 Campus
Campus
Diagrama de temas
-
Ajuste Fino (Fine-tuning) en BERT
El ajuste fino es un proceso crucial en la utilización de modelos de lenguaje como BERT (Bidirectional Encoder Representations from Transformers) para tareas específicas. A continuación, se detalla este proceso de manera comprensible para principiantes, incorporando imágenes que faciliten la comprensión.
Proceso de Inicialización del Modelo Pre-entrenado con Parámetros Específicos
El primer paso en el ajuste fino es la inicialización del modelo pre-entrenado. BERT es pre-entrenado en una gran cantidad de texto no etiquetado utilizando dos tareas: el Modelo de Lenguaje enmascarado (Masked Language Model, MLM) y la Predicción de la siguiente oración (Next Sentence Prediction, NSP). Este pre-entrenamiento proporciona al modelo una comprensión general del lenguaje. Para ajustarlo a una tarea específica, inicializamos BERT con estos parámetros pre-entrenados.
Ajuste Fino Utilizando Datos Etiquetados de Tareas Específicas
Una vez que el modelo está inicializado con los parámetros pre-entrenados, el siguiente paso es el ajuste fino. Este proceso implica entrenar el modelo utilizando datos etiquetados específicos de la tarea a realizar. Durante el ajuste fino, se realizan pequeñas actualizaciones a los parámetros del modelo para que aprenda a realizar la tarea específica de manera eficaz.
Proceso de Ajuste Fino:
1. Carga del Modelo Pre-entrenado: Se carga el modelo BERT pre-entrenado.
2. Adición de una Capa de Salida: Se agrega una capa de salida específica para la tarea (por ejemplo, una capa de clasificación para el análisis de sentimientos).
3. Entrenamiento con Datos Etiquetados: Se entrena el modelo con los datos etiquetados específicos de la tarea. Este proceso puede implicar el uso de técnicas como el aprendizaje supervisado.
4. Ajuste de Parámetros: Durante el entrenamiento, los parámetros del modelo se ajustan ligeramente para optimizar el rendimiento en la tarea específica.
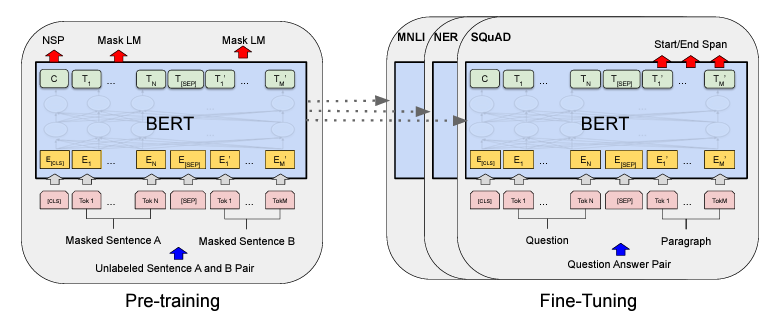
En general, los procedimientos de preentrenamiento y ajuste fino para BERT son los mismos. Aparte de las capas de salida, se utilizan las mismas arquitecturas tanto en el preentrenamiento como en el ajuste fino. Los mismos parámetros del modelo preentrenado se utilizan para inicializar los modelos para diferentes tareas downstream. Durante el ajuste fino, todos los parámetros se ajustan. [CLS] es un símbolo especial añadido al principio de cada ejemplo de entrada, y [SEP] es un token separador especial (por ejemplo, separando preguntas/respuestas).
Ejemplos de Tareas Downstream
Las tareas downstream son tareas específicas para las que se ajusta finamente el modelo BERT. Algunos ejemplos comunes incluyen:
Question Answering (QA)
El question answering es una tarea en la que el modelo debe responder preguntas basadas en un contexto dado. En esta tarea, se proporciona un párrafo de texto y una pregunta relacionada con ese texto. El modelo debe identificar la respuesta dentro del párrafo.
Ejemplo de Proceso de QA:
1. Contexto: Un párrafo de texto.
2. Pregunta: Una pregunta relacionada con el contenido del párrafo.
3. Respuesta: El modelo identifica la respuesta dentro del párrafo.
Análisis de Sentimientos
En el análisis de sentimientos, el modelo clasifica un texto en categorías como positivo, negativo o neutral. Este tipo de tarea es útil en aplicaciones como el análisis de opiniones en redes sociales.
Clasificación de Texto
La clasificación de texto implica asignar etiquetas a fragmentos de texto. Por ejemplo, clasificar correos electrónicos como spam o no spam.
Reconocimiento de Entidades Nombradas (NER)
En NER, el modelo identifica y clasifica entidades mencionadas en un texto en categorías predefinidas, como nombres de personas, organizaciones o ubicaciones.
En resumen, el ajuste fino de BERT permite adaptar un modelo pre-entrenado a tareas específicas utilizando datos etiquetados. Este proceso es esencial para obtener un alto rendimiento en aplicaciones prácticas como el question answering, el análisis de sentimientos y la clasificación de texto. Con una comprensión adecuada del ajuste fino, los modelos de lenguaje como BERT pueden ser herramientas poderosas en una amplia gama de aplicaciones de procesamiento de lenguaje natural.
 Campus
Campus
