Resultados y Evaluación
En este artículo, exploraremos cómo BERT se desempeña en diferentes tareas de NLP, comparándolo con otros modelos y benchmarks, y analizando la interpretación de los resultados obtenidos en diversos experimentos.
Rendimiento del modelo BERT en diferentes tareas de NLP
BERT ha demostrado ser altamente efectivo en una amplia gama de tareas NLP, tales como clasificación de texto, extracción de entidades, y respuesta a preguntas, entre otras. Su capacidad para capturar el contexto bidireccional y su entrenamiento en grandes corpus de texto lo posicionan como uno de los modelos más versátiles y precisos en NLP contemporáneo.
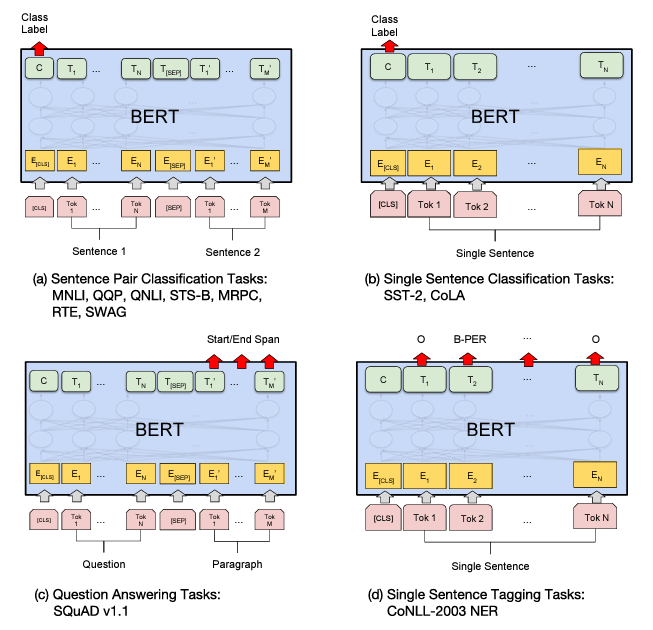
Ilustracion de Fine-tunning en diferentes tareas de BERT.
Comparaciones con otros modelos y benchmarks
Comparado con modelos previos como Word2Vec y GloVe, BERT ha superado consistentemente en una variedad de métricas de evaluación. En benchmarks estándar como GLUE (General Language Understanding Evaluation) y SQuAD (Stanford Question Answering Dataset), BERT ha establecido nuevos récords en términos de precisión y velocidad de entrenamiento, demostrando su superioridad en la comprensión del lenguaje natural.
Interpretación de los resultados obtenidos en los experimentos
Los experimentos muestran que la arquitectura Transformer de BERT permite una representación semántica profunda y precisa del texto, lo que mejora significativamente la capacidad del modelo para capturar matices lingüísticos y contextuales. La interpretación de estos resultados subraya la eficacia de BERT en la comprensión del lenguaje natural y su capacidad para generalizar en una amplia variedad de dominios y tareas.
Enlace Adicional
para más información, visite este sitio.
 Campus
Campus
 Campus
Campus
