Introducción
El sobreajuste (overfitting) es un problema común en el análisis de datos y el aprendizaje automático, donde un modelo aprende demasiado bien los detalles y el ruido del conjunto de datos de entrenamiento. Este exceso de ajuste reduce la capacidad del modelo para generalizar y desempeñarse bien en nuevos datos no vistos. La regularización es una técnica esencial para mitigar el sobreajuste y mejorar la generalización de los modelos.
Contexto del Overfitting en el Análisis de Datos
El overfitting ocurre cuando un modelo se entrena demasiado en un conjunto de datos particular, capturando no solo los patrones subyacentes relevantes, sino también las peculiaridades y el ruido específicos de ese conjunto de datos. Este fenómeno es especialmente problemático en modelos complejos con alta capacidad, como las redes neuronales profundas, que tienen millones de parámetros y pueden aprender prácticamente cualquier relación en los datos de entrenamiento, incluso las que no son generalizables.
1. Causas del Overfitting:
- Modelo Complejo: Los modelos con demasiados parámetros tienden a ajustarse demasiado a los datos de entrenamiento.
- Datos Insuficientes: Un conjunto de datos de entrenamiento pequeño puede llevar a un modelo a aprender patrones específicos del conjunto en lugar de patrones generales.
- Ruido en los Datos: La presencia de ruido y outliers en los datos de entrenamiento puede desviar el aprendizaje del modelo hacia relaciones irrelevantes.
2. Consecuencias del Overfitting:
- Rendimiento Degradado en Nuevos Datos: Un modelo sobreajustado generalmente muestra un rendimiento excelente en el conjunto de datos de entrenamiento, pero un rendimiento pobre en datos de prueba o nuevos datos.
- Generalización Deficiente: La incapacidad del modelo para generalizar se traduce en predicciones inexactas y una falta de robustez ante variaciones en los datos de entrada.
Importancia de la Regularización
La regularización es una técnica crítica para prevenir el sobreajuste y mejorar la capacidad de generalización de los modelos de aprendizaje automático. La regularización introduce una penalización por la complejidad del modelo, limitando la capacidad del modelo para ajustarse demasiado a los datos de entrenamiento.
1. Técnicas de Regularización:
- Regularización L2 (Ridge Regression): Esta técnica añade una penalización basada en la suma de los cuadrados de los pesos del modelo. Esto fuerza a los pesos a mantenerse pequeños, reduciendo la probabilidad de que el modelo se ajuste demasiado a los datos de entrenamiento.
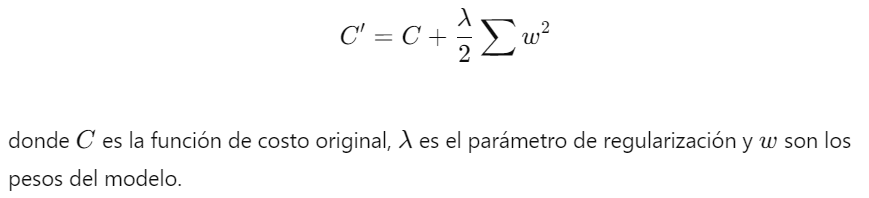
- Regularización L1 (Lasso Regression): Añade una penalización basada en la suma de los valores absolutos de los pesos. Esto puede llevar a la eliminación completa de algunos pesos, lo que resulta en un modelo más escaso.
- Dropout: Una técnica específica para redes neuronales que apaga aleatoriamente un porcentaje de neuronas durante el entrenamiento, forzando a la red a no depender excesivamente de ninguna neurona en particular.
2. Beneficios de la Regularización:
- Mejora de la Generalización: Al penalizar la complejidad del modelo, la regularización ayuda a los modelos a aprender patrones generales en lugar de detalles específicos del conjunto de datos de entrenamiento.
- Reducción de la Varianza: La regularización puede ayudar a reducir la varianza del modelo, haciendo que sus predicciones sean más consistentes y menos sensibles a pequeñas variaciones en los datos de entrada.
- Evita el Overfitting: Al controlar la magnitud de los parámetros del modelo, la regularización minimiza el riesgo de que el modelo se ajuste demasiado a los datos de entrenamiento, mejorando así su rendimiento en datos no vistos.
En resumen, el sobreajuste es un desafío significativo en el análisis de datos y el aprendizaje automático, que puede degradar seriamente el rendimiento de un modelo en datos nuevos. La regularización es una técnica esencial para mitigar este problema, mejorando la capacidad de generalización de los modelos y asegurando predicciones más robustas y precisas. Al aplicar regularización, los investigadores y practicantes pueden desarrollar modelos más fiables y efectivos, capaces de enfrentar mejor las complejidades y variaciones de los datos del mundo real.
Enlace Adicional
Para más Información, acceda a este documento.
 Campus
Campus
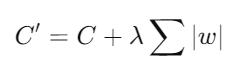
 Campus
Campus
