 Campus
Campus
Diagrama de temas
-
-
¿Qué son las Redes Neuronales Feedforward Profundas?
Las Redes Neuronales Feedforward Profundas son modelos computacionales inspirados en la estructura y funcionamiento del cerebro humano. Estas redes consisten en capas de unidades de procesamiento llamadas "neuronas", que están organizadas en una secuencia lineal de capas: una capa de entrada, una o más capas ocultas, y una capa de salida.
- Capa de Entrada: Recibe los datos de entrada (por ejemplo, una imagen o un texto).
- Capas Ocultas: Procesan los datos realizando cálculos y transformaciones intermedias.
- Capa de Salida: Produce el resultado final del modelo (por ejemplo, una categoría a la que pertenece una imagen).
Funcionamiento Básico
El término "feedforward" se refiere a la forma en que los datos se mueven a través de la red: desde la capa de entrada, pasando por las capas ocultas, hasta llegar a la capa de salida. En cada neurona de una capa, se realiza una operación matemática llamada "activación", que toma las entradas de las neuronas de la capa anterior, las multiplica por ciertos pesos (valores numéricos ajustables), suma un sesgo y luego aplica una función de activación.
Aprendizaje y Entrenamiento
El proceso de entrenamiento de una red neuronal feedforward profunda implica ajustar los pesos y sesgos de las neuronas para minimizar el error entre la salida de la red y la salida esperada. Este ajuste se realiza mediante un algoritmo de optimización conocido como "retropropagación" (backpropagation), que utiliza el descenso del gradiente para actualizar los pesos y reducir el error de manera iterativa.
- Propagación hacia Adelante (Forward Propagation): Los datos de entrada se pasan a través de la red para generar una predicción.
- Cálculo del Error: Se compara la predicción con la salida esperada para calcular el error.
- Retropropagación (Backpropagation): El error se propaga hacia atrás a través de la red, calculando gradientes que indican cómo deben ajustarse los pesos.
- Actualización de Pesos: Los pesos se ajustan utilizando los gradientes calculados, con el objetivo de reducir el error en futuras predicciones.
Funciones de Activación
Las funciones de activación introducen no linealidades en el modelo, permitiendo a la red aprender y representar relaciones complejas. Algunas de las funciones de activación más comunes son:
- Sigmoide: Transforma la salida de una neurona en un valor entre 0 y 1.
- ReLU (Unidad Lineal Rectificada): Transforma la salida en cero si es negativa, o la deja sin cambios si es positiva.
- Tanh (Tangente Hipérbolica): Transforma la salida en un valor entre -1 y 1.
Profundidad y Capacidad de las Redes
La "profundidad" de una red neuronal se refiere al número de capas ocultas que tiene. Las redes más profundas pueden aprender características más complejas y abstractas de los datos, pero también son más difíciles de entrenar. La capacidad de una red se refiere a su habilidad para modelar relaciones complejas y se puede aumentar añadiendo más capas o más neuronas en cada capa.
Ventajas y Aplicaciones
Las Redes Neuronales Feedforward Profundas tienen varias ventajas:
- Capacidad para Modelar Relaciones Complejas: Pueden capturar patrones y relaciones no lineales en los datos.
- Flexibilidad: Se pueden aplicar a una amplia gama de problemas y tipos de datos.
- Mejora con Datos: Su rendimiento mejora con la disponibilidad de más datos y poder de computación.
Algunas aplicaciones prácticas incluyen:
- Reconocimiento de Imágenes: Clasificación de objetos en fotografías.
- Procesamiento de Lenguaje Natural: Traducción automática, análisis de sentimientos.
- Sistemas de Recomendación: Recomendaciones personalizadas de productos y servicios.
Conclusión
Las Redes Neuronales Feedforward Profundas son una herramienta poderosa en el aprendizaje profundo, capaces de abordar problemas complejos mediante la modelación de relaciones no lineales en los datos. Entender su estructura básica, funcionamiento y proceso de entrenamiento es fundamental para adentrarse en el campo del aprendizaje profundo y aprovechar su potencial en diversas aplicaciones.
Enlace Adicional
Para mas información sobre este tema visite este sitio.
-
Introducción a la Regularización en el Aprendizaje Profundo
1. ¿Qué es la Regularización?
- La regularización es una técnica utilizada en el aprendizaje automático para mejorar la capacidad de generalización de un modelo. Esto significa que un modelo no solo debe funcionar bien con los datos de entrenamiento, sino también con datos nuevos y no vistos.
2. Tipos de Regularización:
1. Penalización de Normas de Parámetros:
- L2 Regularización (Decaimiento de Pesos): Agrega un término de penalización proporcional al cuadrado de los pesos del modelo. Ayuda a evitar el sobreajuste al reducir la magnitud de los parámetros del modelo.
- L1 Regularización: Agrega una penalización proporcional al valor absoluto de los pesos. Promueve la "esparcidad" en los parámetros del modelo, haciendo que algunos parámetros sean exactamente cero, lo que puede ser útil para seleccionar características.
2. Métodos de Ensamble:
- Combina múltiples modelos para mejorar la precisión y robustez. Ejemplos incluyen el bagging, boosting y el stacking.
3. Balance entre Bias y Varianza:
- La regularización generalmente aumenta el sesgo (bias) pero disminuye la varianza. Un buen regulador es aquel que logra un equilibrio óptimo, reduciendo la varianza significativamente sin aumentar demasiado el sesgo.
4. Aplicaciones y Prácticas:- La regularización es fundamental en redes neuronales profundas debido a la alta complejidad de estos modelos.
- Es común utilizar técnicas como dropout, que desactiva aleatoriamente neuronas durante el entrenamiento para prevenir el sobreajuste.
Ejemplo de Regularización en Redes Neuronales:- En una red neuronal, se puede aplicar L2 regularización solo a los pesos de las transformaciones afines, dejando los sesgos sin regularizar, ya que estos requieren menos datos para ajustarse correctamente.
Enlace Adicional:
Para más detalles, puedes visitar el capítulo completo sobre regularización en el libro de aprendizaje profundo aquí.
-
Optimization for Training Deep Models
Optimización en IA
La optimización es esencial en el entrenamiento de modelos de aprendizaje profundo. Se refiere al proceso de ajustar los parámetros de una red neuronal para minimizar una función de costo, la cual evalúa el rendimiento del modelo.
Diferencias entre Aprendizaje y Optimización Pura
La optimización en aprendizaje profundo difiere de la optimización pura. En aprendizaje profundo, se optimiza indirectamente una medida de rendimiento sobre un conjunto de prueba, mientras que en la optimización pura se minimiza directamente la función de costo.
Minimización del Riesgo Empírico
La minimización del riesgo empírico consiste en minimizar el error promedio en el conjunto de entrenamiento. Sin embargo, esto puede llevar a sobreajuste, donde el modelo aprende demasiado bien los detalles del conjunto de entrenamiento, perdiendo capacidad de generalización.
Funciones de Pérdida Sustitutas y Parada Temprana
En muchos casos, las funciones de pérdida directas no son optimizables eficientemente. Por ello, se utilizan funciones de pérdida sustitutas, que actúan como proxies pero con ventajas computacionales. La parada temprana se utiliza para detener el entrenamiento antes de que ocurra el sobreajuste.
Algoritmos por Lotes y Minilotes
Los algoritmos de optimización pueden operar en todo el conjunto de datos (batch) o en subconjuntos pequeños (minibatch). Los minilotes balancean precisión y eficiencia computacional, y son ampliamente utilizados en la práctica.
Desafíos en la Optimización de Redes Neuronales
La optimización de redes neuronales enfrenta varios desafíos, como la mala condición de la matriz Hessiana, que puede dificultar el progreso del descenso de gradiente. Otros problemas incluyen el manejo de funciones de costo no convexas, donde el espacio de solución es más complejo y puede contener muchos mínimos locales.
La optimización es una parte crítica del aprendizaje profundo. Abordar los desafíos específicos y utilizar técnicas avanzadas de optimización puede mejorar significativamente el rendimiento de los modelos de IA.
Enlace Adicional
Para más detalles, puedes visitar el enlace completo aquí.
-
Introducción a las Redes Neuronales Convolucionales (Convolutional Neural Networks - CNNs)
Las Redes Neuronales Convolucionales, comúnmente conocidas como CNNs, son un tipo de arquitectura de red neuronal profunda que ha demostrado ser especialmente efectiva para tareas de reconocimiento de imágenes y procesamiento de datos visuales. Aquí se presenta un resumen detallado de los conceptos clave y componentes de las CNNs basados en los temas más relevantes del enlace proporcionado.
¿Qué son las Redes Neuronales Convolucionales?
-Las CNNs son un tipo de red neuronal diseñada para procesar datos con una estructura de cuadrícula, como imágenes. La idea principal detrás de las CNNs es aprovechar la estructura espacial de los datos para extraer características importantes y reducir la dimensionalidad, lo que facilita el aprendizaje y la interpretación de patrones complejos.
Componentes Básicos de una CNN
1. Capas Convolucionales (Convolutional Layers):
- Estas capas son el núcleo de las CNNs. Aplican un conjunto de filtros (o kernels) a la entrada para crear mapas de características (feature maps).
- Cada filtro se desplaza (convoluciona) sobre la entrada, realizando una operación de producto punto y sumando los resultados.
- Los filtros permiten que la red detecte características locales como bordes, texturas y patrones en diferentes partes de la imagen.
2. Funciones de Activación (Activation Functions):
- Después de cada operación de convolución, se aplica una función de activación no lineal como ReLU (Rectified Linear Unit).
- ReLU transforma las salidas convolucionales haciendo que los valores negativos sean cero y manteniendo los valores positivos, lo que introduce no linealidad en el modelo y ayuda a la red a aprender representaciones complejas.
3. Capas de Pooling (Pooling Layers):
- Estas capas reducen la dimensionalidad de los mapas de características combinando los valores en regiones pequeñas (por ejemplo, 2x2).
- El pooling puede ser de diferentes tipos, como max pooling (que toma el valor máximo en cada región) o average pooling (que toma el valor promedio).
- Pooling ayuda a reducir el tamaño de los datos y a hacer la representación más invariante a traslaciones y deformaciones menores en la entrada.
4. Capas Completamente Conectadas (Fully Connected Layers):
- Al final de la red, las capas completamente conectadas (similares a las usadas en redes neuronales tradicionales) toman las características extraídas y las utilizan para realizar la clasificación o regresión.
- Estas capas conectan cada neurona en una capa con todas las neuronas en la siguiente capa, permitiendo la combinación de características para hacer predicciones.
Operaciones Clave en CNNs
Convolución (Convolution):
- La convolución es la operación fundamental donde un filtro se aplica a la entrada para producir un mapa de características.
- Los parámetros del filtro se aprenden durante el entrenamiento, permitiendo que la red ajuste sus filtros para detectar características específicas.
Padding:
- Para controlar el tamaño de las salidas convolucionales, se puede añadir padding (relleno) alrededor de la entrada. Esto asegura que los bordes de la imagen sean considerados en la convolución y permite controlar el tamaño de la salida.
Stride:
- El stride define el paso con el que se mueve el filtro sobre la entrada. Un stride mayor a 1 reduce el tamaño de la salida, mientras que un stride de 1 mantiene una alta resolución en el mapa de características.
Entrenamiento de CNNs
- El entrenamiento de las CNNs sigue el mismo principio general que otras redes neuronales: se utiliza el descenso de gradiente y el algoritmo de backpropagation para ajustar los pesos de los filtros y las conexiones de la red con el objetivo de minimizar la función de pérdida.
Aplicaciones de CNNs
Las CNNs han revolucionado el campo del reconocimiento de imágenes y se utilizan en una amplia variedad de aplicaciones:
- Clasificación de Imágenes: Identificación de objetos y categorías en imágenes.
- Detección de Objetos: Localización y clasificación de múltiples objetos dentro de una imagen.
- Segmentación de Imágenes: División de una imagen en diferentes partes o regiones para analizar objetos individuales.
- Reconocimiento de Caracteres: Lectura automática de texto manuscrito o impreso.
Las Redes Neuronales Convolucionales son una herramienta poderosa y versátil para el procesamiento de datos visuales. Su capacidad para extraer y aprender características relevantes de manera jerárquica las hace ideales para tareas complejas de visión por computadora. Entender los componentes y operaciones clave de las CNNs es esencial para cualquier principiante que desee adentrarse en el campo del aprendizaje profundo y la inteligencia artificial.
Enlace AdicionalPara más información visite este sitio.
-
Redes Neuronales Recurrentes (RNN)
¿Qué son las Redes Neuronales Recurrentes (RNN)?
Las Redes Neuronales Recurrentes (RNN) son un tipo de red neuronal diseñada para procesar secuencias de datos. A diferencia de las redes neuronales tradicionales, que asumen que todas las entradas son independientes entre sí, las RNN tienen conexiones cíclicas que les permiten mantener información sobre las entradas anteriores. Esto las hace ideales para tareas donde el contexto y el orden de los datos son importantes, como el procesamiento de texto, la traducción de idiomas y el reconocimiento de voz.
Estructura de una RNN
La característica distintiva de una RNN es su capacidad para mantener una "memoria" de las entradas anteriores a través de sus conexiones recurrentes. Cada unidad en una RNN no solo toma en cuenta la entrada actual, sino también su propio estado anterior, lo que permite que la red retenga información a lo largo del tiempo.
Una RNN típica se compone de capas de neuronas donde cada neurona recibe una entrada y el estado de la neurona en el tiempo anterior. Esta estructura se puede representar matemáticamente como:
donde:
Propagación hacia atrás a través del tiempo (BPTT)
El entrenamiento de una RNN se realiza mediante un proceso llamado Propagación hacia atrás a través del tiempo (BPTT). Este es un método de retropropagación que tiene en cuenta las dependencias temporales de las secuencias. La idea es descomponer el cálculo de los gradientes a través del tiempo y ajustar los pesos de la red para minimizar el error en cada paso de la secuencia.
Problemas de las RNN
Aunque las RNN son poderosas, enfrentan varios desafíos:1. Desvanecimiento del Gradiente: Durante la BPTT, los gradientes pueden disminuir exponencialmente, lo que dificulta que la red aprenda dependencias a largo plazo.
2. Explosión del Gradiente: Los gradientes pueden crecer exponencialmente, llevando a actualizaciones de pesos inestables.
Para abordar estos problemas, se han desarrollado variantes de RNN, como LSTM (Long Short-Term Memory) y GRU (Gated Recurrent Unit).
LSTM y GRU
LSTM: Las redes LSTM son una versión mejorada de las RNN diseñadas para manejar dependencias a largo plazo. Incorporan "celdas de memoria" que pueden mantener información durante períodos prolongados y mecanismos de "puertas" que controlan el flujo de información dentro y fuera de estas celdas. Las principales componentes de LSTM son:
- Puerta de Entrada: Controla la cantidad de nueva información que se almacena en la celda.
- Puerta de Olvido: Decide cuánta información previa se retiene.
- Puerta de Salida: Determina cuánto de la información de la celda se utiliza para generar la salida.
GRU: Las GRU son similares a las LSTM pero con una estructura más simple. Tienen menos parámetros y son más rápidas de entrenar, aunque son igualmente efectivas en muchos casos. Las GRU combinan la puerta de entrada y la puerta de olvido en una sola "puerta de actualización" y utilizan una "puerta de reinicio" para controlar el flujo de información.
Aplicaciones de las RNN
Las RNN y sus variantes se utilizan en una amplia gama de aplicaciones, incluyendo:
- Procesamiento de Lenguaje Natural (NLP): Traducción automática, generación de texto, análisis de sentimiento.
- Reconocimiento de Voz: Convertir el habla en texto.
- Predicción de Series Temporales: Pronósticos financieros, predicción del clima.
- Video y Visión por Computadora: Análisis de secuencias de video, reconocimiento de gestos.
Las Redes Neuronales Recurrentes son una herramienta poderosa para procesar datos secuenciales y contextuales. A pesar de sus desafíos, las variantes como LSTM y GRU han mejorado significativamente su rendimiento, permitiendo aplicaciones avanzadas en diversas áreas tecnológicas. Entender su funcionamiento básico y sus aplicaciones prácticas es fundamental para aprovechar al máximo estas tecnologías en el campo de la inteligencia artificial y el aprendizaje profundo.
Enlace Adicional:
Para más información visite este sitio.
-
Practical Methodology En Deep Learning
Para aplicar técnicas de deep learning de manera efectiva, no basta con conocer los algoritmos; también es crucial saber cómo elegir el algoritmo adecuado y cómo mejorar un sistema de aprendizaje a partir de la retroalimentación obtenida de los experimentos. Aquí te presento una guía básica basada en las recomendaciones del capítulo sobre Metodología Práctica del libro "Deep Learning":
Definir Objetivos y Métricas de Desempeño:
- Establece los objetivos claros y las métricas de error que guiarán tus acciones futuras.
- Ten en cuenta que en la mayoría de las aplicaciones es imposible alcanzar un error absoluto cero debido a la naturaleza estocástica de los sistemas y la información incompleta en los datos de entrada.
Sistema de Extremo a Extremo:- Desarrolla rápidamente un sistema funcional de extremo a extremo para medir y evaluar métricas de desempeño.
- Instrumenta bien el sistema para identificar cuellos de botella en el rendimiento y diagnosticar si los problemas son debidos a sobreajuste, subajuste o defectos en los datos o el software.
Ajustes Incrementales:- Realiza cambios incrementales basados en hallazgos específicos, como reunir más datos, ajustar hiperparámetros o cambiar algoritmos.
- El enfoque incremental es clave para mejorar el sistema de manera sistemática y eficiente.
Ejemplo de Aplicación: Sistema de Transcripción de Números de Dirección en Street ViewUn ejemplo práctico es el sistema de Google que utiliza redes convolucionales para reconocer números de direcciones en fotos de Street View, mejorando así la base de datos de Google Maps.
Métricas de Desempeño:
- Determina la métrica de error adecuada para tu aplicación, como la precisión o el costo total de errores.
- Usa métricas avanzadas como la curva PR (Precisión-Recuperación) y el F-score cuando sea necesario, especialmente en tareas de clasificación de eventos raros.
Modelos Base Predeterminados:
- Elige el modelo adecuado según la estructura de tus datos. Por ejemplo, usa redes feedforward para vectores de tamaño fijo o redes convolucionales para imágenes.
- Implementa técnicas de regularización desde el inicio, como el abandono (dropout) y la normalización por lotes (batch normalization).
Recolección de Más Datos:
- Evalúa si la obtención de más datos mejorará significativamente el desempeño del modelo. Si el rendimiento en el conjunto de entrenamiento es pobre, primero intenta aumentar la capacidad del modelo antes de recolectar más datos.
- Si el rendimiento en el conjunto de prueba es considerablemente peor que en el de entrenamiento, recolectar más datos suele ser una solución efectiva.
Selección de Hiperparámetros:
- Ajusta manualmente los hiperparámetros entendiendo su relación con el error de entrenamiento, el error de generalización y los recursos computacionales.
- Enfócate en ajustar la tasa de aprendizaje, ya que es uno de los hiperparámetros más importantes.
La metodología práctica en deep learning implica una combinación de elegir el modelo y los algoritmos adecuados, establecer un sistema funcional rápidamente, realizar ajustes incrementales basados en datos empíricos y ajustar cuidadosamente los hiperparámetros. Este enfoque sistemático es esencial para desarrollar aplicaciones efectivas y eficientes en el campo de la IA.Enlace Adicional
Para más detalles, puedes visitar el capítulo completo en Deep Learning Book - Practical Methodology.
-
Aplicaciones del Deep Learning
Como veníamos viendo el aprendizaje profundo (Deep Learning) es una subdisciplina del aprendizaje automático (Machine Learning) que se ha destacado por su capacidad para resolver problemas complejos mediante la utilización de redes neuronales artificiales. Estas redes permiten a las máquinas aprender representaciones de datos en múltiples niveles de abstracción, lo cual es crucial para abordar tareas que tradicionalmente eran difíciles para los sistemas informáticos.Principales Aplicaciones del Aprendizaje Profundo
1. Visión por Computadora
Reconocimiento de Imágenes y Objetos:El aprendizaje profundo ha revolucionado la visión por computadora, permitiendo que las máquinas identifiquen y clasifiquen objetos en imágenes y videos con alta precisión. Esto se logra mediante redes neuronales convolucionales (CNN), que pueden aprender características jerárquicas de las imágenes.
Detección de Objetos:
Además del reconocimiento, las CNN también se utilizan para detectar y localizar objetos dentro de una imagen, como en sistemas de vigilancia y vehículos autónomos.
Segmentación de Imágenes:
Esta técnica va un paso más allá al clasificar cada píxel de una imagen, lo que es útil en aplicaciones médicas para identificar tumores y en la conducción autónoma para reconocer señales y líneas en la carretera.
2. Procesamiento de Lenguaje Natural (NLP)
Traducción Automática:Modelos de aprendizaje profundo, como las redes neuronales recurrentes (RNN) y los transformadores, han mejorado significativamente la traducción entre idiomas al capturar contextos más amplios en el texto.
Análisis de Sentimientos:
Estos modelos también son capaces de interpretar y clasificar el sentimiento detrás de un texto, lo cual es útil para el análisis de opiniones en redes sociales y encuestas.
Generación de Texto:
El aprendizaje profundo permite la creación de texto coherente y contextual, como se observa en chatbots avanzados y asistentes virtuales.
3. Reconocimiento de Voz
Conversión de Voz a Texto:Sistemas como los de Google y Amazon utilizan redes neuronales para transcribir audio a texto, permitiendo comandos por voz y dictado en dispositivos móviles y asistentes personales.
Síntesis de Voz:
La tecnología de texto a voz (TTS) ha avanzado para crear voces artificiales que suenan naturales, usadas en navegación GPS y asistentes virtuales.
4. Sistemas de Recomendación
Las plataformas de entretenimiento y comercio electrónico utilizan modelos de aprendizaje profundo para analizar patrones de comportamiento y proporcionar recomendaciones personalizadas. Estos sistemas pueden sugerir películas, música, productos y más, mejorando la experiencia del usuario.
5. Juegos y Simulaciones
El aprendizaje profundo ha logrado grandes avances en la creación de IA que puede jugar juegos a nivel superhumano. Ejemplos famosos incluyen AlphaGo de Google DeepMind, que venció a campeones mundiales en el juego de Go. Las técnicas utilizadas en juegos también se aplican en simulaciones de entrenamiento para diversas industrias.
6. Salud y Medicina
Diagnóstico por Imagen:Las redes neuronales se utilizan para analizar imágenes médicas y detectar enfermedades como el cáncer. Estas tecnologías pueden superar la precisión de los radiólogos humanos en algunas tareas.
Descubrimiento de Medicamentos:
El aprendizaje profundo ayuda a predecir cómo reaccionarán diferentes compuestos químicos en el cuerpo, acelerando el proceso de desarrollo de nuevos medicamentos.
El aprendizaje profundo ha abierto nuevas fronteras en diversas industrias, mejorando la precisión y eficiencia de tareas complejas. Desde la visión por computadora hasta el procesamiento del lenguaje natural, sus aplicaciones continúan expandiéndose y transformando nuestra interacción con la tecnología. Con el continuo avance en esta área, se espera que el aprendizaje profundo siga proporcionando soluciones innovadoras a problemas que antes eran insuperables.Enlace Adicional
Para más información y detalles sobre estas aplicaciones, puedes visitar Deep Learning Book.
-
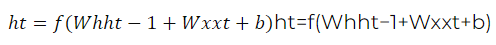
 Campus
Campus
