 Campus
Campus
Diagrama de temas
-
-
Técnicas de Entrenamiento Eficiente
El entrenamiento eficiente de modelos de lenguaje natural implica el uso de estrategias y herramientas para optimizar el uso de recursos computacionales y reducir el tiempo de entrenamiento sin comprometer la calidad del modelo. A continuación, se detallan diversas técnicas y enfoques para lograr un entrenamiento eficiente en diferentes configuraciones de hardware.
Entrenamiento eficiente en una sola GPU
Entrenar en una sola GPU puede ser eficiente con técnicas como:Gradient Accumulation: Acumular gradientes durante múltiples pasos de entrenamiento antes de actualizar los parámetros del modelo, permitiendo usar batch sizes efectivos más grandes que los que caben en la memoria de una sola GPU.
Mixed Precision Training: Usar precisión mixta (combinación de punto flotante de 16 bits y 32 bits) para reducir el uso de memoria y aumentar la velocidad de entrenamiento.
Entrenamiento eficiente en múltiples GPU y paralelismo
Para entrenar eficientemente en múltiples GPU, se pueden utilizar varias estrategias de paralelismo:
- Data Parallelism: Distribuir los datos de entrenamiento entre las GPU, donde cada GPU procesa un subset de los datos y luego sincroniza los gradientes.
- Model Parallelism: Dividir el modelo entre varias GPU, donde diferentes partes del modelo se ejecutan en diferentes GPU.
- Pipeline Parallelism: Dividir el modelo en etapas y distribuirlas entre las GPU, procesando diferentes mini-batches simultáneamente en distintas etapas del modelo.
Entrenamiento eficiente en CPU
Aunque menos común debido a la menor potencia de procesamiento, el entrenamiento en CPU puede ser eficiente usando:
- Optimización del uso de memoria: Ajustar los parámetros de entrenamiento para maximizar el uso de caché y reducir la carga de memoria.
- Uso de bibliotecas optimizadas: Utilizar bibliotecas como Intel MKL y OpenMP para mejorar el rendimiento en CPUs.
Entrenamiento distribuido con DeepSpeed y Fully Sharded Data Parallel (FSDP)
- DeepSpeed: Un framework que optimiza el entrenamiento distribuido con técnicas como ZeRO (Zero Redundancy Optimizer), que reduce los requisitos de memoria al repartir los estados del optimizador y los gradientes entre las GPUs.
- FSDP: Técnica que divide los parámetros del modelo en fragmentos y los distribuye entre las GPU para minimizar el uso de memoria y permitir el entrenamiento de modelos más grandes.
Entrenamiento en TPU con TensorFlow
TPUs (Tensor Processing Units) están diseñadas para acelerar cargas de trabajo de Machine Learning:
- TensorFlow: Ofrece soporte nativo para TPUs, facilitando la configuración y el uso de TPUs para entrenar modelos eficientemente. TensorFlow maneja la distribución de datos y la sincronización de gradientes automáticamente.
Entrenamiento en Apple Silicon con PyTorch
Los chips Apple Silicon (como el M1) ofrecen un rendimiento considerablemente mejorado para tareas de Machine Learning:
- PyTorch: Soporta aceleración nativa en Apple Silicon, permitiendo aprovechar el hardware especializado de Apple para acelerar el entrenamiento de modelos.
Hardware personalizado para entrenamiento
El uso de hardware personalizado como GPUs especializadas, TPUs, y ASICs (Application-Specific Integrated Circuits) permite optimizar el entrenamiento de modelos:
- GPUs especializadas: Diseñadas específicamente para cargas de trabajo de deep learning, como las GPU de la serie NVIDIA A100.
- TPUs: Diseñadas por Google para acelerar el entrenamiento de modelos de Machine Learning.
- ASICs: Circuitos integrados diseñados específicamente para aplicaciones de inteligencia artificial, ofreciendo un rendimiento superior para tareas específicas.
Búsqueda de hiperparámetros utilizando la API de Trainer
La búsqueda de hiperparámetros es crucial para encontrar la mejor configuración de un modelo:
- API de Trainer de Hugging Face: Facilita la búsqueda de hiperparámetros con soporte para integración de herramientas como Ray Tune y Optuna, permitiendo realizar experimentos de forma eficiente para encontrar los mejores parámetros de entrenamiento.
Estas técnicas y herramientas permiten optimizar el proceso de entrenamiento de modelos de lenguaje natural, aprovechando al máximo los recursos disponibles y reduciendo significativamente el tiempo y costo del entrenamiento.
Enlace Adicional
Para más información, visita este sitio.
-
Optimización del Entrenamiento
La optimización del entrenamiento es un aspecto crucial en el desarrollo de modelos de aprendizaje profundo eficientes y precisos. A continuación, se detallan tres técnicas avanzadas de optimización del entrenamiento: la acumulación de gradientes, el checkpointing de gradientes y el entrenamiento de precisión mixta (fp16, bf16).
Acumulación de Gradientes
La acumulación de gradientes es una técnica utilizada para simular el entrenamiento con un tamaño de lote mayor del que la memoria del GPU puede manejar. En lugar de actualizar los pesos del modelo después de cada lote, la acumulación de gradientes permite acumular los gradientes de múltiples lotes antes de realizar una actualización.
Pasos de la Acumulación de Gradientes:
1. Inicialización de Gradientes: Inicializar los gradientes a cero antes de comenzar la acumulación.
2. Forward Pass: Realizar la pasada hacia adelante del modelo para obtener la predicción.
3. Cálculo de Pérdida: Calcular la pérdida utilizando la predicción y las etiquetas reales.
4. Backward Pass: Realizar la pasada hacia atrás para calcular los gradientes, pero sin actualizar los pesos.
5. Acumulación: Sumar los gradientes calculados a los gradientes acumulados.
6. Actualización de Pesos: Después de un número predefinido de lotes (n), actualizar los pesos del modelo usando los gradientes acumulados.
La acumulación de gradientes es particularmente útil cuando se trabaja con modelos grandes y datos de alta resolución, permitiendo un mejor uso de la memoria y una estabilización del proceso de entrenamiento.
Checkpointing de Gradientes
El checkpointing de gradientes es una técnica para reducir el uso de memoria durante el entrenamiento de modelos muy grandes. En lugar de almacenar todos los activaciones intermedias necesarias para la pasada hacia atrás, el checkpointing de gradientes recalcula algunas activaciones durante la pasada hacia atrás para ahorrar memoria.
Cómo Funciona el Checkpointing de Gradientes:
1. Selección de Puntos de Control: Dividir el modelo en segmentos y seleccionar puntos de control donde se almacenarán las activaciones intermedias.
2. Forward Pass Parcial: Durante la pasada hacia adelante, solo se almacenan las activaciones en los puntos de control.
3. Recomputation: Durante la pasada hacia atrás, recalcular las activaciones necesarias desde los puntos de control, en lugar de almacenarlas todas.
4. Backward Pass Completa: Utilizar las activaciones recalculadas para completar la pasada hacia atrás y calcular los gradientes.
Entrenamiento de Precisión Mixta (fp16, bf16)
El entrenamiento de precisión mixta utiliza diferentes precisiones de punto flotante para diferentes partes del modelo durante el entrenamiento. Las precisiones comúnmente utilizadas son fp16 (punto flotante de 16 bits) y bf16 (formato bfloat16).
Ventajas del Entrenamiento de Precisión Mixta:
1. Mejor Uso de la Memoria: Utilizar fp16 o bf16 reduce el uso de memoria, permitiendo modelos y lotes más grandes.
2. Aceleración del Entrenamiento: Las operaciones en fp16 y bf16 son más rápidas que en fp32, lo que acelera el tiempo de entrenamiento.
3. Minimización de Pérdidas de Precisión: Utilizar escalado de pérdida para evitar problemas de subflujo y asegurar que los gradientes se mantengan en un rango adecuado.
Pasos para Implementar el Entrenamiento de Precisión Mixta:
1. Conversión del Modelo: Convertir las partes del modelo a fp16 o bf16, manteniendo algunas partes críticas en fp32 para evitar pérdida de precisión significativa.
2. Escalado de Pérdida: Aplicar escalado de pérdida para ajustar los gradientes y evitar problemas de precisión.
3. Backward Pass y Actualización: Realizar la pasada hacia atrás y actualizar los pesos del modelo utilizando los gradientes escalados.
En resumen, la optimización del entrenamiento mediante técnicas como la acumulación de gradientes, el checkpointing de gradientes y el entrenamiento de precisión mixta permite a los investigadores y desarrolladores maximizar el uso de recursos disponibles, mejorar la eficiencia del entrenamiento y entrenar modelos más complejos. Estas técnicas son esenciales para el desarrollo y la implementación de modelos de aprendizaje profundo de vanguardia.
-
Métodos de Cuantización en Transformadores
La cuantización es una técnica crucial en el procesamiento de modelos de aprendizaje profundo, ya que permite reducir el tamaño del modelo y acelerar el tiempo de inferencia sin sacrificar significativamente la precisión. A continuación, se detallan varios métodos de cuantización utilizados en transformadores, basados en el material de Hugging Face.
Ebitsandbytes
Es una biblioteca optimizada para la cuantización de modelos que facilita la implementación de transformadores más eficientes en términos de memoria y computación. Proporciona herramientas para realizar la cuantización de precisión mixta (mixed-precision quantization), lo que permite a los modelos operar utilizando tanto 8 bits como 16 bits en diferentes partes del proceso de cálculo, mejorando la velocidad y reduciendo el uso de memoria sin perder precisión significativa.
GPTQ (General Purpose Tensor Quantization)Es un método de cuantización general que se puede aplicar a diferentes tipos de modelos de redes neuronales. Utiliza técnicas avanzadas de optimización para ajustar las representaciones tensoriales del modelo, lo que permite una cuantización precisa y eficiente. GPTQ es altamente versátil y se puede adaptar a una variedad de arquitecturas de modelos, incluidos los transformadores.
AWQ (Adaptive Weight Quantization)Se centra en la cuantización adaptativa de los pesos del modelo. Este método ajusta dinámicamente la granularidad de cuantización según la importancia de los pesos, permitiendo una representación más precisa de los componentes críticos del modelo. AWQ es especialmente útil para mantener la precisión del modelo al reducir el tamaño y los requerimientos computacionales.
AQLM (Adaptive Quantization for Language Models)Está diseñado específicamente para modelos de lenguaje. Este método adapta la cuantización a las características únicas de los modelos de procesamiento de lenguaje natural (NLP), como las distribuciones de activación y los patrones de uso de los pesos. AQLM optimiza la cuantización para asegurar que los modelos de lenguaje mantengan su rendimiento en tareas de NLP.
QuantoEs un marco de cuantización integral que abarca múltiples técnicas y estrategias para optimizar modelos de aprendizaje profundo. Integra métodos de cuantización estática y dinámica, permitiendo a los desarrolladores seleccionar y combinar diferentes técnicas según las necesidades específicas de sus aplicaciones. Quanto es conocido por su flexibilidad y efectividad en la reducción de los requisitos computacionales de los modelos.
EETQ (Efficient End-to-End Quantization)Es un método diseñado para proporcionar una cuantización eficiente de extremo a extremo. Este enfoque asegura que cada etapa del proceso de entrenamiento e inferencia esté optimizada para utilizar representaciones cuantizadas, reduciendo significativamente los recursos necesarios sin comprometer la precisión del modelo. EETQ es ideal para implementaciones en entornos con recursos limitados.
HQQ (Hierarchical Quantization for Quality)Introduce un enfoque jerárquico para la cuantización, donde diferentes niveles de la red neuronal se cuantizan con distintas precisiones según su importancia y contribución al rendimiento global del modelo. Este método permite una mejor gestión de los recursos y una reducción más equilibrada del tamaño del modelo, manteniendo altos niveles de precisión.
OptimumEs un conjunto de herramientas de Hugging Face diseñado para facilitar la optimización de modelos, incluida la cuantización. Proporciona interfaces y algoritmos para aplicar métodos de cuantización de manera efectiva, integrándose fácilmente con la infraestructura existente de Hugging Face. Optimum permite a los desarrolladores implementar rápidamente técnicas de cuantización para mejorar el rendimiento y eficiencia de sus modelos de transformadores.
En resumen, la cuantización es una técnica poderosa para optimizar modelos de aprendizaje profundo, permitiendo una ejecución más rápida y eficiente. Los métodos mencionados, como bitsandbytes, GPTQ, AWQ, AQLM, Quanto, EETQ, HQQ y Optimum, ofrecen diversas estrategias y herramientas para implementar cuantización de manera efectiva, cada uno con sus propias ventajas y enfoques específicos para diferentes tipos de modelos y aplicaciones.
-
Optimización de Inferencia
La optimización de la inferencia es crucial para mejorar el rendimiento de los modelos de aprendizaje automático en términos de velocidad y eficiencia de recursos. Existen diferentes técnicas y herramientas para optimizar la inferencia tanto en CPU como en GPU. A continuación, se detallan estas técnicas basadas en el material de Hugging Face.
Optimización de la Inferencia en CPU
Optimizar la inferencia en CPU es vital para aplicaciones donde el uso de GPU no es viable debido a restricciones de costo, disponibilidad o energía. Algunas estrategias clave incluyen:
1. Uso de ONNX Runtime: Open Neural Network Exchange (ONNX) Runtime es una herramienta de optimización que permite ejecutar modelos de aprendizaje profundo con mayor eficiencia en CPU. Convierte modelos entrenados en PyTorch o TensorFlow a un formato ONNX, el cual puede ser optimizado y ejecutado con ONNX Runtime para mejorar la velocidad de inferencia.
2. Intel® Neural Compressor (INC): INC es una herramienta que facilita la optimización de modelos para arquitecturas de CPU Intel®. Ofrece técnicas como la cuantización, la fusión de capas y la optimización de grafos para reducir el tiempo de inferencia y el uso de memoria.
3. Cuantización: Reducir la precisión de los pesos y las activaciones del modelo (por ejemplo, de 32 bits a 8 bits) puede acelerar significativamente la inferencia y disminuir el consumo de memoria. Hugging Face proporciona herramientas para realizar la cuantización sin perder mucha precisión en los resultados.
Optimización de la Inferencia en GPU
La optimización en GPU es fundamental para aplicaciones que requieren altas tasas de procesamiento, como el análisis en tiempo real, procesamiento de video, y aplicaciones de inteligencia artificial a gran escala. Algunas estrategias para optimizar la inferencia en GPU incluyen:
1. TensorRT: TensorRT es una biblioteca de optimización de inferencia desarrollada por NVIDIA. Permite la optimización y despliegue de redes neuronales profundas en GPUs NVIDIA. TensorRT puede aplicar optimizaciones como la fusión de capas, la cuantización y la eliminación de capas redundantes para mejorar el rendimiento de la inferencia.
2. Cuantización de Tensor Cores: Utilizar los Tensor Cores presentes en GPUs NVIDIA más recientes puede acelerar significativamente la inferencia. La cuantización de los modelos para aprovechar estos núcleos puede resultar en un aumento notable en la velocidad de procesamiento sin sacrificar demasiado la precisión.
3. FP16 y FP8 Mixed Precision: La inferencia con precisión mixta (FP16 y FP8) permite reducir el consumo de memoria y aumentar la velocidad de cálculo. Hugging Face ofrece soporte para la inferencia con precisión mixta, que es compatible con la mayoría de las GPUs modernas.
Uso de
torch.compile()para Optimizar la InferenciaPyTorch introdujo
torch.compile()como una herramienta para mejorar la velocidad de inferencia. Esta función permite compilar modelos PyTorch en código optimizado, lo que puede resultar en una ejecución más eficiente. Algunas de las ventajas de utilizartorch.compile()incluyen:1. Optimización Automática:
torch.compile()analiza automáticamente el modelo y aplica una serie de optimizaciones bajo el capó, como la fusión de operaciones, la reordenación de cálculos y la eliminación de redundancias.2. Compatibilidad con Diferentes Backend: Esta herramienta es compatible con múltiples backend de compilación, lo que permite elegir el más adecuado según el hardware disponible y los requisitos de la aplicación.
3. Mejora de la Velocidad de Inferencia: En muchos casos,
torch.compile()puede ofrecer mejoras significativas en la velocidad de inferencia sin requerir cambios en el código del modelo.4. Simplificación del Proceso de Optimización: Al usar
torch.compile(), los desarrolladores pueden evitar la complejidad de aplicar manualmente varias técnicas de optimización, lo que simplifica el proceso de despliegue de modelos eficientes.En resumen, la optimización de la inferencia es un aspecto crucial para el despliegue eficiente de modelos de aprendizaje automático. Tanto en CPU como en GPU, existen diversas herramientas y técnicas que pueden mejorar significativamente el rendimiento. Adicionalmente, el uso de
torch.compile()en PyTorch proporciona una forma automatizada y eficiente de optimizar la inferencia, facilitando la implementación de modelos rápidos y eficaces. -
Uso de la Biblioteca Accelerate
Introducción a Accelerate para Entrenamiento Distribuido
La biblioteca Accelerate es una herramienta poderosa desarrollada por Hugging Face para simplificar el proceso de entrenamiento distribuido de modelos de aprendizaje profundo. Su objetivo principal es permitir a los investigadores y desarrolladores escalar el entrenamiento de modelos sin la necesidad de realizar modificaciones significativas en su código. Accelerate facilita el uso de múltiples GPUs y múltiples nodos, permitiendo un entrenamiento más rápido y eficiente.
La biblioteca Accelerate se encarga de la gestión de dispositivos, la sincronización de parámetros y la coordinación de tareas entre las distintas GPUs o nodos. Además, ofrece una API intuitiva que hace que la transición de un entorno de entrenamiento con una sola GPU a un entorno distribuido sea fluida y sin complicaciones.
Características Principales de Accelerate
1. Facilidad de Uso: Proporciona una API sencilla y fácil de integrar en el código existente.
2. Flexibilidad: Compatible con varios backends como PyTorch, TensorFlow, y JAX.
3. Escalabilidad: Permite el entrenamiento en múltiples GPUs y nodos sin necesidad de modificaciones extensas en el código.
4. Optimización Automática: Gestiona automáticamente la asignación de dispositivos y la comunicación entre ellos.
Ejemplos de Uso de Accelerate para Control Total sobre el Ciclo de Entrenamiento
Aquí se presentan ejemplos prácticos de cómo utilizar Accelerate para tener control total sobre el ciclo de entrenamiento, desde la inicialización hasta la finalización del proceso.
1. Instalación de Accelerate
Para comenzar, se debe instalar la biblioteca Accelerate utilizando pip:
pip install accelerate
2. Inicialización de Accelerate
3. Ciclo de EntrenamientoSe debe inicializar Accelerate en el script de entrenamiento. Esto configura los dispositivos y prepara el entorno para el entrenamiento distribuido:
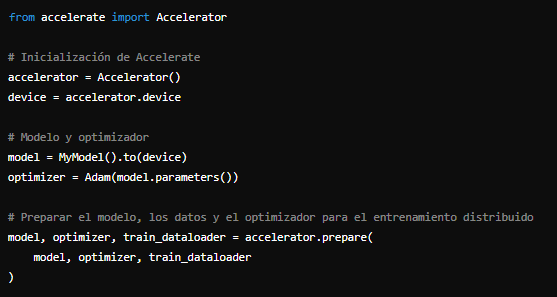 Con Accelerate inicializado, se puede proceder a definir el ciclo de entrenamiento. La biblioteca se encarga de la distribución de datos y sincronización entre dispositivos.
Con Accelerate inicializado, se puede proceder a definir el ciclo de entrenamiento. La biblioteca se encarga de la distribución de datos y sincronización entre dispositivos.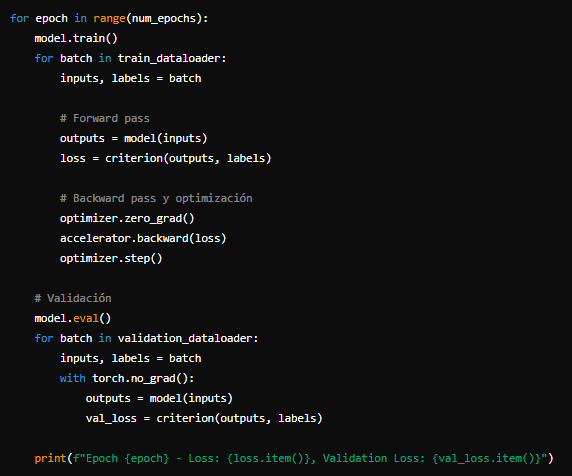 4. Ejecución en Múltiples GPUs
4. Ejecución en Múltiples GPUsPara ejecutar el entrenamiento en múltiples GPUs, se puede utilizar el comando
acceleratedesde la línea de comandos:accelerate launch train.py
Este comando inicia el script de entrenamiento
train.pyen un entorno distribuido, utilizando todas las GPUs disponibles en el sistema.5. Configuración Avanzada
Accelerate permite configuraciones más avanzadas, como el ajuste fino de parámetros de entrenamiento distribuido, mediante un archivo de configuración. Aquí un ejemplo básico de un archivo
`accelerate_config.yaml`: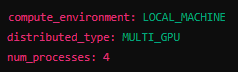
Luego, se puede inicializar Accelerate con este archivo de configuración:
accelerate config
En resumen, la biblioteca Accelerate de Hugging Face es una herramienta esencial para cualquier investigador o desarrollador que desee escalar el entrenamiento de sus modelos de manera eficiente. Con su API intuitiva y su capacidad para manejar la distribución de tareas y sincronización de datos, Accelerate facilita enormemente el proceso de entrenamiento distribuido, permitiendo a los usuarios centrarse en el desarrollo de sus modelos sin preocuparse por la complejidad del entrenamiento en múltiples GPUs o nodos.
-
Integración y Utilidades en el Entrenamiento de Modelos
con Hugging Face
En el contexto del entrenamiento y generación de modelos de lenguaje natural, Hugging Face ofrece un conjunto robusto de herramientas y utilidades que facilitan estos procesos. Este texto explicativo aborda las utilidades disponibles para el entrenamiento y generación de modelos, la integración con XLA para modelos TensorFlow, y la depuración de modelos grandes.
Utilidades para el Entrenamiento y Generación
Hugging Face proporciona una serie de utilidades diseñadas para simplificar y optimizar el proceso de entrenamiento y generación de modelos. Algunas de las utilidades clave incluyen:
Trainer y TrainingArguments
El
Traineres una clase de alto nivel que facilita el entrenamiento y la evaluación de modelos. Junto conTrainingArguments, permite configurar fácilmente los parámetros del entrenamiento, como la tasa de aprendizaje, el tamaño del lote, y las estrategias de optimización. Algunas características importantes incluyen:- Soporte para múltiples GPUs y TPUs: Permite escalar el entrenamiento a múltiples dispositivos.
- Monitoreo y registro: Integra con herramientas como TensorBoard y WandB para visualizar el progreso del entrenamiento.
- Evaluación automática: Realiza evaluaciones periódicas en los conjuntos de validación durante el entrenamiento.
Pipeline
La clase
Pipelinesimplifica el proceso de generación de texto, clasificación, traducción y otras tareas comunes de NLP. Permite aplicar modelos preentrenados directamente a tareas específicas con una mínima configuración.Data Collator y Tokenizer
Estas utilidades manejan la preparación de datos y tokenización, asegurando que los datos de entrada estén en el formato adecuado para el modelo.
DataCollatorgestiona la creación de lotes y el padding, mientras que losTokenizerson responsables de convertir el texto en tensores numéricos.Integración con XLA para Modelos TensorFlow
La integración con XLA (Accelerated Linear Algebra) permite optimizar el rendimiento de los modelos TensorFlow. XLA es un compilador específico de dominio para operaciones lineales en TensorFlow, y su uso puede resultar en mejoras significativas en la velocidad de entrenamiento y en la eficiencia del uso de memoria. Algunas de las ventajas de integrar XLA incluyen:
- Compilación JIT (Just-In-Time): Permite la compilación en tiempo real de las operaciones de TensorFlow, optimizando dinámicamente el código para el hardware específico.
- Reducción del consumo de memoria: XLA puede fusionar múltiples operaciones en una sola, reduciendo la memoria necesaria para almacenar resultados intermedios.
- Optimización de hardware específico: XLA optimiza automáticamente las operaciones para aprovechar al máximo las capacidades del hardware subyacente, como GPUs y TPUs.
Para habilitar XLA en TensorFlow, se puede usar la configuración
tf.config.optimizer.set_jit(True), lo cual instruye a TensorFlow a utilizar el compilador XLA durante el entrenamiento y la inferencia.Depuración de Modelos Grandes
La depuración de modelos grandes presenta desafíos únicos debido a su complejidad y tamaño. Hugging Face ofrece varias estrategias y herramientas para abordar estos desafíos:
Monitoreo del Uso de Recursos
El monitoreo del uso de GPU y memoria es crucial para la depuración de modelos grandes. Herramientas como
nvidia-smiy la integración con frameworks de monitoreo como TensorBoard permiten rastrear el consumo de recursos en tiempo real.Debugging con PyTorch y TensorFlow
Ambos frameworks ofrecen utilidades para depuración en el contexto de modelos grandes. En PyTorch, herramientas como
torch.autograd.profilerytorch.utils.tensorboardfacilitan la inspección de grafos computacionales y el registro de eventos, respectivamente. En TensorFlow,tf.debuggingproporciona funciones para verificar tensores y variables durante la ejecución del modelo.División de Modelos y Checkpoints
Para manejar modelos que no caben en la memoria de una sola GPU, se puede emplear la división de modelos (
model parallelism). Hugging Face facilita esta técnica mediante el uso de las bibliotecastransformersyaccelerate, que permiten distribuir diferentes partes del modelo a distintas GPUs. Además, la utilización de checkpoints intermedios ayuda a reiniciar el entrenamiento desde un punto de control en caso de interrupciones, lo que es esencial para la depuración de modelos de gran escala.Técnicas de Mezclado de Precisión (
Mixed Precision)El uso de técnicas de mezclado de precisión, como el entrenamiento con precisión de 16 bits (FP16), reduce el uso de memoria y acelera el entrenamiento. Hugging Face integra esta funcionalidad mediante
transformersytransformers.optimization, que facilitan la adopción de estas técnicas en proyectos de NLP.En resumen, Hugging Face proporciona un conjunto integral de utilidades y herramientas para optimizar el entrenamiento y la generación de modelos, integrar eficientemente con XLA en TensorFlow, y depurar modelos grandes. Estas funcionalidades permiten a los desarrolladores y científicos de datos abordar los desafíos del entrenamiento de modelos avanzados de NLP con mayor eficacia y eficiencia.
-
Contribución y Desarrollo en Transformers
El proyecto Transformers de Hugging Face es una biblioteca de código abierto para el procesamiento del lenguaje natural (NLP) basada en arquitecturas de modelos de Transformers. La comunidad desempeña un papel crucial en el desarrollo y la mejora continua de esta biblioteca. A continuación, se detalla cómo puedes contribuir a Transformers, añadir un modelo o pipeline, y las guías de pruebas y revisión de Pull Requests.
Cómo Contribuir a Transformers
Contribuir al proyecto Transformers es un proceso accesible y colaborativo. Aquí se presentan algunos pasos y consideraciones importantes:
1. Conoce el Proyecto: Antes de contribuir, es esencial familiarizarse con la estructura del proyecto, su documentación y las contribuciones previas. Puedes explorar el código fuente en el repositorio de GitHub y revisar la documentación oficial para entender mejor cómo funciona la biblioteca.
2. Identifica un Área de Mejora: Busca issues (problemas) abiertos en el repositorio de GitHub que estén marcados con etiquetas como "good first issue" o "help wanted". Estas etiquetas indican problemas que son buenos puntos de partida para nuevos contribuidores.
3. Comunicación: Si tienes una idea para una mejora o un nuevo feature, abre un issue en GitHub para discutirlo con los mantenedores del proyecto. Esto ayuda a garantizar que tu contribución esté alineada con la dirección del proyecto.
4. Clona y Configura el Repositorio: Clona el repositorio de Transformers en tu máquina local y sigue las instrucciones en la documentación para configurar tu entorno de desarrollo. Asegúrate de instalar todas las dependencias necesarias.
5. Realiza Cambios: Trabaja en tu feature o corrección de errores en una rama separada. Sigue las guías de estilo y convenciones de codificación del proyecto para mantener la coherencia en el código.
6. Pruebas: Asegúrate de que tu código esté bien probado. Añade pruebas unitarias y funcionales para cubrir tus cambios. Utiliza las herramientas de prueba y los scripts proporcionados en el repositorio.
7. Pull Request (PR): Una vez que estés satisfecho con tus cambios, abre un Pull Request en GitHub. Describe claramente qué cambios has hecho y por qué. Incluye referencias a issues relevantes y detalles sobre cómo probar tus cambios.
Cómo Añadir un Modelo o Pipeline a Transformers
Añadir un nuevo modelo o pipeline a la biblioteca Transformers implica varios pasos técnicos y de coordinación con la comunidad. A continuación se presentan los pasos clave:
1. Implementación del Modelo/Pipeline: Implementa el nuevo modelo o pipeline en el código fuente de Transformers. Asegúrate de que tu implementación sea coherente con la estructura y las prácticas de la biblioteca.
2. Configuración del Modelo: Crea los archivos de configuración necesarios para tu modelo. Esto incluye definir las clases de configuración, tokenizadores, y cualquier otro componente específico del modelo.
3. Documentación: Añade documentación detallada para tu modelo o pipeline. Esto incluye ejemplos de uso, descripción de parámetros y cualquier otro detalle relevante que los usuarios necesiten saber.
4. Pruebas: Implementa pruebas para asegurar que tu modelo o pipeline funciona correctamente. Asegúrate de cubrir diferentes casos de uso y de que las pruebas sean reproducibles.
5. Revisión y Coordinación: Abre un Pull Request con tu implementación y documentación. Participa en la revisión del código y responde a los comentarios de los mantenedores del proyecto. Ajusta tu código según sea necesario para cumplir con los estándares del proyecto.
Guías de Pruebas y Revisión de Pull Requests
Las pruebas y la revisión de Pull Requests son fundamentales para mantener la calidad y estabilidad del código en Transformers. Aquí se describen algunas guías importantes:
1. Escribir Pruebas: Asegúrate de que todos los cambios en el código estén acompañados de pruebas adecuadas. Utiliza frameworks de prueba como pytest y añade pruebas unitarias y funcionales para cubrir tus cambios.
2. Revisar Código: Cuando revises Pull Requests de otros contribuidores, proporciona comentarios constructivos y específicos. Revisa la lógica del código, la coherencia con las guías de estilo, la cobertura de pruebas y la documentación.
3. Cumplimiento de Estándares: Verifica que el código cumple con las guías de estilo y convenciones de codificación del proyecto. Utiliza herramientas de linting y formateo automático para ayudar en este proceso.
4. Colaboración: Trabaja de manera colaborativa con otros contribuidores y mantenedores. La revisión de Pull Requests es una oportunidad para aprender y mejorar colectivamente el código.
5. Documentación y Ejemplos: Asegúrate de que cualquier cambio en el código esté bien documentado y acompañado de ejemplos que faciliten a los usuarios entender y utilizar las nuevas características.
En resumen, contribuir al proyecto Transformers es una excelente manera de mejorar tus habilidades en NLP y colaborar con una comunidad global de desarrolladores. Siguiendo estas guías, puedes asegurarte de que tus contribuciones sean valiosas y de alta calidad.
-
Guías Conceptuales
Filosofía y glosario
Filosofía del entrenamiento de modelos: La filosofía detrás del entrenamiento de modelos de lenguaje natural, especialmente los modelos de lenguaje grande (LLMs), se centra en la creación de sistemas capaces de comprender y generar texto humano con una precisión y fluidez asombrosas. Esta filosofía se fundamenta en varios principios clave:
1. Aprendizaje profundo: Utiliza arquitecturas de redes neuronales profundas que permiten al modelo capturar complejas relaciones en los datos.
2. Escalabilidad: La capacidad de entrenar modelos cada vez más grandes, aprovechando grandes volúmenes de datos y poder computacional para mejorar el rendimiento.
3. Generalización: Diseñar modelos que puedan generalizar bien a tareas y dominios no vistos durante el entrenamiento.
4. Transferencia de conocimiento: Aprovechar el conocimiento aprendido en tareas previas para mejorar el rendimiento en nuevas tareas a través del uso de modelos preentrenados y afinados.
Glosario de términos clave:
- Transformers: Arquitectura de red neuronal utilizada en muchos LLMs, caracterizada por su capacidad de atención y eficiencia en el manejo de secuencias largas.
- Fine-tuning (Afinado): Proceso de adaptar un modelo preentrenado a una tarea específica mediante un entrenamiento adicional con un conjunto de datos específico.
- Pre-entrenamiento: Fase inicial del entrenamiento donde el modelo aprende de un gran corpus de texto sin etiquetas, adquiriendo una base amplia de conocimiento lingüístico.
- Attention Mechanism: Mecanismo que permite al modelo enfocarse en partes relevantes de la entrada para hacer predicciones más precisas.
- Masked Language Model (MLM): Técnica de pre-entrenamiento donde ciertas palabras en la entrada son ocultas y el modelo debe predecirlas, utilizada en modelos como BERT.Anatomía del entrenamiento de modelos
El entrenamiento de modelos de lenguaje se puede desglosar en varias etapas fundamentales:
1. Preprocesamiento de datos:
- Limpieza y tokenización: El texto crudo se limpia y se divide en tokens (palabras, subpalabras, o caracteres).
- Creación de datasets: Los datos se organizan en conjuntos de entrenamiento, validación y prueba.2. Pre-entrenamiento:
- Entrenamiento no supervisado: El modelo aprende patrones lingüísticos generales de grandes cantidades de texto sin etiquetas.
- Objetivos de pre-entrenamiento: Se utilizan objetivos como el enmascaramiento de palabras (MLM) o la predicción de la siguiente oración (NSP) para entrenar el modelo.
3. Afinado (Fine-tuning):
- Entrenamiento supervisado: El modelo se ajusta utilizando un conjunto de datos etiquetado específico para una tarea, como clasificación de texto o reconocimiento de entidades.
- Evaluación y ajuste: El modelo se evalúa en el conjunto de validación, y se ajustan los hiperparámetros para optimizar el rendimiento.4. Evaluación y despliegue:
- Pruebas exhaustivas: Se realizan pruebas en el conjunto de datos de prueba para asegurar la generalización del modelo.
- Despliegue: El modelo entrenado se despliega en un entorno de producción para su uso en aplicaciones reales.Cómo obtener el máximo provecho de los LLMs
Para maximizar el rendimiento de los LLMs, se deben considerar varios aspectos clave:
1. Selección de datos de calidad: Utilizar datos limpios y relevantes para el pre-entrenamiento y afinado.2. Optimización de hiperparámetros: Ajustar parámetros como la tasa de aprendizaje, el tamaño del lote y la cantidad de capas para encontrar la configuración óptima.3. Regularización y técnicas de mejora del rendimiento: Emplear técnicas como el Dropout y la normalización por lotes para evitar el sobreajuste.4. Evaluación continua: Implementar un proceso iterativo de evaluación y mejora para asegurar que el modelo se mantenga preciso y relevante.5. Uso de herramientas y bibliotecas avanzadas: Aprovechar herramientas como Hugging Face Transformers para simplificar el proceso de entrenamiento y afinado.BERTology y análisis de atención
- BERTology: La BERTology es el estudio y análisis profundo del modelo BERT (Bidirectional Encoder Representations from Transformers). Se enfoca en entender cómo BERT representa y procesa el lenguaje, desglosando sus componentes y analizando su comportamiento.
- Representaciones bidireccionales: BERT lee el texto en ambas direcciones (izquierda a derecha y derecha a izquierda) para entender mejor el contexto.
- Capas de transformador: Utiliza múltiples capas de transformador para capturar relaciones complejas en el texto.
- Máscara de lenguaje: Predice palabras enmascaradas en el texto para mejorar la comprensión del contexto.- Análisis de atención: El análisis de atención en modelos como BERT implica estudiar cómo el modelo asigna "atención" a diferentes partes de la entrada durante el procesamiento.
- Mapas de atención: Visualizan qué partes del texto reciben más atención durante la inferencia.- Patrones de atención: Identificar patrones de atención ayuda a entender cómo el modelo procesa dependencias a largo plazo y relaciones sintácticas.- Interpretabilidad: Mejora la interpretabilidad del modelo al mostrar cómo se toman las decisiones basadas en la entrada.Estas guías conceptuales proporcionan una base sólida para entender y optimizar el entrenamiento de modelos de lenguaje, aprovechando al máximo las capacidades de los LLMs y desentrañando los intrincados mecanismos de modelos como BERT.
-
 Campus
Campus
