 Campus
Campus
Diagrama de temas
-
-
Arquitectura Transformers
Introducción a los Transformers
La arquitectura Transformer ha revolucionado el campo de la inteligencia artificial, especialmente en el procesamiento del lenguaje natural (NLP). Introducida por Vaswani et al. en el artículo "Attention is All You Need" en 2017, los Transformers han superado muchas de las limitaciones de las redes neuronales recurrentes (RNNs) y las redes de memoria a largo plazo (LSTMs), ofreciendo una alternativa más eficiente y efectiva para una amplia gama de tareas.
Descripción General de los Transformers
Los Transformers se basan en un mecanismo de atención que permite procesar secuencias de datos de manera no recurrente, es decir, sin necesidad de procesar los datos en un orden secuencial estricto. Esto les permite manejar dependencias a largo plazo de manera más efectiva que las RNNs y LSTMs.
- Mecanismo de Atención: El núcleo de los Transformers es el mecanismo de atención, que asigna diferentes pesos a diferentes partes de la secuencia de entrada para enfocarse en las partes más relevantes. Este mecanismo es altamente paralelo, lo que permite entrenar modelos más grandes y complejos de manera eficiente.- Estructura de Encoder-Decoder: Los Transformers tienen una arquitectura de encoder-decoder. El encoder procesa la entrada y crea una representación interna, mientras que el decoder genera la salida basándose en esta representación. Ambos componentes utilizan múltiples capas de atención y capas feed-forward.Problemas con RNNs y LSTMs
Antes de la introducción de los Transformers, las RNNs y LSTMs eran las arquitecturas predominantes para tareas de secuencia a secuencia en NLP. Sin embargo, estas arquitecturas tienen varias limitaciones:
- Procesamiento Secuencial: Las RNNs y LSTMs procesan las secuencias de entrada de manera secuencial, lo que dificulta la paralelización y hace que el entrenamiento sea lento y costoso.
- Dependencias a Largo Plazo: Aunque las LSTMs están diseñadas para manejar dependencias a largo plazo mejor que las RNNs estándar, todavía tienen dificultades para capturar relaciones muy distantes en secuencias largas.
- Desvanecimiento y Explosión del Gradiente: Las RNNs sufren de problemas de desvanecimiento y explosión del gradiente, lo que afecta negativamente el proceso de aprendizaje y limita la capacidad de los modelos para aprender patrones a largo plazo.
Cómo los Transformers Abordan estos Desafíos
Los Transformers abordan las limitaciones de las RNNs y LSTMs de las siguientes maneras:
- Paralelización: Al procesar todas las posiciones de la secuencia de entrada simultáneamente, los Transformers permiten una paralelización efectiva, acelerando significativamente el entrenamiento.
- Atención Multi-Cabeza: Los Transformers utilizan atención multi-cabeza para capturar diferentes tipos de relaciones en la secuencia de entrada. Cada "cabeza" de atención se enfoca en diferentes partes de la secuencia, lo que permite al modelo aprender patrones más complejos y variados.
- Sin Desvanecimiento del Gradiente: Al eliminar la recurrencia, los Transformers evitan los problemas de desvanecimiento y explosión del gradiente, facilitando un entrenamiento más estable y eficiente.
- Representación Posicional: Aunque los Transformers no procesan las secuencias en orden, utilizan codificaciones posicionales para mantener información sobre la posición relativa de los tokens en la secuencia. Esto permite al modelo comprender el orden de los elementos en la entrada.
En resumen, los Transformers han cambiado radicalmente el enfoque hacia el procesamiento de secuencias en NLP, superando las limitaciones de las RNNs y LSTMs con su capacidad de paralelización y su eficaz manejo de dependencias a largo plazo. La introducción del mecanismo de atención ha permitido a los modelos Transformer alcanzar resultados impresionantes en una amplia variedad de tareas, estableciendo nuevos estándares en el campo de la inteligencia artificial.
-
Componentes del Modelo Transformer
El modelo Transformer ha revolucionado el campo del procesamiento del lenguaje natural (NLP) y otras áreas del aprendizaje automático. Introducido por Vaswani et al. en 2017, los Transformers eliminan la necesidad de recurrencias y convoluciones, utilizando en su lugar mecanismos de atención para procesar las secuencias de datos. Esta arquitectura ha demostrado ser altamente eficiente y escalable, convirtiéndose en la base de muchos modelos de lenguaje avanzados como BERT, GPT y T5. En este texto, exploraremos detalladamente los componentes clave del modelo Transformer: el codificador (encoder), el decodificador (decoder), la atención multi-cabeza (multi-head attention) y las normalizaciones y conexiones residuales.
Codificador (Encoder)
El codificador es una de las dos partes principales de la arquitectura Transformer. Su función principal es procesar la entrada y generar una representación codificada que el decodificador puede utilizar.
Estructura y Funcionamiento del Codificador
El codificador del Transformer está compuesto por una pila de capas idénticas, cada una de las cuales contiene dos subcapas principales: una capa de atención multi-cabeza y una capa de red neuronal feed-forward completamente conectada. Cada una de estas subcapas está rodeada por una capa de normalización y conexiones residuales.
1. Capa de Atención Multi-Cabeza: Esta subcapa aplica múltiples mecanismos de atención en paralelo, permitiendo que el modelo se enfoque en diferentes partes de la secuencia de entrada simultáneamente.
2. Capa Feed-Forward: Después de la atención, los datos pasan por una red neuronal feed-forward que se aplica de manera independiente a cada posición.
3. Normalización y Conexiones Residuales: Cada una de las subcapas está seguida por una capa de normalización y una conexión residual, lo que facilita el entrenamiento del modelo y mejora la estabilidad.
Decodificador (Decoder)
El decodificador es la otra parte principal de la arquitectura Transformer, responsable de generar la salida secuencialmente utilizando la representación codificada del codificador.
Funciones y Estructura del Decodificador
Al igual que el codificador, el decodificador también está compuesto por una pila de capas idénticas, cada una con tres subcapas: una capa de atención multi-cabeza que se enfoca en la salida generada hasta ese momento, una capa de atención multi-cabeza que se enfoca en la salida del codificador, y una capa feed-forward.
1. Capa de Atención Enfocada en la Salida: Esta subcapa aplica atención a la salida generada hasta el momento, ayudando al modelo a considerar el contexto de la secuencia generada.
2. Capa de Atención Enfocada en el Codificador: Esta subcapa aplica atención a la representación codificada proveniente del codificador, integrando información de la entrada.
3. Capa Feed-Forward: Similar a la del codificador, esta capa aplica una red feed-forward a cada posición.
4. Normalización y Conexiones Residuales: Cada subcapa del decodificador también está rodeada por una capa de normalización y conexiones residuales.
Atención Multi-Cabeza (Multi-Head Attention)
El mecanismo de atención multi-cabeza es uno de los componentes más innovadores y esenciales del Transformer.
Desglose del Mecanismo de Atención
La atención multi-cabeza permite al modelo enfocarse en diferentes partes de la secuencia de entrada simultáneamente, lo que mejora significativamente la capacidad del modelo para capturar relaciones complejas en los datos.
1. Cálculo de Atención: Cada cabeza de atención realiza tres operaciones principales: Query (Q), Key (K) y Value (V). Estas operaciones permiten calcular una ponderación de atención que indica la importancia de cada parte de la secuencia de entrada.
2. Paralelización: Múltiples cabezas de atención trabajan en paralelo, cada una enfocándose en diferentes aspectos de la secuencia de entrada.
3. Concatenación y Proyección: Las salidas de todas las cabezas de atención se concatenan y pasan por una capa de proyección lineal para obtener la salida final.
Normalización y Conexiones Residuales
Las capas de normalización y las conexiones residuales son componentes clave para estabilizar y facilitar el entrenamiento del Transformer.
Papel de la Normalización de Capas
Normalización de Capas: La normalización de capas ayuda a estandarizar las salidas de cada subcapa, lo que facilita el flujo de gradientes durante el entrenamiento y mejora la estabilidad del modelo.
Conexiones Residuales: Las conexiones residuales permiten que la información original de la entrada se sume a la salida de la subcapa, lo que ayuda a mitigar el problema de la desaparición del gradiente y facilita el entrenamiento de redes profundas.
En resumen,los componentes del Transformer, incluyendo el codificador, el decodificador, la atención multi-cabeza y las normalizaciones y conexiones residuales, trabajan juntos para formar una arquitectura poderosa y flexible. Esta arquitectura ha demostrado ser altamente efectiva en una variedad de tareas de procesamiento de lenguaje natural y ha establecido nuevos estándares en el campo. La comprensión detallada de estos componentes es esencial para aprovechar al máximo las capacidades de los modelos Transformer.
Enlace Adicional
Para más información, visita este sitio.
-
Mecanismo de Atención
Los Transformers han revolucionado el campo del procesamiento del lenguaje natural (NLP) y otras áreas del aprendizaje automático debido a su capacidad para manejar dependencias a largo plazo en las secuencias de datos. Introducidos por Vaswani et al. en 2017, los Transformers utilizan un mecanismo de atención que permite al modelo enfocarse en diferentes partes de la entrada de manera flexible y eficiente. En este texto, exploraremos en detalle el mecanismo de atención, específicamente la Atención Escalada (Scaled Dot-Product Attention) y la Atención Máscara (Masked Multi-Head Attention), y cómo se aplican en el modelo Transformer.
Mecanismo de Atención
El mecanismo de atención es un componente clave del Transformer que permite al modelo asignar diferentes pesos a diferentes partes de la entrada, permitiendo un enfoque más dinámico y adaptativo. Este mecanismo se implementa a través de dos variantes importantes: la Atención Escalada y la Atención Máscara.
Atención Escalada (Scaled Dot-Product Attention)
La Atención Escalada (Scaled Dot-Product Attention) es un método para calcular la atención entre elementos en una secuencia. Consiste en los siguientes pasos:
1. Cálculo de Puntajes de Atención: Se calculan los puntajes de atención utilizando el producto punto entre las matrices de consulta (Q) y las matrices de clave (K). La fórmula es:
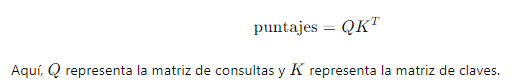
2. Escalado de Puntajes: Para estabilizar los gradientes y mejorar la eficiencia del entrenamiento, los puntajes de atención se escalan dividiendo por la raíz cuadrada de la dimensión de las claves ():
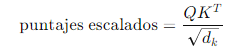
3. Aplicación de Softmax: Se aplica la función softmax a los puntajes escalados para obtener los pesos de atención, que representan la importancia relativa de cada elemento en la secuencia:
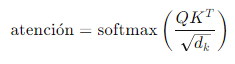
4. Cálculo de la Salida: Finalmente, los pesos de atención se utilizan para ponderar las matrices de valor (V) y obtener la salida de la atención:
salida=atención ⋅ V
Atención Máscara (Masked Multi-Head Attention)
La Atención Máscara (Masked Multi-Head Attention) es una extensión del mecanismo de atención utilizada en tareas donde es importante ocultar posiciones futuras en una secuencia, como en la generación de texto.
1. Máscara de Atención: Se aplica una máscara a los puntajes de atención para asegurarse de que las posiciones futuras no sean consideradas. Esto se hace estableciendo los puntajes de las posiciones futuras a antes de aplicar la función softmax:
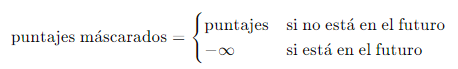
2. Atención Multi-Cabeza: El Transformer utiliza múltiples cabezas de atención para capturar diferentes tipos de dependencias en los datos. Cada cabeza realiza el cálculo de la atención de manera independiente y sus resultados se concatenan y se combinan linealmente para producir la salida final:

Importancia de la Atención Escalada y la Atención Máscara
El uso de la atención escalada permite al modelo asignar diferentes niveles de importancia a diferentes partes de la entrada, mejorando la capacidad del Transformer para manejar dependencias a largo plazo y capturar patrones complejos en los datos. La atención máscara es crucial en tareas secuenciales, como la generación de texto, donde es importante asegurar que las predicciones se basen únicamente en información pasada o presente y no en información futura.
En resumen, el mecanismo de atención es fundamental para el éxito de los Transformers, permitiendo una mayor flexibilidad y capacidad de adaptación en el procesamiento de secuencias. La Atención Escalada y la Atención Máscara son dos componentes esenciales que permiten a los Transformers manejar eficientemente las dependencias a largo plazo y las tareas secuenciales, respectivamente.
Enlace Adicional
Para más información, visite este sitio.
-
Codificación Posicional en Transformers
Los Transformers son una arquitectura de red neuronal que ha revolucionado el procesamiento del lenguaje natural (NLP) y otras tareas que requieren la manipulación de secuencias. Una característica clave de los Transformers es su capacidad para procesar secuencias enteras simultáneamente, en lugar de procesarlas elemento por elemento. Sin embargo, este enfoque introduce un desafío: la pérdida de información sobre el orden de las palabras. Para solucionar este problema, los Transformers emplean una técnica llamada codificación posicional (Positional Encoding).

Concepto y Necesidad de la Codificación Posicional
Concepto
La codificación posicional es una técnica utilizada para incorporar información sobre la posición de cada elemento en la secuencia dentro del modelo Transformer. Dado que los Transformers procesan todos los elementos de la secuencia en paralelo, no tienen una forma inherente de saber el orden de estos elementos. La codificación posicional resuelve este problema al añadir información sobre la posición relativa de cada palabra o elemento en la secuencia.
Necesidad
1. Preservar el Orden Secuencial: En tareas de NLP, el significado de una oración puede depender en gran medida del orden de las palabras. Sin una manera de representar este orden, los Transformers no podrían captar completamente el contexto y las relaciones entre las palabras.
2. Mejorar la Interpretación de Datos: La codificación posicional permite al modelo distinguir entre elementos que pueden tener el mismo valor pero que aparecen en diferentes posiciones, mejorando así la interpretación de la secuencia completa.
Implementación de la Codificación Posicional
La codificación posicional se implementa de manera que se suma directamente a las embeddings de las palabras antes de pasarlas a la capa de atención del Transformer. Aquí se describen los detalles de cómo se realiza esta implementación:
1. Fórmula Matemática: Las codificaciones posicionales se calculan utilizando funciones trigonométricas (seno y coseno) para cada posición pos en la secuencia y cada dimensión i en la embedding:

2.
Generación de Codificaciones: Para cada posición en la secuencia, se genera un vector de codificación posicional de la misma dimensión que las embeddings de las palabras. Este vector se suma a la embedding de la palabra correspondiente:
Embedding final=Embedding de palabra+Codificación posicional
3. Ejemplo Visual: En la imagen a continuación, se ilustra cómo las codificaciones posicionales se añaden a las embeddings de las palabras en una secuencia. Cada palabra en la entrada tiene una embedding y una codificación posicional correspondiente. Estas se suman para producir las embeddings finales que se pasan al Transformer.
En resumen, la codificación posicional es un componente esencial en los modelos Transformers, permitiendo que estos modelos mantengan la información de orden secuencial mientras procesan todas las posiciones simultáneamente. Al añadir codificaciones posicionales a las embeddings de las palabras, los Transformers pueden interpretar correctamente la estructura de las secuencias, lo que mejora significativamente su rendimiento en tareas de procesamiento del lenguaje natural y otras aplicaciones basadas en secuencias. -
Detalles del Procesamiento en Capas
Pasos del Procesamiento en Capas
El Transformador consta de dos partes principales: el codificador (encoder) y el decodificador (decoder). En este texto, nos enfocaremos en el codificador, ya que los principios del procesamiento en capas son similares en ambas partes.
1. Entrada y Embedding:
Entrada: Los datos de entrada son secuencias de tokens, que representan palabras o subpalabras.
Embedding: Cada token se convierte en un vector de dimensiones fijas mediante una capa de embedding. Además, se añade información de posición mediante embeddings posicionales, ya que los Transformadores no tienen una noción inherente de orden.
2. Capa de Atención Multi-Cabeza (Multi-Head Attention):
Atención Escalonada (Scaled Dot-Product Attention): Cada token en la secuencia calcula su atención sobre todos los demás tokens, creando una representación ponderada. La fórmula es:
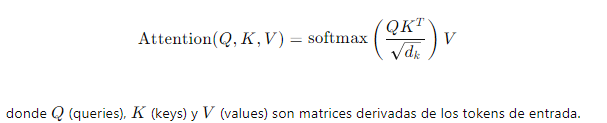 3. Capa de Normalización y Residual:- Conexión Residual: La salida de la atención multi-cabeza se suma a la entrada original del bloque de atención, ayudando a mitigar el problema del desvanecimiento del gradiente.- Normalización por Batch (Layer Normalization): Se aplica normalización por batch a la suma resultante para estabilizar y acelerar el entrenamiento.4. Capa Feed-Forward:- Red Neuronal Feed-Forward: Se aplica una red neuronal totalmente conectada de dos capas a cada posición del embedding de manera independiente y en paralelo. La función de activación es típicamente ReLU.- Normalización y Residual: Similar al bloque de atención, se añade una conexión residual y normalización por batch después del paso feed-forward.5. Repetición del Bloque: Este bloque de procesamiento (atención multi-cabeza y feed-forward) se repite varias veces en la red del codificador. Cada capa sucesiva refina y abstrae las representaciones de las capas anteriores.
3. Capa de Normalización y Residual:- Conexión Residual: La salida de la atención multi-cabeza se suma a la entrada original del bloque de atención, ayudando a mitigar el problema del desvanecimiento del gradiente.- Normalización por Batch (Layer Normalization): Se aplica normalización por batch a la suma resultante para estabilizar y acelerar el entrenamiento.4. Capa Feed-Forward:- Red Neuronal Feed-Forward: Se aplica una red neuronal totalmente conectada de dos capas a cada posición del embedding de manera independiente y en paralelo. La función de activación es típicamente ReLU.- Normalización y Residual: Similar al bloque de atención, se añade una conexión residual y normalización por batch después del paso feed-forward.5. Repetición del Bloque: Este bloque de procesamiento (atención multi-cabeza y feed-forward) se repite varias veces en la red del codificador. Cada capa sucesiva refina y abstrae las representaciones de las capas anteriores.Evolución del Estado Oculto (Hidden State Evolution)
El estado oculto de un Transformador es la representación interna de los tokens de entrada que evoluciona a medida que pasan por las capas del modelo. A continuación se detalla este proceso:1. Inicialización: Al inicio, los embeddings de los tokens de entrada (junto con los embeddings posicionales) forman el estado oculto inicial. Este estado contiene la información inicial sobre las posiciones y las relaciones básicas entre los tokens.
2. Paso a Través de la Atención Multi-Cabeza: En cada capa de atención multi-cabeza, los estados ocultos se actualizan mediante la combinación ponderada de todos los estados ocultos anteriores. Esto permite que cada token incorpore información de todos los otros tokens en la secuencia, capturando relaciones a largo plazo.
3. Paso a Través de la Red Feed-Forward: Después de la atención, los estados ocultos se pasan a través de una red feed-forward que aplica una transformación no lineal. Esta etapa refina las representaciones y permite al modelo capturar interacciones más complejas.
4. Evolución a lo Largo de las Capas: A medida que los estados ocultos pasan por múltiples capas del Transformador, se vuelven progresivamente más abstractos. Las primeras capas pueden capturar características locales y sintácticas, mientras que las capas más profundas pueden capturar relaciones semánticas y contextuales más complejas.
En resumen, los Transformadores representan un avance significativo en el procesamiento del lenguaje natural y otras tareas de secuencia debido a su capacidad para capturar dependencias a largo plazo y manejar grandes volúmenes de datos en paralelo. La estructura en capas y el uso de mecanismos de atención permiten a los Transformadores aprender representaciones jerárquicas y contextuales profundas. La evolución del estado oculto a través de estas capas es fundamental para su capacidad de generalización y rendimiento superior en diversas aplicaciones.Enlace Adicional
Para más información, vista este sitio.
-
Entrenamiento del Modelo Transformer
Los modelos Transformer han revolucionado el campo del procesamiento del lenguaje natural (NLP) y otras áreas del aprendizaje automático gracias a su capacidad para manejar dependencias a largo plazo y procesar datos en paralelo de manera eficiente. El entrenamiento de estos modelos es un proceso complejo que involucra la optimización de una función de pérdida y, a menudo, el uso de métodos de pre-entrenamiento. En este texto, exploraremos detalladamente el objetivo del entrenamiento de los Transformers y los métodos de pre-entrenamiento más comunes.

Objetivo de Entrenamiento (Training Objective)
El objetivo del entrenamiento de un modelo Transformer es ajustar sus parámetros para minimizar una función de pérdida específica. Esta función de pérdida mide la discrepancia entre las predicciones del modelo y las respuestas correctas. El proceso de entrenamiento se realiza mediante la optimización iterativa de los pesos del modelo utilizando algoritmos como el descenso de gradiente estocástico (SGD) y sus variantes.
1. Función de Pérdida: En el contexto de los Transformers, la función de pérdida más comúnmente utilizada es la entropía cruzada (cross-entropy loss). Esta función mide la diferencia entre la distribución de probabilidad predicha por el modelo y la distribución de probabilidad verdadera. Matemáticamente, la entropía cruzada se define como:
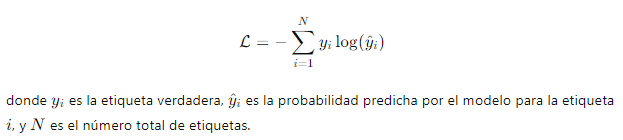
2. Ajuste de Parámetros: El proceso de ajuste de parámetros implica actualizar los pesos del modelo para minimizar la función de pérdida. Esto se logra mediante la retropropagación del error y la actualización de los pesos utilizando algoritmos de optimización como Adam o RMSprop.
Métodos de Pre-Entrenamiento
El pre-entrenamiento es una etapa crucial en el desarrollo de modelos Transformer, ya que permite al modelo aprender representaciones generales del lenguaje a partir de grandes cantidades de datos no etiquetados. Existen varios enfoques de pre-entrenamiento que han demostrado ser altamente efectivos:
1. Modelado de Lenguaje enmascarado (Masked Language Modeling, MLM):
- Descripción: En este enfoque, algunas palabras del texto de entrada se enmascaran aleatoriamente, y el objetivo del modelo es predecir las palabras enmascaradas basándose en el contexto circundante. Este método ayuda al modelo a aprender relaciones contextuales y representaciones semánticas profundas.
- Ejemplo: En el modelo BERT, aproximadamente el 15% de las palabras en cada secuencia de entrada se enmascaran, y el modelo se entrena para predecir estas palabras enmascaradas.
2. Pre-Entrenamiento de Secuencia a Secuencia (Sequence-to-Sequence Pre-Training):
- Descripción: Este enfoque implica entrenar el modelo para convertir una secuencia de entrada en una secuencia de salida. Es particularmente útil para tareas como la traducción automática y la generación de texto. El modelo se entrena en grandes conjuntos de datos de pares de secuencias de entrada y salida.
- Ejemplo: El modelo T5 se entrena utilizando un enfoque de secuencia a secuencia, donde cada tarea se formula como una transformación de texto, permitiendo al modelo aprender una variedad de tareas de NLP de manera unificada.
Importancia del Pre-Entrenamiento
El pre-entrenamiento de los modelos Transformer tiene varias ventajas significativas:
1. Mejora del Rendimiento: Los modelos pre-entrenados en grandes cantidades de datos no etiquetados suelen mostrar un mejor rendimiento en tareas específicas después de un ajuste fino (fine-tuning) en conjuntos de datos etiquetados más pequeños.
2. Eficiencia de Datos: El pre-entrenamiento permite que los modelos aprendan representaciones útiles del lenguaje con menos datos etiquetados, lo que es especialmente beneficioso en situaciones donde los datos etiquetados son escasos o costosos de obtener.
3. Transferencia de Conocimientos: Los modelos pre-entrenados pueden transferir conocimientos aprendidos en una tarea a otras tareas relacionadas, mejorando la eficiencia y eficacia del aprendizaje en múltiples dominios.
En resumen, el entrenamiento y pre-entrenamiento de los modelos Transformer son procesos fundamentales que permiten a estos modelos aprender representaciones ricas y generalizables del lenguaje. A través de la optimización de la función de pérdida y el uso de técnicas avanzadas de pre-entrenamiento, los Transformers han demostrado ser extremadamente eficaces en una amplia gama de aplicaciones de procesamiento del lenguaje natural.
-
Aplicaciones de los Transformers
Los Transformers han revolucionado diversas áreas de la inteligencia artificial, destacándose en el Procesamiento de Lenguaje Natural (NLP) y la Visión por Computadora (CV). A continuación, se presenta un análisis detallado de sus aplicaciones en ambos campos.
Transformers en Procesamiento de Lenguaje Natural (NLP)
Los Transformers han demostrado ser extremadamente efectivos en una amplia variedad de tareas de NLP. Estas tareas incluyen traducción automática, resumen de texto, generación de texto, y análisis de sentimientos, entre otras. A continuación, se describen algunos casos de uso y éxitos notables de los Transformers en NLP:
Casos de Uso en NLP
1. Traducción Automática:
- Google Translate: Utiliza modelos de Transformers para traducir texto de un idioma a otro con una precisión significativamente mejorada en comparación con los modelos anteriores.
- DeepL: Otra herramienta de traducción que ha adoptado Transformers, conocida por su alta calidad en la traducción de matices lingüísticos.
2. Generación de Texto:
GPT-3 de OpenAI: Es uno de los modelos más avanzados, capaz de generar texto coherente y relevante a partir de una entrada dada. Se ha utilizado en aplicaciones como chatbots, creación de contenido, y asistencia en redacción.
3. Resumen de Texto:
- BERT: Un modelo de Transformers desarrollado por Google, que se utiliza para resumir artículos largos y documentos, extrayendo las ideas principales de manera efectiva.
4. Análisis de Sentimientos:
Roberta: Un modelo derivado de BERT, que se ha empleado ampliamente en la clasificación de sentimientos en reseñas de productos, comentarios en redes sociales, y análisis de opiniones de clientes.
Éxitos en NLP
- BERT (Bidirectional Encoder Representations from Transformers): Ha establecido nuevos estándares de desempeño en tareas de comprensión del lenguaje natural, logrando resultados sin precedentes en benchmarks como GLUE y SQuAD.
- GPT-3 (Generative Pre-trained Transformer 3): Su capacidad para generar texto casi indistinguible del escrito por humanos ha abierto nuevas posibilidades en la automatización de tareas de redacción y generación de contenido.
Transformers en Visión por Computadora (CV)
Aunque los Transformers se desarrollaron inicialmente para NLP, su uso en Visión por Computadora (CV) ha ido en aumento, demostrando ser igualmente prometedores. A continuación, se exploran algunas de las aplicaciones emergentes de Transformers en CV:
Uso Emergente en CV
1. Detección de Objetos:
- DETR (Detection Transformer): Introducido por Facebook AI, este modelo emplea Transformers para detectar y localizar objetos en imágenes con gran precisión.
2. Clasificación de Imágenes:
- ViT (Vision Transformer): Un modelo que aplica la arquitectura de Transformers a imágenes, dividiéndolas en parches y tratándolos como una secuencia de palabras, logrando resultados competitivos en tareas de clasificación de imágenes.
3. Segmentación de Imágenes:
- SETR (Segmenter using Transformer): Utiliza Transformers para segmentar imágenes, es decir, identificar y delinear distintas regiones y objetos dentro de una imagen.
Aplicaciones y Éxitos en CV
- DETR (Detection Transformer): Ha demostrado un desempeño impresionante en la tarea de detección de objetos, simplificando la arquitectura tradicional de los detectores de objetos y ofreciendo una nueva perspectiva en la integración de Transformers en CV.
- ViT (Vision Transformer): Ha conseguido superar a los modelos de CNN tradicionales en varios benchmarks de clasificación de imágenes, mostrando el potencial de los Transformers para revolucionar el campo de la visión por computadora.
En resumen, los Transformers han mostrado una versatilidad impresionante, adaptándose exitosamente tanto a NLP como a CV. Sus aplicaciones continúan expandiéndose, demostrando su capacidad para manejar y resolver problemas complejos en diversas áreas de la inteligencia artificial. Con los avances continuos y la investigación en curso, es probable que los Transformers sigan desempeñando un papel crucial en el desarrollo de nuevas tecnologías y aplicaciones.
-
Comparación con Otras Arquitecturas
Comparativa con RNNs y LSTMs: Diferencias clave y ventajas de los Transformers sobre las redes recurrentes
Redes Neuronales Recurrentes (RNNs) y LSTMs (Long Short-Term Memory)
- Estructura: Las RNNs están diseñadas para procesar datos secuenciales, una entrada a la vez, manteniendo un estado oculto que se actualiza en cada paso. Las LSTMs son una mejora sobre las RNNs tradicionales que incluyen mecanismos para recordar información durante largos periodos y manejar el problema del desvanecimiento del gradiente.
- Ventajas:
Capacidad para manejar secuencias: Son efectivas para tareas que involucran datos secuenciales, como la traducción de idiomas y el análisis de series temporales.
Persistencia de la información: Las LSTMs pueden recordar información durante más pasos en la secuencia debido a su arquitectura de memoria especializada.
Transformers
- Estructura: Los Transformers utilizan una arquitectura de atención que permite procesar toda la secuencia de datos simultáneamente, sin necesidad de un estado oculto que se actualice secuencialmente.
- Ventajas:
- Paralelización: A diferencia de las RNNs y LSTMs, los Transformers permiten la paralelización del entrenamiento, lo que resulta en una mayor eficiencia computacional.
- Atención a largo plazo: Los mecanismos de atención permiten a los Transformers enfocarse en diferentes partes de la secuencia de entrada de manera directa y simultánea, mejorando el manejo de dependencias a largo plazo.
Comparativa Visual
1. RNN
- Procesamiento secuencial.
- Estado oculto que se actualiza paso a paso.
2. LSTM
- Incluye celdas de memoria para recordar información a largo plazo.
3. Transformer
- Procesamiento simultáneo de toda la secuencia.
- Mecanismo de atención que evalúa todas las partes de la secuencia en paralelo.
Comparativa con Redes Neuronales Convolucionales (CNNs): Ventajas de los Transformers en ciertas aplicaciones sobre las CNNs
Redes Neuronales Convolucionales (CNNs)
- Estructura: Las CNNs son adecuadas para el procesamiento de datos con estructura espacial, como imágenes y videos, utilizando capas convolucionales que aplican filtros para detectar características locales.
- Ventajas:
- Reconocimiento de patrones locales: Las CNNs son excelentes para tareas de reconocimiento de imágenes, donde la detección de características locales (bordes, texturas) es crucial.
- Invariancia a traslaciones: Los filtros convolucionales permiten que las CNNs sean invariantes a pequeñas traslaciones en la entrada.
Transformers
- Ventajas:
- Flexibilidad en la entrada: Los Transformers pueden manejar diferentes tipos de datos secuenciales y estructurados, no limitándose solo a imágenes.
- Atención global: Mientras que las CNNs se enfocan en características locales, los Transformers utilizan mecanismos de atención que consideran la totalidad de la entrada, lo que puede ser ventajoso para tareas donde las dependencias globales son importantes, como en el procesamiento del lenguaje natural.
Comparativa Visual
1. CNN
Enfoque en características locales mediante filtros convolucionales.
2. Transformer
Mecanismos de atención que consideran la entrada completa, proporcionando un enfoque global.
En resumen, los Transformers representan una evolución significativa en la arquitectura de redes neuronales, ofreciendo ventajas claras sobre las RNNs, LSTMs y CNNs en términos de paralelización, manejo de dependencias a largo plazo y flexibilidad en la entrada. Estas características hacen que los Transformers sean especialmente efectivos en aplicaciones de procesamiento del lenguaje natural y otras tareas que requieren un enfoque global en la entrada de datos.
-
Visualizaciones y Ejemplos Interactivos de Transformers
Explorables y Visualizaciones
Descripción de las Herramientas Visuales y Explorables
Los transformers son un tipo avanzado de modelo de inteligencia artificial que ha revolucionado el campo del procesamiento del lenguaje natural (NLP) y otras áreas. Para entender mejor su funcionamiento, existen diversas herramientas visuales y explorables que facilitan la comprensión de sus complejos mecanismos.
1. Visualización de la Arquitectura del Transformer:
- Componentes Principales: La arquitectura del transformer se compone de una pila de codificadores (encoders) y decodificadores (decoders). Cada codificador y decodificador contiene capas de auto-atención y capas feed-forward.
- Auto-Atención: Este mecanismo permite que el modelo preste atención a diferentes partes de la entrada para entender el contexto de cada palabra.
- Capas Feed-Forward: Estas son redes neuronales simples que procesan la salida de las capas de auto-atención.
Fuente: Jalammar's Illustrated Transformer
2. Mecanismo de Auto-Atención:
- Matrices de Atención: Estas matrices muestran cómo cada palabra en la secuencia de entrada influye en el procesamiento de las otras palabras.
- Escalamiento de Dot-Product: Para calcular la atención, se utiliza el producto punto entre las matrices de consulta (query) y clave (key), escalado por el tamaño de la dimensión de las claves.
3. Visualización de los Pesos de Atención:
Fuente: Jalammar's Illustrated Transformer- Interpretación de los Pesos: Los pesos de atención indican cuánta importancia se le da a cada palabra en la entrada cuando se está procesando una palabra particular.
- Mapas de Calor: Los mapas de calor (heatmaps) son útiles para visualizar estos pesos y entender cómo el modelo está tomando decisiones.
Ejemplos Prácticos
Casos Prácticos que Ilustran el Funcionamiento de los Transformers
Para entender mejor cómo funcionan los transformers, es útil ver algunos ejemplos prácticos que demuestran su aplicación en tareas reales.
1. Traducción de Lenguajes:- Entrada y Salida: El transformer toma una secuencia de palabras en un idioma y la traduce a otra secuencia de palabras en otro idioma.
- Proceso de Traducción: Utiliza las capas de codificación para entender el contexto del idioma fuente y las capas de decodificación para generar la traducción en el idioma objetivo.
2. Resumen de Textos:
- Entrada y Salida: El modelo recibe un texto largo como entrada y produce un resumen conciso del contenido.
- Mecanismo: Similar a la traducción, pero enfocado en capturar las ideas principales del texto y condensarlas.
3. Generación de Texto:- Entrada y Salida: A partir de una oración o frase inicial, el transformer puede generar texto continuado que sigue el estilo y contexto de la entrada.
- Aplicaciones: Útil para tareas como escritura asistida, generación de diálogos y creación de contenido.
En resumen, estas herramientas visuales y ejemplos prácticos son esenciales para comprender cómo funcionan los transformers y cómo pueden ser aplicados a diversos problemas del mundo real. A través de estas visualizaciones, se puede obtener una comprensión más profunda y tangible de los conceptos teóricos y prácticos de los transformers.
-
 Campus
Campus
