 Campus
Campus
Diagrama de temas
-
Redes Neuronales Convolucionales (CNN)
Las Redes Neuronales Convolucionales (CNN, por sus siglas en inglés) son una clase especial de redes neuronales diseñadas específicamente para procesar datos con una estructura de cuadrícula, como las imágenes. Las CNN han revolucionado el campo de la visión por computadora debido a su capacidad para capturar patrones espaciales y jerárquicos en las imágenes. Estas redes son ampliamente utilizadas en tareas como el reconocimiento de objetos, la segmentación de imágenes y la detección de rostros, entre otras aplicaciones.
Fundamentos de las Redes Neuronales Convolucionales (CNN)
Las CNN se inspiran en la organización de la corteza visual del cerebro humano y están diseñadas para procesar y reconocer patrones visuales directamente a partir de los datos en bruto. A continuación, se describen los componentes fundamentales y el funcionamiento de las CNN:
1. Estructura de las CNN: Una CNN típica está compuesta por una serie de capas, incluyendo capas convolucionales, capas de pooling (submuestreo) y capas completamente conectadas (fully connected). La combinación de estas capas permite a la red aprender representaciones jerárquicas de los datos de entrada.
2. Aprendizaje de Características: Las capas convolucionales actúan como detectores de características locales, capturando patrones simples como bordes y texturas en las primeras capas, y patrones más complejos como formas y objetos en capas más profundas.
3. Invariancia a Traslaciones: Gracias a la operación de pooling, las CNN pueden lograr invariancia a pequeñas traslaciones y distorsiones en los datos de entrada, lo que mejora la robustez del modelo.
Capas Convolucionales y de Pooling
Las capas convolucionales y de pooling son los componentes clave que permiten a las CNN procesar eficientemente los datos visuales.
Capas Convolucionales
1. Operación de Convolución: La operación de convolución es el núcleo de las capas convolucionales. Consiste en aplicar un filtro (también llamado kernel) sobre la entrada para producir un mapa de características. Matemáticamente, la convolución de una entrada I con un filtro K se expresa como:
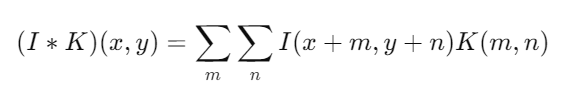
2. Mapas de Características: El resultado de la convolución es un conjunto de mapas de características que resaltan las activaciones del filtro en diferentes regiones de la imagen. Cada filtro aprende a detectar una característica específica.
3. Parámetros de la Convolución: Los parámetros importantes en la operación de convolución incluyen el tamaño del filtro, el stride (paso), que determina cuánto se desplaza el filtro sobre la entrada, y el padding (relleno), que controla cómo se manejan los bordes de la entrada.
Capas de Pooling
1. Operación de Pooling: La operación de pooling reduce la dimensionalidad de los mapas de características y retiene la información más importante. La técnica más común es el max-pooling, que selecciona el valor máximo en una ventana de tamaño fijo.
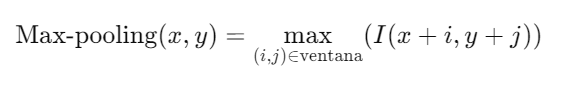
2. Propósito del Pooling: El pooling reduce la cantidad de parámetros y el costo computacional, además de proporcionar invariancia a pequeñas traslaciones en la entrada.
3. Tipos de Pooling: Además del max-pooling, otro tipo común es el average-pooling, que toma el promedio de los valores en la ventana de pooling.
Aplicaciones en Visión por Computadora
Las CNN han demostrado ser extremadamente eficaces en una variedad de tareas de visión por computadora, incluyendo:
1. Reconocimiento de Objetos: Identificación y clasificación de objetos dentro de imágenes.
2. Segmentación de Imágenes: División de una imagen en segmentos o regiones significativas.
3. Detección de Rostros: Localización y reconocimiento de rostros en imágenes y videos.
4. Análisis de Videos: Procesamiento de secuencias de imágenes para tareas como la detección de movimiento y el seguimiento de objetos.
En resumen, las Redes Neuronales Convolucionales (CNN) son una poderosa herramienta en el campo de la visión por computadora, gracias a su capacidad para aprender y reconocer patrones complejos en los datos visuales. Las operaciones de convolución y pooling permiten a las CNN extraer características jerárquicas e invariantes, lo que mejora significativamente su rendimiento en diversas aplicaciones.
 Campus
Campus
