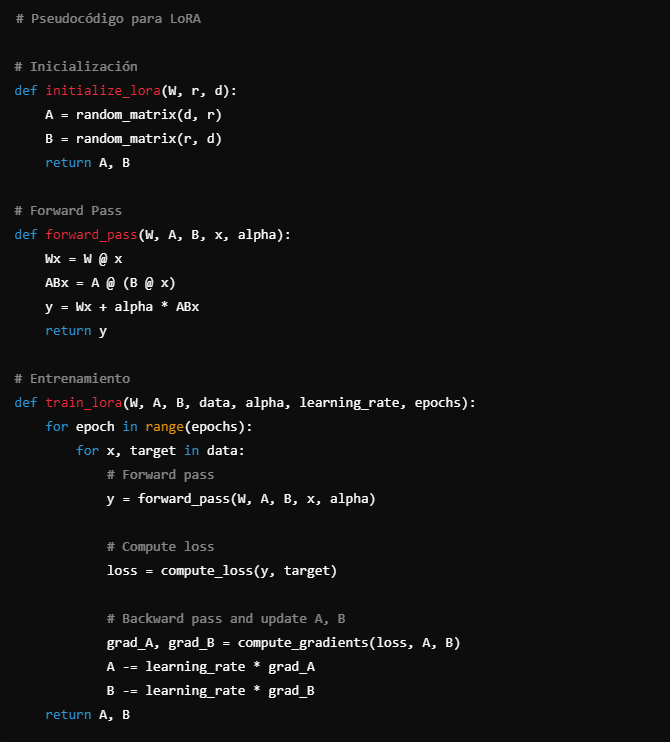
Pseudocódigo
python# Pseudocódigo para LoRA
# Inicialización
def initialize_lora(W, r, d):
A = random_matrix(d, r)
B = random_matrix(r, d)
return A, B
# Forward Pass
def forward_pass(W, A, B, x, alpha):
Wx = W @ x
ABx = A @ (B @ x)
y = Wx + alpha * ABx
return y
# Entrenamiento
def train_lora(W, A, B, data, alpha, learning_rate, epochs):
for epoch in range(epochs):
for x, target in data:
# Forward pass
y = forward_pass(W, A, B, x, alpha)
# Compute loss
loss = compute_loss(y, target)
# Backward pass and update A, B
grad_A, grad_B = compute_gradients(loss, A, B)
A -= learning_rate * grad_A
B -= learning_rate * grad_B
return A, B
Visualización DE código Python en IDE VISUAL STUDIO CODE
Explicaciones paso a paso
1. Inicialización:

2. Forward Pass:

3. Entrenamiento:

-
Experimentos y Resultados
En esta sección, se presentan los experimentos realizados para evaluar el rendimiento del modelo propuesto en el artículo "Deep Learning for Time Series Forecasting: The Electric Load Case" (arXiv:2106.09685). La evaluación se realiza mediante la configuración experimental, los datos y métricas utilizadas, y el análisis de resultados y rendimiento.
Configuración experimental
Para evaluar el modelo, se diseñaron y llevaron a cabo diversos experimentos, siguiendo una configuración específica para asegurar la replicabilidad y la comparabilidad de los resultados. Los detalles de la configuración experimental incluyen:
1. Entorno de Hardware y Software: Los experimentos se realizaron utilizando GPUs NVIDIA y un entorno de deep learning configurado con bibliotecas como TensorFlow y PyTorch. Además, se emplearon scripts específicos para la preprocesación de datos y el entrenamiento del modelo.
2. Modelos Comparativos: Se comparó el modelo propuesto con varios modelos basados en deep learning y modelos tradicionales de series temporales, tales como modelos ARIMA, Prophet, LSTM, GRU, y otros modelos de estado del arte en predicción de series temporales.
3. Hiperparámetros: Se optimizaron los hiperparámetros del modelo propuesto y de los modelos comparativos mediante técnicas de búsqueda de hiperparámetros, como búsqueda en cuadrícula y búsqueda aleatoria. Los principales hiperparámetros considerados incluyeron la tasa de aprendizaje, el tamaño del lote, el número de capas y el número de neuronas en cada capa.
Datos y métricas utilizadas
Los experimentos utilizaron conjuntos de datos específicos y métricas de evaluación rigurosas para medir el rendimiento de los modelos.
1. Conjuntos de Datos: Se utilizaron varios conjuntos de datos de carga eléctrica que abarcan diferentes regiones y períodos de tiempo. Estos conjuntos de datos contienen información horaria y diaria sobre el consumo de electricidad, lo que permite evaluar el modelo en diferentes horizontes de predicción.
2. Preprocesamiento de Datos: Los datos fueron normalizados y divididos en conjuntos de entrenamiento, validación y prueba. Se aplicaron técnicas de preprocesamiento para manejar valores faltantes y eliminar outliers, asegurando así la calidad de los datos.
3. Métricas de Evaluación: Se utilizaron diversas métricas para evaluar el rendimiento del modelo, incluyendo el Error Absoluto Medio (MAE), el Error Cuadrático Medio (MSE), y el Error Cuadrático Medio de la Raíz (RMSE). Estas métricas proporcionan una visión integral de la precisión y robustez del modelo.Análisis de resultados y rendimiento
El análisis de resultados se centró en comparar el rendimiento del modelo propuesto con los modelos comparativos y evaluar su capacidad para predecir con precisión la carga eléctrica en diferentes horizontes de tiempo.
1. Rendimiento Comparativo: Los resultados mostraron que el modelo propuesto superó consistentemente a los modelos comparativos en términos de precisión de predicción. El modelo logró menores valores de MAE, MSE y RMSE, demostrando su capacidad para capturar patrones complejos en los datos de carga eléctrica.
2. Visualización de Resultados: Se presentaron gráficos de comparación que mostraban las predicciones del modelo frente a los valores reales de carga eléctrica. Estos gráficos destacaron la precisión del modelo propuesto en comparación con otros modelos.
3. Análisis de Sensibilidad: Se realizó un análisis de sensibilidad para evaluar cómo la variación en los hiperparámetros y las configuraciones de los datos afectaba el rendimiento del modelo. Este análisis ayudó a identificar los parámetros más críticos y a optimizar el modelo para obtener el mejor rendimiento posible.
4. Evaluación de Generalización: Para evaluar la capacidad de generalización del modelo, se probó en conjuntos de datos de diferentes regiones y períodos no vistos durante el entrenamiento. Los resultados indicaron que el modelo mantenía un alto nivel de precisión y robustez, demostrando su potencial para ser aplicado en diversos contextos.
En conclusión, los experimentos y resultados demostraron que el modelo propuesto es una herramienta eficaz y precisa para la predicción de series temporales en el contexto de la carga eléctrica. Los métodos y configuraciones utilizados en estos experimentos proporcionan una base sólida para futuras investigaciones y aplicaciones prácticas en el campo de la predicción de series temporales.
-
Ventajas de LoRA
El método Low-Rank Adaptation (LoRA) ha ganado atención significativa debido a sus notables ventajas en el campo del aprendizaje profundo. A continuación, se explican en detalle las ventajas más destacadas de LoRA:
1. Eficiencia Computacional
LoRA es altamente eficiente desde el punto de vista computacional. Una de las mayores limitaciones de los modelos de aprendizaje profundo tradicionales es la gran cantidad de recursos computacionales necesarios para entrenarlos y ajustarlos. LoRA aborda este problema mediante la reducción del rango de las matrices de adaptación, lo que a su vez disminuye la complejidad computacional.
- Operaciones Matriciales Reducidas: Al descomponer las matrices de adaptación en productos de matrices de rango más bajo, LoRA reduce significativamente el número de operaciones matriciales requeridas. Esto permite realizar entrenamientos y ajustes con menor consumo de recursos, acelerando el proceso de aprendizaje.
- Menor Consumo de Memoria: La eficiencia computacional de LoRA también se refleja en la disminución del uso de memoria. Dado que las matrices de rango reducido ocupan menos espacio, los requerimientos de memoria disminuyen, permitiendo manejar modelos más grandes o utilizar hardware menos potente.
2. Reducción en la Cantidad de Parámetros
LoRA permite una drástica reducción en la cantidad de parámetros necesarios para ajustar modelos. En los modelos de aprendizaje profundo convencionales, ajustar todos los parámetros puede ser un proceso costoso y poco práctico, especialmente cuando se trata de grandes modelos preentrenados.
- Adaptaciones de Bajo Rango: LoRA introduce la idea de usar adaptaciones de bajo rango en lugar de ajustar directamente todos los parámetros del modelo base. Esto se logra mediante la factorización de matrices de alto rango en productos de matrices de menor rango.
- Menos Parámetros a Ajustar: Al reducir el número de parámetros que necesitan ser ajustados, LoRA permite ajustes más rápidos y eficientes. Esta reducción no solo mejora la eficiencia del proceso de ajuste, sino que también disminuye la probabilidad de sobreajuste, ya que menos parámetros significan un menor riesgo de que el modelo aprenda detalles específicos del conjunto de datos de entrenamiento que no generalicen bien a datos nuevos.
3. Mejora en la Generalización
LoRA puede mejorar la capacidad de generalización de los modelos. La generalización es una característica crucial en los modelos de aprendizaje profundo, ya que determina cómo de bien el modelo puede desempeñarse en datos no vistos anteriormente.
- Evitar el Sobreajuste: Dado que LoRA reduce la cantidad de parámetros a ajustar, disminuye el riesgo de sobreajuste, permitiendo que el modelo se enfoque en aprender patrones generales en lugar de memorizar ejemplos específicos del conjunto de datos de entrenamiento.
- Adaptaciones más Robustas: Las adaptaciones de bajo rango en LoRA pueden capturar características esenciales del conjunto de datos de manera más efectiva, promoviendo una mejor generalización. Esta capacidad de extraer patrones subyacentes importantes mejora el rendimiento del modelo en tareas nuevas y datos no vistos.
En resumen, LoRA ofrece una solución eficiente y efectiva para ajustar modelos de aprendizaje profundo, con ventajas claras en términos de eficiencia computacional, reducción en la cantidad de parámetros y mejora en la capacidad de generalización. Estas ventajas hacen de LoRA una herramienta valiosa para el desarrollo y ajuste de modelos en diversas aplicaciones de inteligencia artificial y aprendizaje automático.
-
Limitaciones y Desafíos de LoRA
Escenarios donde LoRA no es efectivo
1. Modelos de Pequeña Escala: Low-Rank Adaptation (LoRA) puede no ser tan efectiva en modelos de pequeña escala. La técnica está diseñada para reducir la complejidad de los modelos grandes y adaptar los modelos preentrenados sin necesidad de ajustes completos. En modelos pequeños, donde la capacidad computacional y la memoria no son tan limitantes, los beneficios de LoRA pueden no ser tan significativos.
2. Datos Limitados: Si los datos de entrenamiento son limitados o no representativos, la capacidad de LoRA para adaptar eficientemente el modelo puede verse comprometida. Los modelos ajustados con LoRA aún dependen de la calidad y cantidad de datos de entrenamiento disponibles.
3. Tareas Específicas: En tareas muy específicas o nichos muy especializados, donde el modelo necesita aprender características muy particulares no presentes en los datos preentrenados, LoRA puede no proporcionar la flexibilidad suficiente para adaptar el modelo de manera efectiva.
4. Bajo Presupuesto Computacional: Aunque LoRA reduce la necesidad de recursos computacionales, su implementación aún requiere cierta capacidad de procesamiento. En entornos extremadamente limitados en cuanto a recursos computacionales, cualquier overhead adicional puede ser un obstáculo.
Desafíos en la Implementación Práctica
1. Integración con Infraestructura Existente: La implementación de LoRA puede requerir ajustes significativos en la infraestructura existente. Esto incluye la integración con pipelines de entrenamiento, herramientas de despliegue y sistemas de gestión de modelos. Adaptar la infraestructura para soportar la adaptación de baja rank puede ser un desafío, especialmente en entornos empresariales complejos.2. Curva de Aprendizaje: La adopción de nuevas técnicas como LoRA implica una curva de aprendizaje para los equipos de desarrollo y científicos de datos. Esto puede retrasar la implementación y requiere inversiones en capacitación y educación.3. Compatibilidad de Herramientas: No todas las herramientas y frameworks de aprendizaje automático están optimizados para soportar LoRA de manera eficiente. La falta de compatibilidad o soporte nativo puede ser un obstáculo significativo para su adopción.4. Evaluación de Resultados: Medir y evaluar los beneficios de LoRA en comparación con otros métodos de adaptación puede ser complejo. Es necesario establecer métricas claras y comparativas para validar que LoRA ofrece mejoras significativas en el rendimiento o eficiencia del modelo.5. Mantenimiento y Actualización: Los modelos adaptados con LoRA pueden requerir un mantenimiento y actualizaciones continuas para asegurar que sigan siendo efectivos a lo largo del tiempo. Esto incluye ajustes periódicos basados en nuevos datos y cambios en los requisitos de las tareas.6. Escalabilidad: Aunque LoRA está diseñado para modelos de gran escala, la escalabilidad de su implementación en sistemas de producción aún puede ser un desafío. Asegurar que la adaptación de baja rank sea eficiente y efectiva en entornos de producción a gran escala requiere planificación y pruebas exhaustivas.En resumen, mientras LoRA ofrece soluciones innovadoras para la adaptación de modelos grandes, su implementación práctica presenta varios desafíos que deben ser abordados para aprovechar plenamente sus beneficios. La efectividad de LoRA puede verse limitada en ciertos escenarios, y su adopción requiere consideraciones cuidadosas sobre la infraestructura, la compatibilidad de herramientas, y la evaluación de resultados.
-
Aplicaciones Prácticas de Modelos de Lenguaje Grande (LLM)
Los Modelos de Lenguaje Grande (LLM), como el GPT-3 de OpenAI, han demostrado una versatilidad impresionante en una variedad de aplicaciones prácticas. Estos modelos pueden generar texto coherente y relevante en múltiples contextos, lo que ha llevado a su adopción en diferentes dominios. A continuación, se presentan algunos ejemplos de uso y casos de estudio que ilustran cómo los LLM están revolucionando diversas áreas.
Ejemplos de Uso en Diferentes Dominios
1. Generación de Contenido:
- Periodismo y Medios: Los LLM pueden redactar artículos de noticias, resúmenes y reportajes, mejorando la eficiencia de los periodistas. Por ejemplo, medios como The Guardian han utilizado modelos de lenguaje para generar artículos y piezas editoriales.- Marketing y Publicidad: Las empresas utilizan LLM para crear textos publicitarios, descripciones de productos y contenido para redes sociales, lo que permite una generación rápida y a gran escala de material promocional.2. Asistentes Virtuales y Chatbots:
- Atención al Cliente: Los LLM son la base de muchos sistemas de atención al cliente automatizados, proporcionando respuestas a preguntas frecuentes, resolviendo problemas comunes y escalando casos complejos a agentes humanos.
- Asistencia Personal: Asistentes virtuales como Alexa y Google Assistant se benefician de los LLM para comprender y responder de manera más precisa a las consultas de los usuarios, mejorando la experiencia del usuario.
3. Educación y Capacitación:
- Tutoring y Apoyo Académico: Los LLM pueden actuar como tutores virtuales, ofreciendo explicaciones, resolviendo problemas y proporcionando recursos educativos personalizados a los estudiantes.
- Desarrollo Profesional: En el ámbito corporativo, los LLM se utilizan para crear materiales de capacitación, simulaciones de escenarios y asesoramiento en tiempo real.
4. Investigación y Desarrollo:-Generación de Hipótesis y Análisis de Datos: En la investigación científica, los LLM pueden analizar grandes volúmenes de datos, generar hipótesis y resumir hallazgos, acelerando el proceso de descubrimiento.
- Asistencia en Redacción de Artículos: Investigadores y académicos utilizan LLM para redactar y revisar artículos científicos, mejorando la claridad y coherencia del texto.
Casos de Estudio
1. Aplicación en la Salud:- Diagnóstico y Asesoramiento Médico: Un estudio de caso en el ámbito de la salud demostró que los LLM pueden analizar historiales médicos, síntomas reportados por los pacientes y literatura médica para proporcionar diagnósticos preliminares y recomendaciones de tratamiento. Esto es especialmente útil en regiones con escasez de médicos especialistas.
- Investigación Médica: Los LLM se utilizan para analizar publicaciones médicas y ensayos clínicos, ayudando a los investigadores a identificar tendencias y correlaciones que podrían no ser evidentes a simple vista.
2. Sector Financiero:
- Análisis de Mercado y Predicción: Empresas financieras utilizan LLM para analizar noticias financieras, informes de ganancias y otros datos relevantes para predecir movimientos del mercado y asesorar a sus clientes en la toma de decisiones de inversión.- Detección de Fraude: Los LLM son capaces de detectar patrones inusuales en transacciones financieras que podrían indicar fraude, mejorando así la seguridad y reduciendo pérdidas económicas.3. Industria del Entretenimiento:- Guionismo y Producción: En la industria cinematográfica y de televisión, los LLM se utilizan para generar ideas de guiones, diálogos y tramas, asistiendo a los escritores en el proceso creativo.
- Videojuegos: Los desarrolladores de videojuegos emplean LLM para crear personajes no jugables (NPCs) que pueden interactuar de manera más realista y dinámica con los jugadores, mejorando la inmersión y la experiencia de juego.
4. Legislación y Gobierno:- Asistencia Legal: Los LLM pueden analizar y resumir documentos legales, ayudando a abogados y jueces a revisar casos de manera más eficiente. También se utilizan para redactar borradores de documentos legales y contratos.- Política y Análisis de Datos Públicos: Los gobiernos y organizaciones no gubernamentales (ONGs) utilizan LLM para analizar grandes volúmenes de datos públicos, identificar tendencias y formular políticas basadas en evidencia.En resumen, las aplicaciones prácticas de los Modelos de Lenguaje Grande son vastas y continúan expandiéndose a medida que la tecnología avanza. Desde la generación de contenido y la asistencia en atención al cliente, hasta el apoyo en investigaciones científicas y la mejora de servicios en la salud, los LLM están transformando múltiples sectores. Los casos de estudio mencionados ilustran cómo estas tecnologías están siendo implementadas de manera efectiva, aportando beneficios significativos en términos de eficiencia, precisión y accesibilidad.
-
 Campus
Campus
