Detalles del Procesamiento en Capas
Pasos del Procesamiento en Capas
El Transformador consta de dos partes principales: el codificador (encoder) y el decodificador (decoder). En este texto, nos enfocaremos en el codificador, ya que los principios del procesamiento en capas son similares en ambas partes.
1. Entrada y Embedding:
Entrada: Los datos de entrada son secuencias de tokens, que representan palabras o subpalabras.
Embedding: Cada token se convierte en un vector de dimensiones fijas mediante una capa de embedding. Además, se añade información de posición mediante embeddings posicionales, ya que los Transformadores no tienen una noción inherente de orden.
2. Capa de Atención Multi-Cabeza (Multi-Head Attention):
Atención Escalonada (Scaled Dot-Product Attention): Cada token en la secuencia calcula su atención sobre todos los demás tokens, creando una representación ponderada. La fórmula es:
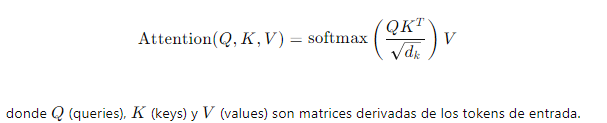
3. Capa de Normalización y Residual:
- Conexión Residual: La salida de la atención multi-cabeza se suma a la entrada original del bloque de atención, ayudando a mitigar el problema del desvanecimiento del gradiente.
- Normalización por Batch (Layer Normalization): Se aplica normalización por batch a la suma resultante para estabilizar y acelerar el entrenamiento.
4. Capa Feed-Forward:
- Red Neuronal Feed-Forward: Se aplica una red neuronal totalmente conectada de dos capas a cada posición del embedding de manera independiente y en paralelo. La función de activación es típicamente ReLU.
- Normalización y Residual: Similar al bloque de atención, se añade una conexión residual y normalización por batch después del paso feed-forward.
5. Repetición del Bloque: Este bloque de procesamiento (atención multi-cabeza y feed-forward) se repite varias veces en la red del codificador. Cada capa sucesiva refina y abstrae las representaciones de las capas anteriores.
Evolución del Estado Oculto (Hidden State Evolution)
El estado oculto de un Transformador es la representación interna de los tokens de entrada que evoluciona a medida que pasan por las capas del modelo. A continuación se detalla este proceso:
1. Inicialización: Al inicio, los embeddings de los tokens de entrada (junto con los embeddings posicionales) forman el estado oculto inicial. Este estado contiene la información inicial sobre las posiciones y las relaciones básicas entre los tokens.
2. Paso a Través de la Atención Multi-Cabeza: En cada capa de atención multi-cabeza, los estados ocultos se actualizan mediante la combinación ponderada de todos los estados ocultos anteriores. Esto permite que cada token incorpore información de todos los otros tokens en la secuencia, capturando relaciones a largo plazo.
3. Paso a Través de la Red Feed-Forward: Después de la atención, los estados ocultos se pasan a través de una red feed-forward que aplica una transformación no lineal. Esta etapa refina las representaciones y permite al modelo capturar interacciones más complejas.
4. Evolución a lo Largo de las Capas: A medida que los estados ocultos pasan por múltiples capas del Transformador, se vuelven progresivamente más abstractos. Las primeras capas pueden capturar características locales y sintácticas, mientras que las capas más profundas pueden capturar relaciones semánticas y contextuales más complejas.
En resumen, los Transformadores representan un avance significativo en el procesamiento del lenguaje natural y otras tareas de secuencia debido a su capacidad para capturar dependencias a largo plazo y manejar grandes volúmenes de datos en paralelo. La estructura en capas y el uso de mecanismos de atención permiten a los Transformadores aprender representaciones jerárquicas y contextuales profundas. La evolución del estado oculto a través de estas capas es fundamental para su capacidad de generalización y rendimiento superior en diversas aplicaciones.
Enlace Adicional
Para más información, vista este sitio.
 Campus
Campus
 Campus
Campus
