Mecanismo de Atención
Los Transformers han revolucionado el campo del procesamiento del lenguaje natural (NLP) y otras áreas del aprendizaje automático debido a su capacidad para manejar dependencias a largo plazo en las secuencias de datos. Introducidos por Vaswani et al. en 2017, los Transformers utilizan un mecanismo de atención que permite al modelo enfocarse en diferentes partes de la entrada de manera flexible y eficiente. En este texto, exploraremos en detalle el mecanismo de atención, específicamente la Atención Escalada (Scaled Dot-Product Attention) y la Atención Máscara (Masked Multi-Head Attention), y cómo se aplican en el modelo Transformer.
Mecanismo de Atención
El mecanismo de atención es un componente clave del Transformer que permite al modelo asignar diferentes pesos a diferentes partes de la entrada, permitiendo un enfoque más dinámico y adaptativo. Este mecanismo se implementa a través de dos variantes importantes: la Atención Escalada y la Atención Máscara.
Atención Escalada (Scaled Dot-Product Attention)
La Atención Escalada (Scaled Dot-Product Attention) es un método para calcular la atención entre elementos en una secuencia. Consiste en los siguientes pasos:
1. Cálculo de Puntajes de Atención: Se calculan los puntajes de atención utilizando el producto punto entre las matrices de consulta (Q) y las matrices de clave (K). La fórmula es:
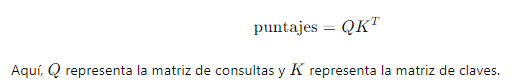
2. Escalado de Puntajes: Para estabilizar los gradientes y mejorar la eficiencia del entrenamiento, los puntajes de atención se escalan dividiendo por la raíz cuadrada de la dimensión de las claves ():
3. Aplicación de Softmax: Se aplica la función softmax a los puntajes escalados para obtener los pesos de atención, que representan la importancia relativa de cada elemento en la secuencia:
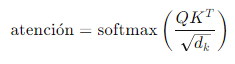
4. Cálculo de la Salida: Finalmente, los pesos de atención se utilizan para ponderar las matrices de valor (V) y obtener la salida de la atención:
salida=atención ⋅ V
Atención Máscara (Masked Multi-Head Attention)
La Atención Máscara (Masked Multi-Head Attention) es una extensión del mecanismo de atención utilizada en tareas donde es importante ocultar posiciones futuras en una secuencia, como en la generación de texto.
1. Máscara de Atención: Se aplica una máscara a los puntajes de atención para asegurarse de que las posiciones futuras no sean consideradas. Esto se hace estableciendo los puntajes de las posiciones futuras a antes de aplicar la función softmax:
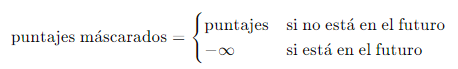
2. Atención Multi-Cabeza: El Transformer utiliza múltiples cabezas de atención para capturar diferentes tipos de dependencias en los datos. Cada cabeza realiza el cálculo de la atención de manera independiente y sus resultados se concatenan y se combinan linealmente para producir la salida final:

Importancia de la Atención Escalada y la Atención Máscara
El uso de la atención escalada permite al modelo asignar diferentes niveles de importancia a diferentes partes de la entrada, mejorando la capacidad del Transformer para manejar dependencias a largo plazo y capturar patrones complejos en los datos. La atención máscara es crucial en tareas secuenciales, como la generación de texto, donde es importante asegurar que las predicciones se basen únicamente en información pasada o presente y no en información futura.
En resumen, el mecanismo de atención es fundamental para el éxito de los Transformers, permitiendo una mayor flexibilidad y capacidad de adaptación en el procesamiento de secuencias. La Atención Escalada y la Atención Máscara son dos componentes esenciales que permiten a los Transformers manejar eficientemente las dependencias a largo plazo y las tareas secuenciales, respectivamente.
Enlace Adicional
Para más información, visite este sitio.
 Campus
Campus
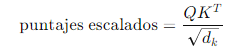
 Campus
Campus
