 Campus
Campus
Diagrama de temas
-
-
Modelos de Lenguaje de Gran Escala (LLMs): Introducción a BERT
Los Modelos de Lenguaje de Gran Escala (LLMs) han revolucionado el campo del Procesamiento del Lenguaje Natural (NLP) al permitir que las máquinas comprendan y generen texto humano con una precisión sin precedentes. Uno de los modelos más influyentes en este campo es BERT (Bidirectional Encoder Representations from Transformers), presentado por Google en 2018. En esta explicación detallada, abordaremos el propósito de BERT, su arquitectura y cómo se compara con otros modelos de representación del lenguaje.
Presentación del modelo BERT y su propósito
BERT es un modelo de lenguaje basado en la arquitectura Transformer, diseñado para preentrenar representaciones bidireccionales profundas mediante el uso de una técnica llamada enmascaramiento. A diferencia de los modelos previos que leían el texto de manera unidireccional (de izquierda a derecha o de derecha a izquierda), BERT es capaz de considerar el contexto completo de una palabra, tanto a su izquierda como a su derecha, para generar una representación más rica y precisa.
Propósito de BERT:- Mejora en Tareas de NLP: BERT fue creado para mejorar el rendimiento en una amplia gama de tareas de NLP, como la respuesta a preguntas, la clasificación de textos y el análisis de sentimientos.
- Representaciones Contextuales: Generar representaciones contextuales de palabras que capturen mejor su significado en diferentes contextos.
- Transferencia de Aprendizaje: Permitir la transferencia de aprendizaje mediante el preentrenamiento en grandes cantidades de datos no etiquetados y luego la afinación en tareas específicas con datos etiquetados.
Arquitectura de BERT:La arquitectura de BERT se basa en el Transformer, específicamente en la parte del codificador (encoder). Utiliza múltiples capas de atención (attention) para procesar las secuencias de entrada y generar representaciones de alta calidad.Fuente: jalammar.github.io
Entrenamiento de BERT:- Máscara de Lenguaje (Masked Language Model, MLM): Durante el preentrenamiento, BERT enmascara aleatoriamente algunas de las palabras en una secuencia y trata de predecir esas palabras en función del contexto bidireccional.
- Predicción de Siguiente Oración (Next Sentence Prediction, NSP): También se entrena para predecir si dos oraciones consecutivas en el corpus de entrenamiento realmente siguen una a la otra.
Fuente: jalammar.github.io
Comparación con otros modelos de representación del lenguajeAntes de la introducción de BERT, varios modelos de lenguaje dominaron el campo del NLP. A continuación, comparamos BERT con algunos de estos modelos:Word2Vec y GloVe:
- Representación Estática: Ambos modelos generan representaciones estáticas de palabras, es decir, cada palabra tiene una representación fija independientemente del contexto.
- Limitaciones Contextuales: No pueden capturar el significado contextual de las palabras en diferentes oraciones.
ELMo (Embeddings from Language Models):
- Contexto Bidireccional: Introdujo representaciones contextuales de palabras, pero separadamente para izquierda a derecha y derecha a izquierda.
- Combinación Lineal: Las representaciones finales son una combinación lineal de las capas del modelo, lo cual es menos flexible que el enfoque de BERT.
GPT (Generative Pre-trained Transformer):
- Unidireccional: Genera representaciones unidireccionales (de izquierda a derecha).
- Generación de Texto: Enfocado en la generación de texto coherente.
Ventajas de BERT sobre estos modelos:
- Bidireccionalidad Completa: Considera el contexto completo de una palabra, mejorando la precisión en tareas de NLP.
- Adaptabilidad: Puede ser afinado fácilmente en una variedad de tareas específicas, lo que lo hace extremadamente versátil.
Fuente: jalammar.github.io
En resumen, BERT ha marcado un hito en el desarrollo de modelos de lenguaje de gran escala al ofrecer representaciones contextuales bidireccionales que capturan de manera más efectiva el significado de las palabras en su contexto. Su capacidad para ser preentrenado en grandes corpus de datos no etiquetados y afinado en tareas específicas ha establecido nuevos estándares en el campo del Procesamiento del Lenguaje Natural, superando a los modelos anteriores en precisión y versatilidad. -
Arquitectura del Modelo
Los Modelos de Lenguaje de Gran Escala (LLMs) son una categoría avanzada de modelos de aprendizaje profundo diseñados para comprender y generar texto natural. Estos modelos han revolucionado el procesamiento del lenguaje natural (NLP) mediante el uso de grandes cantidades de datos y arquitecturas de red neuronal sofisticadas. En esta explicación detallada, exploraremos la arquitectura del modelo, centrándonos en el modelo de Transformer bidireccional, comparándolo con modelos anteriores como GPT y explicando sus componentes clave.
Arquitectura del Modelo: Transformer Bidireccional
Descripción del Modelo de Transformer Bidireccional
El modelo de Transformer bidireccional, también conocido como BERT (Bidirectional Encoder Representations from Transformers), es un tipo de modelo de lenguaje que se diferencia de otros modelos previos debido a su capacidad para considerar el contexto de las palabras desde ambas direcciones (izquierda y derecha) simultáneamente. A continuación, se describen los aspectos clave de su arquitectura:
1. Capas del Transformer:
- El modelo de Transformer está compuesto por múltiples capas de transformadores apilados. Cada capa consiste en una subcapa de autoatención seguida por una red neuronal feedforward.
- La autoatención permite que el modelo asigne diferentes pesos a diferentes palabras en la secuencia de entrada, dependiendo de su relevancia para cada palabra específica.
2. Tamaño Oculto:
- El tamaño oculto se refiere a la dimensión de las representaciones internas dentro del modelo. En BERT, el tamaño oculto determina la cantidad de información que cada capa puede capturar y procesar.
- Un tamaño oculto más grande permite que el modelo capture más detalles y matices del lenguaje, pero también requiere más recursos computacionales.
3. Cabezas de Autoatención:
- En lugar de usar una sola cabeza de autoatención, BERT utiliza múltiples cabezas de autoatención (generalmente 12 o 16). Cada cabeza puede enfocarse en diferentes partes de la secuencia de entrada, lo que permite al modelo capturar diversos aspectos de las relaciones entre palabras.
- Las múltiples cabezas de autoatención se combinan al final de la capa para formar una representación rica y completa de la secuencia.
Comparación con Modelos Anteriores como GPT
GPT (Generative Pre-trained Transformer) y BERT comparten muchas similitudes en términos de su arquitectura base de Transformer, pero también tienen diferencias significativas:
Direccionalidad:
- GPT: Es un modelo unidireccional, lo que significa que predice la siguiente palabra en una secuencia considerando solo el contexto de las palabras anteriores. Este enfoque es útil para tareas generativas.
- BERT: Es bidireccional, lo que significa que considera el contexto de ambas direcciones, izquierda y derecha, al mismo tiempo. Esto permite una comprensión más profunda y precisa del texto.
Objetivos de Entrenamiento:
- GPT: Se entrena utilizando el objetivo de modelado de lenguaje autoregresivo, donde el modelo predice la siguiente palabra en una secuencia.
- BERT: Utiliza dos objetivos de entrenamiento principales: el modelado de lenguaje enmascarado (MLM), donde algunas palabras en la secuencia de entrada se enmascaran y el modelo debe predecirlas, y la predicción de la próxima oración (NSP), donde el modelo predice si dos oraciones en una secuencia son contiguas.
Aplicaciones:
- GPT: Es más adecuado para tareas de generación de texto, como la escritura creativa y la generación de respuestas conversacionales.
- BERT: Es más efectivo para tareas de comprensión de texto, como la clasificación de texto, el análisis de sentimientos y la respuesta a preguntas.
Componentes Clave
1. Capas:
Cada capa en un Transformer consta de una subcapa de autoatención y una subcapa de red neuronal feedforward. En BERT, puede haber hasta 24 capas, lo que permite una mayor capacidad de aprendizaje.
2. Tamaño Oculto:
El tamaño oculto en BERT varía según la versión del modelo (BERT-base tiene un tamaño oculto de 768, mientras que BERT-large tiene un tamaño oculto de 1024). Un tamaño oculto mayor permite que el modelo capture más información contextual.
3. Cabezas de Autoatención:
Las múltiples cabezas de autoatención (por ejemplo, 12 en BERT-base y 16 en BERT-large) permiten que el modelo enfoque en diferentes partes de la secuencia de entrada simultáneamente, mejorando la capacidad del modelo para capturar relaciones complejas entre palabras.
En resumen, los modelos de lenguaje de gran escala como BERT han avanzado significativamente en la comprensión y generación de texto natural. La arquitectura de Transformer bidireccional, con sus componentes clave como las capas de autoatención, el tamaño oculto y las múltiples cabezas de autoatención, proporciona una base poderosa para una amplia gama de aplicaciones de NLP.Estos avances permiten a los modelos de lenguaje entender mejor el contexto y los matices del lenguaje humano, proporcionando mejoras significativas en tareas de procesamiento de lenguaje natural.
-
Representaciones de Entrada/Salida en BERT
BERT (Bidirectional Encoder Representations from Transformers) es un modelo de lenguaje que ha revolucionado el procesamiento del lenguaje natural. A continuación, se explica cómo BERT maneja las representaciones de entrada y salida, utilizando embeddings de WordPiece y tokens especiales.
1. Cómo BERT maneja las representaciones de entrada para diversas tareas
BERT está diseñado para manejar tareas de procesamiento de lenguaje natural como clasificación de textos, respuesta a preguntas, y etiquetado de secuencias. Para lograr esto, transforma las entradas (secuencias de texto) en representaciones numéricas que el modelo puede procesar. Estas representaciones se crean a partir de embeddings, que son vectores que capturan el significado de las palabras en un espacio multidimensional.
2. Uso de embeddings de WordPiece con un vocabulario de 30,000 tokens
BERT utiliza un método llamado WordPiece para crear sus embeddings. WordPiece es una técnica que divide palabras en subpalabras o piezas de palabras. Por ejemplo, la palabra "playing" podría dividirse en "play" y "##ing". Este enfoque ayuda a manejar palabras raras o nuevas al representarlas como combinaciones de subunidades más comunes. BERT tiene un vocabulario de 30,000 tokens, lo que incluye palabras completas y piezas de palabras.
3. Representación de secuencias de una o dos oraciones
BERT puede trabajar con secuencias que consisten en una o dos oraciones. Para una sola oración, BERT simplemente la procesa como una secuencia de tokens. Para dos oraciones, BERT las combina en una sola secuencia con un token especial [SEP] que las separa. Esta capacidad es útil para tareas como la clasificación de pares de oraciones, donde el modelo necesita entender la relación entre dos oraciones.
4. Tokens especiales [CLS] y [SEP]
BERT utiliza dos tokens especiales en sus entradas:
- [CLS]: Este token se coloca al principio de cada secuencia y actúa como un representante de la secuencia completa. En tareas de clasificación, la representación del token [CLS] se utiliza para predecir la etiqueta de la secuencia.
- [SEP]: Este token se utiliza para separar dos oraciones en una secuencia. Ayuda a BERT a distinguir entre diferentes partes de la entrada.
Ejemplo de representación de entrada en BERT
Consideremos el ejemplo de dos oraciones: "El gato está en la casa." y "El perro está en el jardín." La entrada a BERT sería algo así:
[CLS] El gato está en la casa . [SEP] El perro está en el jardín . [SEP]
Cada palabra (o subpalabra) se convierte en un embedding de WordPiece. El token [CLS] proporciona una representación para la tarea de clasificación, y los tokens [SEP] separan las oraciones.
En resumen, BERT maneja las representaciones de entrada utilizando embeddings de WordPiece, permitiendo manejar un vocabulario extenso de 30,000 tokens. Las secuencias pueden consistir en una o dos oraciones, separadas por el token [SEP], mientras que el token [CLS] se utiliza para representar la secuencia completa en tareas de clasificación. Esta estructura de entrada permite a BERT procesar y comprender el lenguaje natural de manera eficiente y efectiva.
-
Pre-entrenamiento de BERT
Una parte crucial del éxito de BERT radica en su pre-entrenamiento, que se lleva a cabo a través de dos tareas no supervisadas: Masked Language Model (MLM) y Next Sentence Prediction (NSP).
Tareas de Pre-entrenamiento no Supervisadas
Tarea 1: Masked Language Model (MLM)
La tarea de MLM es fundamental para que BERT comprenda el contexto de una palabra dentro de una oración. A continuación, se explica el proceso:
1. Enmascaramiento y Predicción de Tokens:
- En este proceso, se selecciona aleatoriamente el 15% de las palabras en una oración y se reemplazan con un token especial
[MASK]. El objetivo del modelo es predecir las palabras originales en esos lugares enmascarados basándose en el contexto proporcionado por las palabras no enmascaradas alrededor de ellos.- En esta imagen se muestra cómo se enmascaran palabras específicas en una oración y cómo BERT predice las palabras enmascaradas.
2. Comparación con Modelos de Lenguaje Tradicionales:
- A diferencia de los modelos de lenguaje tradicionales que predicen la siguiente palabra en una secuencia de izquierda a derecha (o de derecha a izquierda), BERT predice palabras enmascaradas dentro de una oración completa, lo que le permite entender mejor el contexto bidireccional.
Tarea 2: Next Sentence Prediction (NSP)La tarea de NSP ayuda a BERT a comprender la relación entre dos oraciones consecutivas, lo cual es crucial para muchas tareas de NLP, como la respuesta a preguntas y la comprensión de textos.
1. Importancia de Entender la Relación entre Dos Oraciones:
Saber si dos oraciones están relacionadas de manera lógica o si una oración sigue naturalmente a la otra es esencial para tareas como la clasificación de texto y la generación de lenguaje natural.
2. Metodología para la Predicción de la Siguiente Oración:
En este proceso, se proporciona al modelo un par de oraciones. El 50% de las veces, la segunda oración es la oración que realmente sigue a la primera en el texto original. El otro 50% de las veces, la segunda oración es una oración aleatoria de otro documento. El modelo debe predecir si la segunda oración es la continuación real de la primera.
En resumen, el pre-entrenamiento de BERT mediante las tareas de MLM y NSP permite que el modelo comprenda el contexto de las palabras en una oración de manera más efectiva y que capte las relaciones entre oraciones. Estas capacidades son fundamentales para mejorar el rendimiento en una variedad de tareas de NLP. BERT, a través de su pre-entrenamiento exhaustivo, se ha convertido en una herramienta poderosa para el procesamiento del lenguaje natural, superando significativamente a los modelos de lenguaje tradicionales.
-
Ajuste Fino (Fine-tuning) en BERT
El ajuste fino es un proceso crucial en la utilización de modelos de lenguaje como BERT (Bidirectional Encoder Representations from Transformers) para tareas específicas. A continuación, se detalla este proceso de manera comprensible para principiantes, incorporando imágenes que faciliten la comprensión.
Proceso de Inicialización del Modelo Pre-entrenado con Parámetros Específicos
El primer paso en el ajuste fino es la inicialización del modelo pre-entrenado. BERT es pre-entrenado en una gran cantidad de texto no etiquetado utilizando dos tareas: el Modelo de Lenguaje enmascarado (Masked Language Model, MLM) y la Predicción de la siguiente oración (Next Sentence Prediction, NSP). Este pre-entrenamiento proporciona al modelo una comprensión general del lenguaje. Para ajustarlo a una tarea específica, inicializamos BERT con estos parámetros pre-entrenados.
Ajuste Fino Utilizando Datos Etiquetados de Tareas Específicas
Una vez que el modelo está inicializado con los parámetros pre-entrenados, el siguiente paso es el ajuste fino. Este proceso implica entrenar el modelo utilizando datos etiquetados específicos de la tarea a realizar. Durante el ajuste fino, se realizan pequeñas actualizaciones a los parámetros del modelo para que aprenda a realizar la tarea específica de manera eficaz.
Proceso de Ajuste Fino:
1. Carga del Modelo Pre-entrenado: Se carga el modelo BERT pre-entrenado.
2. Adición de una Capa de Salida: Se agrega una capa de salida específica para la tarea (por ejemplo, una capa de clasificación para el análisis de sentimientos).
3. Entrenamiento con Datos Etiquetados: Se entrena el modelo con los datos etiquetados específicos de la tarea. Este proceso puede implicar el uso de técnicas como el aprendizaje supervisado.
4. Ajuste de Parámetros: Durante el entrenamiento, los parámetros del modelo se ajustan ligeramente para optimizar el rendimiento en la tarea específica.
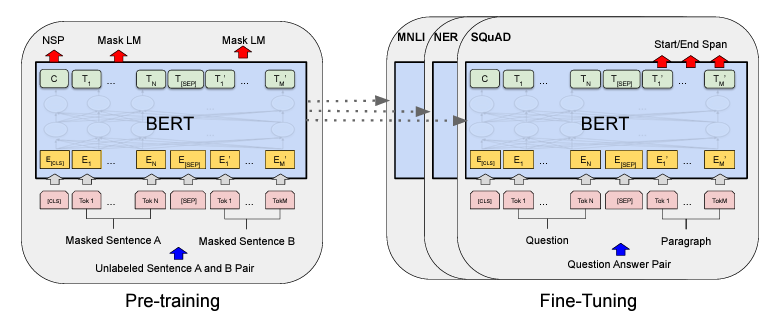
En general, los procedimientos de preentrenamiento y ajuste fino para BERT son los mismos. Aparte de las capas de salida, se utilizan las mismas arquitecturas tanto en el preentrenamiento como en el ajuste fino. Los mismos parámetros del modelo preentrenado se utilizan para inicializar los modelos para diferentes tareas downstream. Durante el ajuste fino, todos los parámetros se ajustan. [CLS] es un símbolo especial añadido al principio de cada ejemplo de entrada, y [SEP] es un token separador especial (por ejemplo, separando preguntas/respuestas).
Ejemplos de Tareas Downstream
Las tareas downstream son tareas específicas para las que se ajusta finamente el modelo BERT. Algunos ejemplos comunes incluyen:
Question Answering (QA)
El question answering es una tarea en la que el modelo debe responder preguntas basadas en un contexto dado. En esta tarea, se proporciona un párrafo de texto y una pregunta relacionada con ese texto. El modelo debe identificar la respuesta dentro del párrafo.
Ejemplo de Proceso de QA:
1. Contexto: Un párrafo de texto.
2. Pregunta: Una pregunta relacionada con el contenido del párrafo.
3. Respuesta: El modelo identifica la respuesta dentro del párrafo.
Análisis de Sentimientos
En el análisis de sentimientos, el modelo clasifica un texto en categorías como positivo, negativo o neutral. Este tipo de tarea es útil en aplicaciones como el análisis de opiniones en redes sociales.
Clasificación de Texto
La clasificación de texto implica asignar etiquetas a fragmentos de texto. Por ejemplo, clasificar correos electrónicos como spam o no spam.
Reconocimiento de Entidades Nombradas (NER)
En NER, el modelo identifica y clasifica entidades mencionadas en un texto en categorías predefinidas, como nombres de personas, organizaciones o ubicaciones.
En resumen, el ajuste fino de BERT permite adaptar un modelo pre-entrenado a tareas específicas utilizando datos etiquetados. Este proceso es esencial para obtener un alto rendimiento en aplicaciones prácticas como el question answering, el análisis de sentimientos y la clasificación de texto. Con una comprensión adecuada del ajuste fino, los modelos de lenguaje como BERT pueden ser herramientas poderosas en una amplia gama de aplicaciones de procesamiento de lenguaje natural.
-
Resultados y Evaluación
En este artículo, exploraremos cómo BERT se desempeña en diferentes tareas de NLP, comparándolo con otros modelos y benchmarks, y analizando la interpretación de los resultados obtenidos en diversos experimentos.
Rendimiento del modelo BERT en diferentes tareas de NLP
BERT ha demostrado ser altamente efectivo en una amplia gama de tareas NLP, tales como clasificación de texto, extracción de entidades, y respuesta a preguntas, entre otras. Su capacidad para capturar el contexto bidireccional y su entrenamiento en grandes corpus de texto lo posicionan como uno de los modelos más versátiles y precisos en NLP contemporáneo.
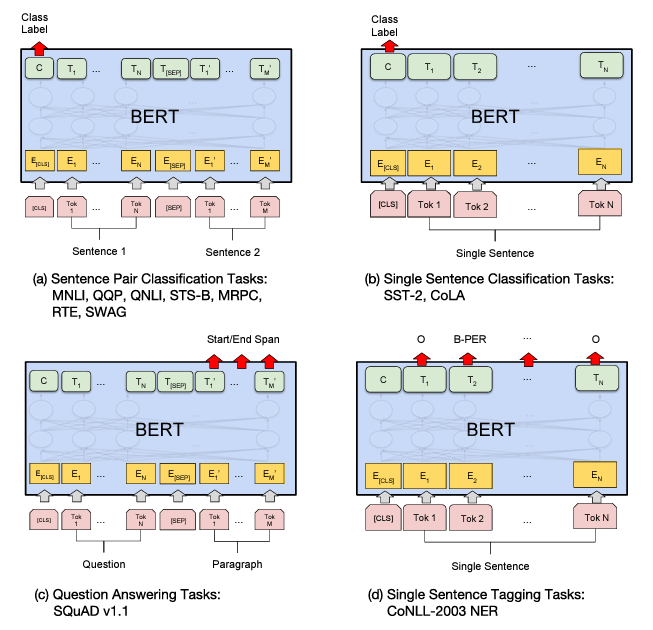
Ilustracion de Fine-tunning en diferentes tareas de BERT.
Comparaciones con otros modelos y benchmarks
Comparado con modelos previos como Word2Vec y GloVe, BERT ha superado consistentemente en una variedad de métricas de evaluación. En benchmarks estándar como GLUE (General Language Understanding Evaluation) y SQuAD (Stanford Question Answering Dataset), BERT ha establecido nuevos récords en términos de precisión y velocidad de entrenamiento, demostrando su superioridad en la comprensión del lenguaje natural.
Interpretación de los resultados obtenidos en los experimentos
Los experimentos muestran que la arquitectura Transformer de BERT permite una representación semántica profunda y precisa del texto, lo que mejora significativamente la capacidad del modelo para capturar matices lingüísticos y contextuales. La interpretación de estos resultados subraya la eficacia de BERT en la comprensión del lenguaje natural y su capacidad para generalizar en una amplia variedad de dominios y tareas.
Enlace Adicional
para más información, visite este sitio.
-
 Campus
Campus
