Entrenamiento del Modelo Transformer
Los modelos Transformer han revolucionado el campo del procesamiento del lenguaje natural (NLP) y otras áreas del aprendizaje automático gracias a su capacidad para manejar dependencias a largo plazo y procesar datos en paralelo de manera eficiente. El entrenamiento de estos modelos es un proceso complejo que involucra la optimización de una función de pérdida y, a menudo, el uso de métodos de pre-entrenamiento. En este texto, exploraremos detalladamente el objetivo del entrenamiento de los Transformers y los métodos de pre-entrenamiento más comunes.

Objetivo de Entrenamiento (Training Objective)
El objetivo del entrenamiento de un modelo Transformer es ajustar sus parámetros para minimizar una función de pérdida específica. Esta función de pérdida mide la discrepancia entre las predicciones del modelo y las respuestas correctas. El proceso de entrenamiento se realiza mediante la optimización iterativa de los pesos del modelo utilizando algoritmos como el descenso de gradiente estocástico (SGD) y sus variantes.
1. Función de Pérdida: En el contexto de los Transformers, la función de pérdida más comúnmente utilizada es la entropía cruzada (cross-entropy loss). Esta función mide la diferencia entre la distribución de probabilidad predicha por el modelo y la distribución de probabilidad verdadera. Matemáticamente, la entropía cruzada se define como:
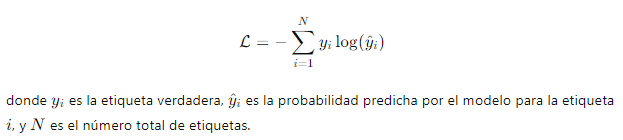
2. Ajuste de Parámetros: El proceso de ajuste de parámetros implica actualizar los pesos del modelo para minimizar la función de pérdida. Esto se logra mediante la retropropagación del error y la actualización de los pesos utilizando algoritmos de optimización como Adam o RMSprop.
Métodos de Pre-Entrenamiento
El pre-entrenamiento es una etapa crucial en el desarrollo de modelos Transformer, ya que permite al modelo aprender representaciones generales del lenguaje a partir de grandes cantidades de datos no etiquetados. Existen varios enfoques de pre-entrenamiento que han demostrado ser altamente efectivos:
1. Modelado de Lenguaje enmascarado (Masked Language Modeling, MLM):
- Descripción: En este enfoque, algunas palabras del texto de entrada se enmascaran aleatoriamente, y el objetivo del modelo es predecir las palabras enmascaradas basándose en el contexto circundante. Este método ayuda al modelo a aprender relaciones contextuales y representaciones semánticas profundas.
- Ejemplo: En el modelo BERT, aproximadamente el 15% de las palabras en cada secuencia de entrada se enmascaran, y el modelo se entrena para predecir estas palabras enmascaradas.
2. Pre-Entrenamiento de Secuencia a Secuencia (Sequence-to-Sequence Pre-Training):
- Descripción: Este enfoque implica entrenar el modelo para convertir una secuencia de entrada en una secuencia de salida. Es particularmente útil para tareas como la traducción automática y la generación de texto. El modelo se entrena en grandes conjuntos de datos de pares de secuencias de entrada y salida.
- Ejemplo: El modelo T5 se entrena utilizando un enfoque de secuencia a secuencia, donde cada tarea se formula como una transformación de texto, permitiendo al modelo aprender una variedad de tareas de NLP de manera unificada.
Importancia del Pre-Entrenamiento
El pre-entrenamiento de los modelos Transformer tiene varias ventajas significativas:
1. Mejora del Rendimiento: Los modelos pre-entrenados en grandes cantidades de datos no etiquetados suelen mostrar un mejor rendimiento en tareas específicas después de un ajuste fino (fine-tuning) en conjuntos de datos etiquetados más pequeños.
2. Eficiencia de Datos: El pre-entrenamiento permite que los modelos aprendan representaciones útiles del lenguaje con menos datos etiquetados, lo que es especialmente beneficioso en situaciones donde los datos etiquetados son escasos o costosos de obtener.
3. Transferencia de Conocimientos: Los modelos pre-entrenados pueden transferir conocimientos aprendidos en una tarea a otras tareas relacionadas, mejorando la eficiencia y eficacia del aprendizaje en múltiples dominios.
En resumen, el entrenamiento y pre-entrenamiento de los modelos Transformer son procesos fundamentales que permiten a estos modelos aprender representaciones ricas y generalizables del lenguaje. A través de la optimización de la función de pérdida y el uso de técnicas avanzadas de pre-entrenamiento, los Transformers han demostrado ser extremadamente eficaces en una amplia gama de aplicaciones de procesamiento del lenguaje natural.
 Campus
Campus
 Campus
Campus
