Redes Neuronales Multicapa (MLP)
Las Redes Neuronales Multicapa, conocidas como MLP (Multilayer Perceptron), son un tipo fundamental de redes neuronales artificiales ampliamente utilizadas en el aprendizaje automático. Estas redes se caracterizan por su capacidad de aprender representaciones complejas de los datos mediante la utilización de múltiples capas de neuronas. En este texto, exploraremos la estructura de las MLP y el proceso de propagación hacia adelante, que es crucial para el cálculo de la salida de la red a partir de una entrada dada.
Estructura de las Redes Neuronales Multicapa (MLP)
Las MLP están compuestas por varias capas de neuronas que trabajan juntas para procesar y transformar los datos de entrada en salidas útiles. A continuación se describe la estructura de una MLP típica:
1. Capa de Entrada: Esta es la primera capa de la red y se encarga de recibir los datos de entrada. Cada neurona en la capa de entrada representa una característica del dato de entrada. Por ejemplo, en una red que procesa imágenes, cada píxel de la imagen puede ser una entrada.
2. Capas Ocultas: Las capas ocultas son las que se encuentran entre la capa de entrada y la capa de salida. Estas capas son responsables de realizar transformaciones complejas en los datos de entrada mediante la aplicación de funciones de activación no lineales. Las MLP pueden tener una o varias capas ocultas, y cada capa adicional aumenta la capacidad de la red para aprender representaciones más complejas.
- Neurona: Cada neurona en una capa oculta recibe una combinación ponderada de las salidas de las neuronas de la capa anterior.
- Pesos y Biases: Las conexiones entre las neuronas de diferentes capas están asociadas con pesos, y cada neurona tiene un bias que se suma antes de aplicar la función de activación.
3. Capa de Salida: La última capa de la red es la capa de salida, que produce la salida final de la MLP. El número de neuronas en la capa de salida depende del tipo de problema que se esté resolviendo. Por ejemplo, en un problema de clasificación binaria, habría una neurona de salida, mientras que en una clasificación multiclase, habría tantas neuronas como clases.
Propagación hacia Adelante
La propagación hacia adelante es el proceso mediante el cual una MLP calcula su salida a partir de una entrada dada. Este proceso implica pasar los datos de entrada a través de todas las capas de la red hasta obtener la salida final. Aquí se describe el proceso en detalle:
1. Cálculo en la Capa de Entrada: Los datos de entrada x se introducen en la red. Cada neurona de la capa de entrada simplemente pasa su valor a la primera capa oculta.
2. Cálculo en las Capas Ocultas:
- Suma Ponderada: Cada neurona j en una capa oculta recibe entradas xi de las neuronas de la capa anterior y calcula una suma ponderada:

- Función de Activación: La suma ponderada zj se pasa a través de una función de activación ϕ para producir la salida de la neurona j:
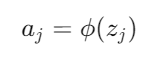
3. Cálculo en la Capa de Salida: El proceso se repite para todas las capas ocultas hasta llegar a la capa de salida. En la capa de salida, las neuronas realizan el mismo cálculo de suma ponderada y aplicación de la función de activación para producir la salida final de la red y.
Importancia de la Estructura y la Propagación hacia Adelante
La estructura de las MLP con múltiples capas ocultas permite a la red aprender características jerárquicas y representaciones complejas de los datos, lo que es crucial para tareas como la clasificación de imágenes, el procesamiento del lenguaje natural y muchos otros problemas de aprendizaje automático. El proceso de propagación hacia adelante es fundamental para la predicción, ya que determina cómo los datos de entrada se transforman en la salida de la red, permitiendo así el aprendizaje y la generalización a partir de ejemplos vistos durante el entrenamiento.
Enlace Adicional
Para más información, consulte este sitio.
 Campus
Campus
 Campus
Campus
