Regularización en Modelos No Lineales
La regularización es una técnica fundamental en el aprendizaje automático que se utiliza para prevenir el sobreajuste y mejorar la capacidad de generalización de los modelos. En los modelos no lineales, como las redes neuronales y las máquinas de soporte vectorial (SVM), la regularización desempeña un papel crucial en el control de la complejidad del modelo y en la mejora de su rendimiento en datos no vistos. En este texto, exploraremos diversas técnicas de regularización en deep learning, como el Dropout y el Early Stopping, así como la regularización en el espacio de características para las SVM.
Regularización en Redes Neuronales
Las redes neuronales son modelos altamente flexibles y potentes, pero también susceptibles al sobreajuste debido a su capacidad para modelar relaciones complejas en los datos. A continuación, se describen algunas técnicas de regularización comúnmente utilizadas en deep learning.
Técnicas de Regularización en Deep Learning
1. Regularización L2 (Decaimiento de Peso): Añade una penalización basada en la suma de los cuadrados de los pesos del modelo a la función de costo. Esto ayuda a mantener los pesos pequeños y evita que el modelo se ajuste demasiado a los datos de entrenamiento.
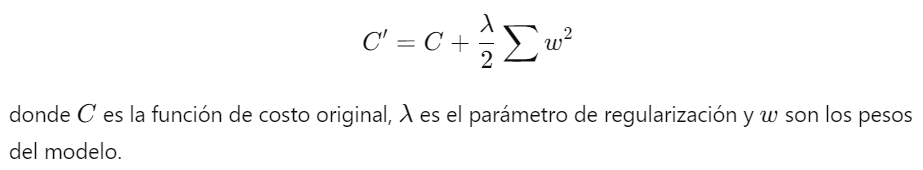
2. Regularización L1: Añade una penalización basada en la suma de los valores absolutos de los pesos. Esto puede llevar a la eliminación completa de algunos pesos, resultando en un modelo más esparso.
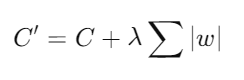
3. Dropout: Dropout es una técnica popular en la regularización de redes neuronales profundas.
Dropout: Definición y Funcionamiento
Dropout es una técnica de regularización que se utiliza para reducir el sobreajuste en redes neuronales al introducir ruido en la red durante el entrenamiento. El concepto principal de Dropout es desactivar (o "apagar") aleatoriamente un porcentaje de las neuronas en cada capa durante cada iteración de entrenamiento. Esto obliga a la red a aprender representaciones más robustas y a no depender excesivamente de ninguna neurona en particular.
- Definición: Dropout consiste en eliminar aleatoriamente un porcentaje de las neuronas de la red en cada paso de entrenamiento. Durante la fase de prueba, todas las neuronas están activas, pero sus salidas se escalonan por el factor de Dropout (por ejemplo, si el 50% de las neuronas se eliminan durante el entrenamiento, las salidas se escalan por 0.5 durante la prueba).
- Funcionamiento: En cada iteración de entrenamiento, se selecciona aleatoriamente un subconjunto de neuronas para desactivarlas. Las conexiones de estas neuronas no se utilizan en ese paso, y sus contribuciones a la activación y la retropropagación se omiten.
Early Stopping: Concepto y Aplicación
Early Stopping es otra técnica de regularización que detiene el entrenamiento de la red neuronal antes de que el modelo comience a sobreajustarse a los datos de entrenamiento. La idea es monitorear el rendimiento del modelo en un conjunto de validación durante el entrenamiento y detener el proceso cuando el rendimiento en el conjunto de validación deja de mejorar.
- Concepto: Early Stopping se basa en la observación del error de validación durante el entrenamiento. Cuando el error de validación comienza a aumentar mientras el error de entrenamiento sigue disminuyendo, indica que el modelo está comenzando a sobreajustarse.
- Aplicación: Se divide el conjunto de datos en un conjunto de entrenamiento y un conjunto de validación. Durante el entrenamiento, se monitorea el rendimiento del modelo en el conjunto de validación. Si el rendimiento no mejora después de un número determinado de iteraciones (patience), el entrenamiento se detiene.
Regularización en Máquinas de Soporte Vectorial (SVM)
Las Máquinas de Soporte Vectorial (SVM) son modelos poderosos para la clasificación y la regresión, especialmente efectivos en espacios de alta dimensión. La regularización es crucial en SVM para controlar la complejidad del modelo y mejorar su generalización.
Introducción a las SVM
Las SVM son modelos supervisados que buscan encontrar el hiperplano que mejor separa las clases en un espacio de características. El objetivo es maximizar el margen entre las muestras de las diferentes clases, lo que se traduce en un modelo más robusto y generalizable.
Regularización en el Espacio de Características
1. Regularización en SVM Lineales: En las SVM lineales, la regularización se incorpora en el término de margen suave, que permite que algunas muestras estén dentro del margen o en el lado incorrecto del hiperplano. La función de costo se define como:
2. Regularización en SVM no Lineales: En las SVM no lineales, el kernel trick se utiliza para mapear los datos a un espacio de características de mayor dimensión donde se puede aplicar la regularización de manera similar a las SVM lineales. La elección del kernel y su parámetro también actúan como formas de regularización.
En resumen, la regularización es una técnica esencial en el aprendizaje automático, especialmente en modelos no lineales como las redes neuronales y las SVM. Técnicas como Dropout y Early Stopping en deep learning y la regularización en el espacio de características en SVM ayudan a prevenir el sobreajuste y mejorar la capacidad de generalización de los modelos. Estas técnicas permiten a los modelos aprender representaciones más robustas y efectivas, mejorando su rendimiento en datos no vistos y asegurando su aplicabilidad en el mundo real.
Enlace Adicional
Para más Información, acceda a este documento.
 Campus
Campus
 2. Regularización en SVM no Lineales: En las SVM no lineales, el kernel trick se utiliza para mapear los datos a un espacio de características de mayor dimensión donde se puede aplicar la regularización de manera similar a las SVM lineales. La elección del kernel y su parámetro también actúan como formas de regularización.
2. Regularización en SVM no Lineales: En las SVM no lineales, el kernel trick se utiliza para mapear los datos a un espacio de características de mayor dimensión donde se puede aplicar la regularización de manera similar a las SVM lineales. La elección del kernel y su parámetro también actúan como formas de regularización. Campus
Campus
