Redes Neuronales Recurrentes (RNN)
Las Redes Neuronales Recurrentes (RNN, por sus siglas en inglés) son una clase de redes neuronales diseñadas para manejar datos secuenciales, como series temporales, texto y datos de audio. A diferencia de las redes neuronales tradicionales, las RNN tienen conexiones recurrentes que permiten que la información persista, lo que las hace especialmente adecuadas para tareas donde el contexto y el orden de los datos son importantes. En este texto, exploraremos la estructura de las RNN y discutiremos algunos de los problemas comunes que enfrentan, como el desvanecimiento y el estallido del gradiente.
Estructura de las Redes Neuronales Recurrentes (RNN)
Las RNN están diseñadas para procesar secuencias de datos mediante la introducción de ciclos en la red que crean dependencias temporales. A continuación, se describen los componentes y el funcionamiento de las RNN:
1. Neurona Recurrente: A diferencia de las neuronas en las redes neuronales tradicionales, cada neurona en una RNN no solo recibe la entrada actual, sino también su propia salida anterior. Esto permite que la red mantenga un estado interno que puede capturar información a lo largo de la secuencia.
2. Estructura de la RNN: La estructura básica de una RNN se puede describir mediante la siguiente ecuación:
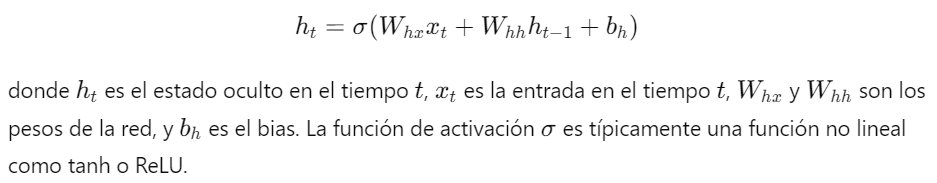
3. Salida de la RNN: La salida de la red en cada tiempo puede estar dada por:
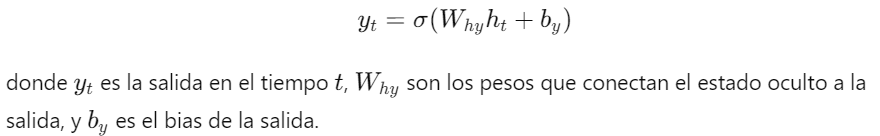
4. Backpropagation Through Time (BPTT): Para entrenar una RNN, se utiliza una variación del algoritmo de retropropagación llamada retropropagación a través del tiempo. Este algoritmo extiende el cálculo del gradiente a lo largo de toda la secuencia temporal.
Problemas Comunes en las RNN
Aunque las RNN son poderosas para manejar datos secuenciales, enfrentan varios desafíos durante el entrenamiento, entre los que destacan el desvanecimiento del gradiente y el estallido del gradiente.
1. Desvanecimiento del Gradiente (Vanishing Gradient):
- Descripción: El desvanecimiento del gradiente ocurre cuando los gradientes de la función de pérdida con respecto a los pesos se vuelven extremadamente pequeños a medida que se propagan hacia atrás en el tiempo. Esto puede hacer que las actualizaciones de los pesos sean insignificantes, impidiendo que la red aprenda dependencias a largo plazo.
- Causas: El uso de funciones de activación como la sigmoide o tanh puede exacerbar este problema debido a sus derivadas que se acercan a cero en sus extremos.
2. Estallido del Gradiente (Exploding Gradient):
- Descripción: El estallido del gradiente ocurre cuando los gradientes se vuelven extremadamente grandes durante la retropropagación. Esto puede hacer que los pesos se actualicen de manera abrupta, llevando a inestabilidad en el entrenamiento y posibles divergencias.
- Causas: Este problema es común cuando los gradientes se multiplican repetidamente a lo largo de muchas capas, lo que puede suceder en secuencias largas.
Soluciones a los Problemas de Gradiente
1. Uso de Funciones de Activación Adecuadas: El uso de funciones de activación como ReLU puede ayudar a mitigar el problema del desvanecimiento del gradiente.
2. Regularización y Normalización: Técnicas como la normalización por lotes (batch normalization) pueden ayudar a mantener los gradientes en un rango adecuado.
3. Clipping de Gradientes: El clipping de gradientes es una técnica que limita el tamaño de los gradientes para prevenir el estallido del gradiente. Consiste en establecer un umbral máximo para los gradientes y escalar los gradientes que exceden este umbral.
4. Redes LSTM y GRU: Las arquitecturas avanzadas como LSTM (Long Short-Term Memory) y GRU (Gated Recurrent Unit) están diseñadas específicamente para manejar el problema del desvanecimiento del gradiente al introducir puertas que controlan el flujo de información a través de la red.
En resumen, las Redes Neuronales Recurrentes (RNN) son una herramienta poderosa para procesar datos secuenciales, pero enfrentan desafíos significativos como el desvanecimiento y el estallido del gradiente. Comprender y abordar estos problemas es crucial para el entrenamiento efectivo de RNNs y para aprovechar todo su potencial en diversas aplicaciones de secuencias de datos.
 Campus
Campus
 Campus
Campus
